



{kind=link}
Introduction
Apache Kafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a famous Scala-coded data processing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time. It is a message broker application and a logging service that is distributed, segmented, and replicated. Kafka is a popular and growing technology that offers IT professionals ample job opportunities. In this guide, we have discussed the detailed Kafka interview questions that can help you to ace your upcoming interview.

Source: docs.confluent.io
Learning Objectives
After reading this interview blog thoroughly, we’ll learn the following:
- A common understanding of what Apache Kafka is, its role in the technical era, and why it is needed when we have tools like RabbitMQ.
- Knowledge of Apache Kafka workflow along with different components of Kafka.
- An understanding of Kafka security, APIs provided by Kafka, and the concept of ISR in Kafka.
- An understanding of leader, follower, and load balancing in Kafka.
- Insights into some frequently used Kafka commands like starting the server, listing the brokers, etc.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- Kafka interview questions and Answers
- Q1. Is it possible to use Apache Kafka without a ZooKeeper?
- Q2. Apache Kafka can receive a message with what maximum size?
- Q3. Explain when a QueueFullException occurs in the Producer API.
- Q4. To connect with clients and servers, which method is used by Apache Kafka?
- Q5. For any topic, what is the optimal number of partitions?
- Q6. Write the command used to list the topics being used in Apache Kafka.
- Q7. How can you view a message in Kafka?
- Q8. How can you add or remove a topic configuration in Apache Kafka?
- Q9. Tell the daemon name for ZooKeeper.
- Q10. In Kafka, why are replications considered critical?
- Q11. Why choose Kafka over other messaging services like JMS and RabbitMQ?
- Q12. Explain the four components of Kafka Architecture.
- Q13. Mention the APIs provided by Apache Kafka.
- Q14. Explain the importance of Leader and Follower in Apache Kafka.
- Q15. How to start the Apache Kafka Server?
- Q16. What is the difference between Partitions and Replicas in a Kafka cluster?
- Q17. Explain the ways to list all the brokers available in the Kafka cluster.
- Q18. What rules must be followed for the name of a Kafka Topic?
- Q19. Explain the purpose of ISR in Kafka.
- Q20. Explain load balancing in Kafka.
- Conclusion
Kafka interview questions and Answers
Q1. Is it possible to use Apache Kafka without a ZooKeeper?
No, we can’t bypass the ZooKeeper and connect directly to the Kafka Server, and even we can’t process the client requests if the Zookeeper is down due to any reason.
Q2. Apache Kafka can receive a message with what maximum size?
The default maximum size for any message in Kafka is 1 Megabyte, which can be changed in the Apache Kafka broker settings but the optimal size is 1KB because Kafka handles very small messages.

Source: dattell.com
Q3. Explain when a QueueFullException occurs in the Producer API.
In the producer API, when the messages sent by the producer to the Kafka broker are at a pace that the broker can’t handle, the exception that occurs is known as QueueFullException. This exception can be resolved by adding more brokers so that they can handle the pace of messages coming in from the producer side.
Q4. To connect with clients and servers, which method is used by Apache Kafka?
Apache Kafka uses a high-performance, language-agnostic TCP protocol to initiate client and server communication.

Source: kafka.apache.org
Q5. For any topic, what is the optimal number of partitions?
For any Kafka topic, the optimal number of partitions are those that must be equal to the number of consumers.
Q6. Write the command used to list the topics being used in Apache Kafka.
Command to list all the topics after starting the ZooKeeper:
bin/Kafka-topics.sh --list --zookeeper localhost:2181Q7. How can you view a message in Kafka?
You can view the message in Apache Kafka by executing the below command:-
bin/Kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginningQ8. How can you add or remove a topic configuration in Apache Kafka?
To add a topic configuration:
bin/Kafka-configs.sh --zookeeper localhost:2181
--topics --name_of_the_topic --alter --add-config a=bTo remove a topic configuration:
bin/Kafka-configs.sh --zookeeper localhost:2181
--topics --name_of_the_topic --alter --delete-config aNote:- Here, a denotes the particular configuration key that needs to be changed.
Q9. Tell the daemon name for ZooKeeper.
The Zookeeper’s daemon name is Quorumpeermain.
Q10. In Kafka, why are replications considered critical?
Replications are considered critical in Kafka because they ensure that every published message must not be lost and should be consumed in any program/machine error.
Q11. Why choose Kafka over other messaging services like JMS and RabbitMQ?
Although we have many traditional message queues, like JMS and RabbitMQ, Kafka is a key messaging framework for transmitting messages from sender to receiver. When it comes to message retention, traditional queues eliminate messages as soon as the consumer confirms them, but Kafka stores them for a default period of 7 days after the consumer has received them.
Also, nowadays, we have to deal with transactional data like online shopping carts, orders, and inventory, which are augmented with things such as one-click go, likes, web searches, and recommendations. This data must be analyzed carefully to predict consumer behavior and feed it to the predictive engines. So, we need smooth messaging services to process this transactional data and handle the large volume of messages for smooth delivery.

