



{kind=link}
Introduction
HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process big data. It is a core component of the Apache Hadoop ecosystem and allows for storing and processing large datasets across multiple commodity servers. It provides high-throughput access to data and is optimized for large file transfers, making it a suitable solution for big data storage and processing needs.

HDFS provides several benefits for storing and processing big data:
- Scalable: It is highly scalable, allowing one to store and manage large amounts of data without worrying about running out of storage space. It gives reliability and fault tolerance by replicating data across multiple nodes, reducing the risk of data loss for node failure.
- Cost Effective: It is cost-effective compared to traditional storage and uses less expensive goods than specialized storage systems.
- Fast Data: It provides fast data access and processing speeds, which are crucial for big data analytics applications.
The processing of large datasets in parallel makes good big data processing needs. It is a flexible, scalable, and cost-effective solution for big data storage and processing requirements.
Learning Objectives:
1. Understand what HDFS (Hadoop Distributed File System) is and why it’s important for big data processing.
2. Familiarize yourself with its architecture and its components.
4. See how it is used in various industries, including big data analytics, media, and entertainment.
5. Learn about integrating HDFS with Apache Spark for big data processing.
6. Explore real-world use cases of HDFS.
This article was published as a part of the Data Science Blogathon.
Table of Content
- Understanding HDFS Performance Optimization
- What is the Difference Between HDFS & Other Decentralized File Systems?
- Integrating HDFS with Apache Spark for Big Data Processing
- HDFS Scalability and Handling Node Failures
- Use cases of HDFS in Real-World Scenarios
- Conclusion
Understanding HDFS Performance Optimization
HDFS performance optimization involves several steps to ensure efficient and reliable data storage and retrieval. Some of the key areas where performance includes:
- Cluster Sizing: Properly sizing is critical to ensure good performance. The size should be determined based on the expected data size, the number of concurrent users, and the data access patterns.
- Block Size: The block size used can impact performance. Larger block sizes allow for more efficient data retrieval but in higher overhead for data replication and management.
- Data Replication: It replicates data blocks for fault tolerance. The balance of data availability and performance.
- Disk I/O: The performance can be impacted by disk I/O performance. It is important to use fast disks and to ensure that disks are not overutilized.
- Namenode Memory: The Namenode is the master node that manages metadata about the file system. It is important to allocate enough memory to the Namenode to ensure efficient data management.
Monitoring Regular monitoring of HDFS performance metrics, block replication time, data access latency, and disk I/O ongoing performance optimization.
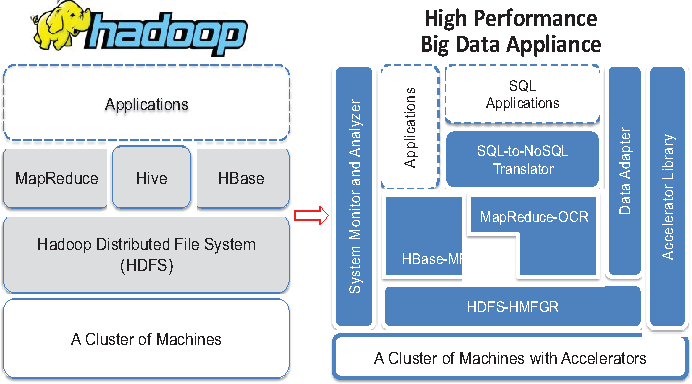
What is the Difference Between HDFS & Other Decentralized File Systems?
This section will discuss the HDFS and other various file systems and identify which one works for you.
Hadoop Distributed File System:
- Designed for large-scale data storage and processing, particularly well-suited for large data sets batch processing
- Master-slave architecture: one node as NameNode to manage metadata, other nodes as data nodes to store actual data blocks
- Supports data replication for data availability and reliability
GlusterFS:
- Designed to provide scalable network-attached storage
- Can scale to petabytes of data
- Client-server architecture with data stored on multiple servers in a distributed manner
Ceph:
- Designed to provide object storage and block storage capabilities
- Uses a distributed object store with no single point of failure
IPFS (InterPlanetary File System):
- Designed to address the problem of content-addressable data storage in a peer-to-peer network
- Uses a distributed hash table (DHT) to store data across nodes in a network
Selection depends on the specific use cases and requirements:
- HDFS for large data processing
- GlusterFS for scalable network-attached storage
- Ceph for distributed object store
- IPFS for content-addressable data storage in a peer-to-peer network.
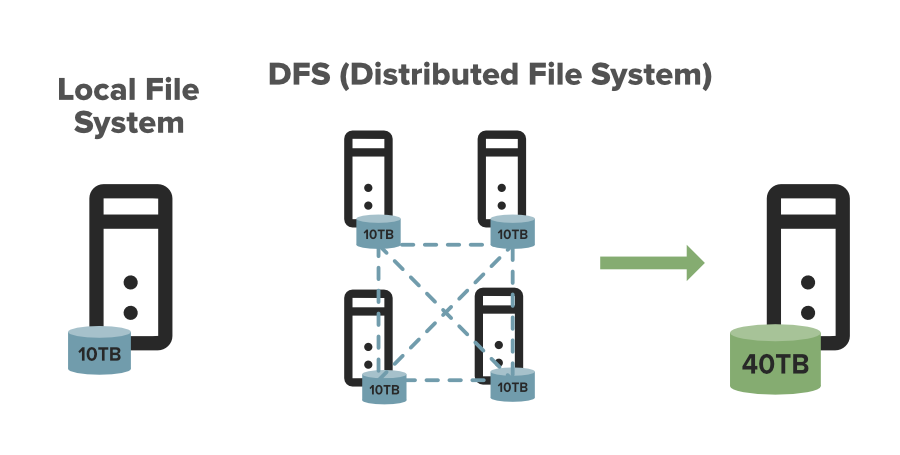
Integrating HDFS with Apache Spark for Big Data Processing
Integrating HDFS with Apache Spark for big data processing involves the following steps:
- Start a Spark Context: A Spark context is the functionality that can be created using Scala’s SparkContext class or Java’s SparkConf class.
- Load the data into Spark: To load the data into Spark, you can use the SparkContext.textFile method in Scala or the SparkContext.textFile path to the data.
Here is an example in Scala that shows to load a text file from HDFS into Spark and perform a word count:
import org.apache. Spark.SparkContext
import org.apache. Spark.SparkContext._
val sc = new SparkContext("local", "word count")
val textFile = sc.textFile("hdfs://:/path/to/file.txt")
val counts = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://:/path/to/output")
sc.stop()
HDFS Scalability and Handling Node Failures
HDFS scalability refers to the ability to handle increasing amounts of data and users over time. The following are ways it can handle scalability:
- Horizontal Scaling: It can be scaled horizontally by adding more nodes to handle increasing amounts of data.
- Data Replication: It uses data replication to ensure availability even in node failures. By default, it replicates each data block three times, providing data redundancy and reducing the risk of data loss.
- Federation: Its federation allows multiple independent HDFS namespaces for multiple applications to share, allowing for further scalability.
Handling node failures in HDFS involves the following steps:
- Detection of Node Failure: HDFS uses Heartbeats and Block reports to detect node failures. The NameNode periodically receives heartbeats from the DataNodes, and if it does not receive a heartbeat from a DataNode for a long time, the DataNode has failed.
- Re-replication of Data: HDFS automatically re-replicates data from failed nodes to other nodes in data availability, even in node failures.
- Removal of Dead Nodes: The NameNode periodically checks for dead nodes, removes them from up resources, and ensures that they remain balanced.
- Automatic Failover: HDFS supports automatic failover of the NameNode, allowing continued functioning even in a NameNode failure.

