



{kind=link}
Introduction
We saw the Data Science spectrum in the previous article, Common terminologies used in Machine Learning and Artificial Intelligence, but what do we need in order to enable each stage? That’s where tools and languages come into the picture.
But before that, we need to understand another aspect that comes prior to the spectrum, before your team starts exploring the data and building models, you should define and build a data engine. You need to ask questions like Where is the data being generated? How big is the data, Which tools are required for collecting and storing it? etc.
Note: If you are more interested in learning concepts in an Audio-Visual format, We have this entire article explained in the video below. If not, you may continue reading.
In this article, we’ll focus on the storage side of things. I want to point out here that you don’t need to memorize the tools that you’re going to see but should be aware of what’s out there to answer the questions we asked earlier. And here is the Data Science Spectrum-
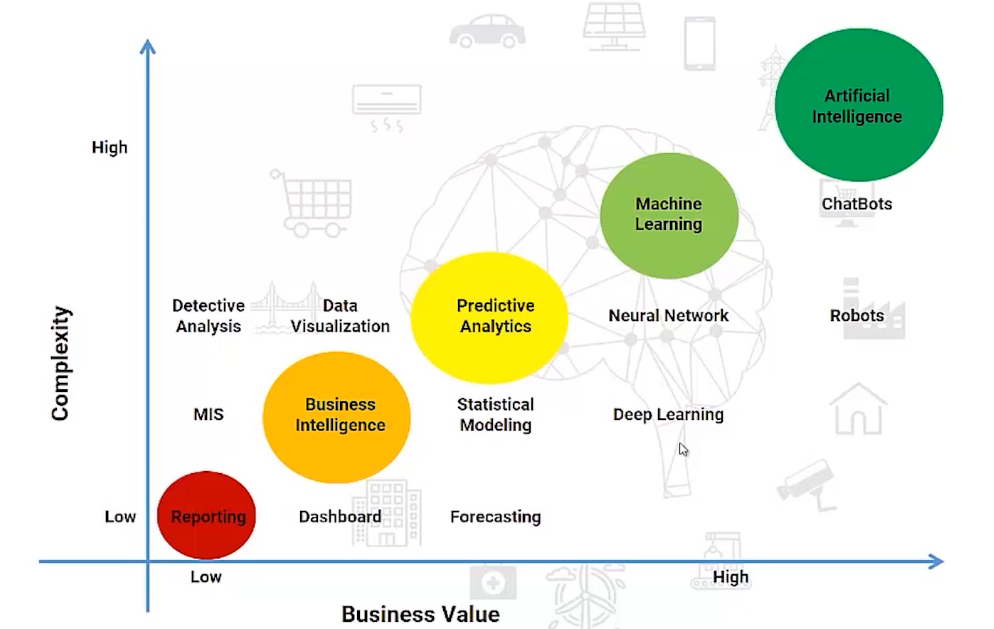
The Data Science Spectrum
The Three V’s of Big Data
We need to understand the characteristics of the data, and we can divide this into three V’s- Volume, Variety, and Velocity. We’ll understand each of these in a bit more detail and cover some of the commonly used tools for each type as well.
The Three V’s- Volume
Let’s look at the first V, Volume.
Volume refers to the scale and amount of data at hand.
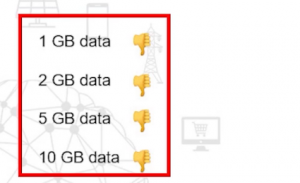
Recall that 90% of the data we see in the world today was generated in the last few years. But we’re decreasing storage and computational costs so collecting and storing huge amounts of data has become far easier. I’m sure all of you must have heard the term Big Data. Well, the volume of data defines if it qualifies as “big data” or not. When we have relatively small amounts of Data Lake, say, 1, 5, or 10 GB, we don’t really need a big data tool to handle this. Traditional tools tend to work well on this amount of data.
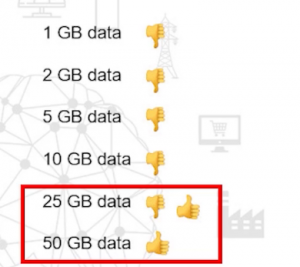
When the data size increases significantly to 25 GB or 50 GB, this is the point when you should start considering big data tools.
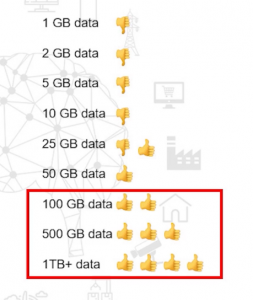
But when the size of the data exceeds, even at this point, you most definitely do need to implement big data solutions. Traditional tools are not capable of handling 500 GB or 1TB of data, no matter how much we might want them to.
So what are some other tools that can handle these different data sizes? Well, let’s look at them.
Tools for handling data of different sizes-

Microsoft Excel
So Excel easily, the most popular and recognizable tool in the industry for handling small datasets. But the maximum number of rows it supports per sheet is 1 million. And one sheet can only handle up to 16,380 columns that are at a time. This is simply not enough when the amount of data is big.