Source: axual.com
Below are the key points to prove why we can rely on Kafka even though we have many traditional services:-
1. Reliability: Kafka ensures reliable message delivery with zero message loss from a publisher to the subscriber. It comes with a checksum method to verify the message integrity by detecting the corruption of messages on the various servers, which is not supported by any traditional method of message transfer.
2. Scalability: Kafka can be scaled out by using clustering along with the zookeeper coordination server without incurring any downtime on the fly. Apache Kafka is more scalable than traditional message transfer services because it allows the addition of more partitions.
3. Durability: Kafka uses distributed logs and supports message replication to ensure durability. As we see above, RabbitMQ deletes messages as soon as it transferred to the consumer. This will cause performance degradation, but in Kafka, messages are not deleted once consumed; it keeps them by the retention time.
4. Performance: Kafka provides fault tolerance(resistance to node failures within a cluster), high throughput(capable of handling high-velocity and high-volume data), and low latency(handles the messages with a very low latency of the range of milliseconds) across the publish and subscribe applications. Mostly the traditional services face a decline in performance with a rise in the number of consumers, but Kafka does not slow down with the addition of new consumers.
Q12. Explain the four components of Kafka Architecture.
The 4 significant components of Kafka’s Architecture include:

Source: www.projectpro.io
1. Topic: A Topic is nothing but a feed or a category where records are stored and published. Topics in Kafka play a major role in organizing all the Kafka records by offering the reading facility to all the consumer apps and writing to all the producer applications. For the duration of a configurable retention period, the published records remain in the cluster.
2. Producer: A Kafka producer is nothing but a data source for one or more Kafka topics used to optimize, write, and publish the messages in the Kafka cluster. Kafka producers are capable of serializing, compressing, and load-balancing the data among brokers with the concept of partitioning.
3. Consumer: Consumers in Kafka can read the data by reading messages from topics they have subscribed to. Consumer works in a grouping fashion; they got divided into multiple groups where each consumer in a specific group with respect to a subscribed partition will be responsible for reading a subset of the partitions.
4. Broker: The cluster of Kafka is made up of multiple servers, typically known as Kafka brokers, which work together to offer reliable redundancy, load balancing, and failover. Kafka brokers use Apache ZooKeeper to manage and coordinate the cluster. Each broker in Kafka is assigned an ID and behaves as; in-charge of one or more topic log divisions. Every broker instance can also handle the read and writes volumes of hundreds of thousands of messages per second without sacrificing performance.
Q13. Mention the APIs provided by Apache Kafka.
Apache Kafka offers four main APIs-
1. Kafka Producer API: The producer API of Kafka enables applications to publish messages to one or more Kafka topics in a stream-of-records format.
2. Kafka Consumer API: The consumer API of Kafka enables applications to subscribe to multiple Kafka topics and process streams of messages that are produced for those topics by producer API.
3. Kafka Streams API: The streams API of Kafka enables applications to process data in a stream processing environment. For multiple Kafka topics, this streams API allows applications to fetch data in the form of input streams, process the fetched streams, and at last, deliver the output streams to multiple Kafka topics.
4. Kafka Connector API: As the name suggests, this API helps connect applications to Kafka topics. Also, it offers features for handling the run of producers and consumers along with their connections.
Q14. Explain the importance of Leader and Follower in Apache Kafka.
The concept of leader and follower is very important in Kafka to handle load balancing. In the Kafka server, every partition has one server that plays the role of a leader and one or more servers that behaves as followers. The leader’s responsibility is to perform all the read-and-write data operations for a specific partition, and the follower’s responsibility is to replicate the leader.