Use cases of HDFS in Real-World Scenarios
Below are some real-world use cases of the HDFS System
- Big Data Analytics: It is used in big data analytics to store and process large amounts of data. For example, companies may use HDFS to store and process customer data, and shopping behavior, to gain insights into consumer preferences and make data-driven decisions.
- Media and Entertainment: It is used in the media and entertainment industry to store and process large amounts of multimedia content, audio, and images. For example, video streaming services may use HDFS to store and distribute video content to millions of users.
- Healthcare: It is used in the healthcare industry to store and process large amounts of patient data and lab results. For example, hospitals may use it to store and process patient data to support personalized medicine and improve.
- Financial Services: It is used in the financial services industry to store and process large amounts of financial data, such as stock prices, trade data, and customer information. For example, banks may use HDFS to store and process financial data to support real-time decision-making and risk management.
- Government and Public Sector: It is used in the government and public sector to store and process large amounts of data, such as census data, social media data, and satellite imagery. For example, government agencies may use HDFS to store and process data to support decision-making and improve public services.
Conclusion
In conclusion, HDFS continues to be a popular system for storing and processing big data. The Apache Hadoop ecosystem, of which HDFS is a part, continues to evolve and improve tools and technologies for data storage and processing. In the future, HDFS and the Apache Hadoop ecosystem will continue to play a critical role in the world of big and innovative ways to store and process large amounts of data to support decision-making and drive advancements in the Apache Hadoop ecosystem. HDFS will continue to be a key player in big data for years to come.
Major takeaways of this article:
1. Firstly, we have discussed what an HDFS database is and its main benefits.
2. Then, we discussed some tips and tricks for optimizing the performance of HDFS, like Cluster Sizing, Block Sizing, or Data Replication.
3. After that, we discussed how to handle node failures in HDFS and make it scalable. Also discussed some other decentralized file storage systems.
4. Finally, we discussed how to integrate HDFS in Apache for big data processing and then discussed real-world use cases.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.