Microsoft Access
Access is another Microsoft tool. Popularly used for data storage. Again, smaller databases up to 2 GB can be stored, but beyond that, simply not possible for Microsoft Access.

SQL is a database management system that has been around since the 1970s. It was a primary database solution for quite a few decades. It’s still popular, but other solutions have emerged. SQL’s main drawback is that it’s very difficult to scale as your database continues to grow.

I’m sure you must have heard of Hadoop. It’s an open-source distributed processing framework that manages data processing and storage for big data. You will more than likely come across Hadoop anytime you build a machine learning project from scratch.

Apache hive is a data warehouse built on top of Hadoop. Hive provides a SQL-like interface to query data, storing various databases in file systems that integrate with Hadoop.
The Three V’s- Variety
The second V we have is Variety, which refers to their different types of data. This can include structured and unstructured data. Under the structured data umbrella, we can classify things like tabular data, employee tables, payout tables, loan application tables, and so on and so forth.
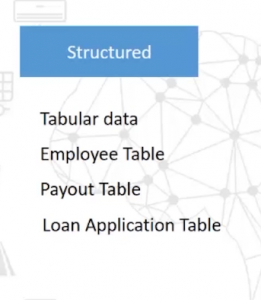
As you might’ve gathered, there’s a certain structure to these data types. But when we swing over to unstructured data, we see formats like emails, social media, which includes your Facebook posts, tweets, etc, customer feedback, video feeds, satellite image feeds among other things.
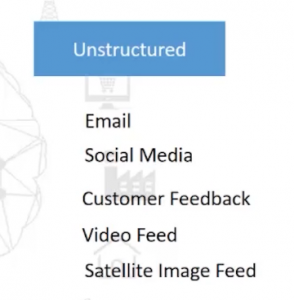
The data stored in these formats do not follow a trend or pattern. It’s huge and diverse and can be quite challenging to deal with.
So what tools are available in the market for handling and storing these different data types? The two most common databases out there are SQL and NO-SQL( Not Only-SQL).
SQL is the market-dominant player for a number of years before NO-SQL emerged. Some examples of SQL databases include MySQL, Oracle SQL, whereas NO-SQL includes popular databases like MongoDB, Cassandra, etc. These NO-SQL databases are seeing huge adoption numbers because of their ability to scale and handle dynamic data, something that SQL struggles with.
The Three V’s- Velocity
The third and final V is Velocity. This is the speed at which data is captured. This includes both real-time and non-real-time capture. But in this article, we’ll focus more on real-time data. This includes Sensor data, which is captured by self-driving cars and CCTV cameras among other things. Self-driving cars need to process data really quickly when they’re on the road. And CCTV cameras of course are popularly used for security purposes and need to capture data points all day long.
Stock Reading is another example of real-time data. Actually, did you know that more than 1TB of trade information is generated during each trade session at the New York stock exchange? That’s the size of real-time data we talking about here, 1TB during each trade session.
Of course, Detecting fraud and Credit card transactions also fall into real-time data processing. And Social media posts and tweets are prime examples for explaining what real-time data looks like. In fact, it takes less than two days for 1 billion tweets to be sent. This is exactly where data storage has become so important in today’s world.
Now let’s look at some of the common tools that captured real-time data for processing.
Kafka is an open-source tool from Apache. it’s used for building real-time data pipelines. Some of the advantages of Kafka are that:
- it’s fault-tolerant
- really quick
- and it’s used in production by a lot of organizations

Another one is Apache Storm. It can be used with almost any programming language. A storm can process over 1 million tuples per second and is highly scalable. It’s a good option to consider for high data velocity.

Amazon’s Kinesis is similar to Kafka, but keep in mind that where Kafka is free, Kinesis comes with a subscription cost. However, Kinesis is offered as an out-of-the-box solution, which is what makes it a powerful choice for organizations.  And Flink is yet another open-source offering from Apache for processing real-time data. High performance, fault tolerance, efficient memory management are some of the advantages of Flink.
And Flink is yet another open-source offering from Apache for processing real-time data. High performance, fault tolerance, efficient memory management are some of the advantages of Flink.
So that was all about the types of data in a few widely used tools associated with them.
End Notes
In this article, we saw some common data capturing types and tools associated with them. We learned about the three V’s of Big Data and also learned about various tools required for handling data with different sizes, different types such as structured or unstructured,d and for real-time data.
If you are looking to kick start your Data Science Journey and want every topic under one roof, your search stops here. Check out Analytics Vidhya’s Certified AI & ML BlackBelt Plus Program
If you have any questions, let me know in the comments section!
I am a data lover and I love to extract and understand the hidden patterns in the data. I want to learn and grow in the field of Machine Learning and Data Science.