Source: tutorialspoint.com
In any partition, the number of followers varies from zero to n, which means a partition cannot have a fixed number of followers; rather, it can have zero followers, one follower, or more than one follower. The reason for the same is if there is any failure in the leader, then one of the followers can be assumed to be in leadership.
Q15. How to start the Apache Kafka Server?
Follow the below steps to start the Apache Kafka server on your personal computers:-
Step 1: To download the latest version of Apache Kafka(3.4.0), first click on the below site and download the software as per your operating system, and once it gets downloaded, extract the file to perform the installation process.
Link- Click here
Step 2: To run Kafka, you must have Java 8+ version installed on your local environment.
Step 3: Now you have to run the below commands in the same order to start the Kafka server:
Firstly you have to run this command to start the ZooKeeper service:
$bin/zookeeper-server-start.sh config/zookeeper.propertiesThen you need to open another terminal and run the below command to start the Kafka broker service:
$ bin/Kafka-server-start.sh config/server.propertiesQ16. What is the difference between Partitions and Replicas in a Kafka cluster?
The major difference between Partitions and Replicas in the Kafka cluster is that the Partitions are used to increase the throughput in Kafka. In contrast, Replicas are used to ensure fault tolerance in the cluster. Basically, in Kafka, partitions are nothing but topics divided into parts to enable consumers to read data from servers in parallel. The responsibility of the read and write operations are managed on a single server called the leader for that partition. That leader is followed by zero or more followers, where replicas of the data will be created.

Source: sookocheff.com
Replicas are nothing but copies of the data in a specific partition. The followers have just to copy the leaders; they’re not required to read or write the partitions individually.
Q17. Explain the ways to list all the brokers available in the Kafka cluster.
We have the below two possible ways to list out all the available Kafka brokers in an Apache Kafka cluster:
- By using zookeeper-shell. sh
zookeeper-shell.sh:2181 ls /brokers/idsWe will get the below output after running this shell command:
WATCHER:: WatchedEvent state: SyncConnected type: None path: null [0, 1, 2, 3]
This shows the availability of four alive brokers – 0,1,2 and 3.
- By using zkCli.sh
First, we need to log in to the ZooKeeper client
zkCli.sh -server:2181
Now we have to run the below command to list all the available brokers:
ls /brokers/idsQ18. What rules must be followed for the name of a Kafka Topic?
To name the topics in Apache Kafka, there are some legal rules which are defined by Kafka to be followed:-
The maximum length of the name of any Kafka topic is 255 characters (including symbols and letters). In Kafka version 0.10, this length has been reduced from 255 to 249.
We can use special characters like. (dot), _ (underscore), and – (hyphen) in the name of a Kafka topic. Although we must avoid combining these special characters because the topics with a dot (.) and underscore ( _) symbol could cause some confusion with internal data structures.
Q19. Explain the purpose of ISR in Kafka.
ISR stands for in-synch replicas. It refers to all the replicated partitions of Kafka that are fully synced up with the leader within a configurable amount of time. Basically, a defined period of time is given to followers to catch up with the leader; by default, this time is 10 seconds; after that, the leader will continue the writing on the remaining replicas in the ISR by dropping the follower from its ISR. If the follower revisits the ISR, it has to truncate its log to the last point, which was checked, and after reaching the last checkpoint from the leader, it will catch up on all the messages. The leader will add it back to the ISR only when the follower completely catches up with the leader.
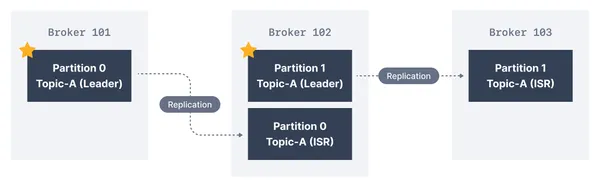
Source: conduktor.io
Q20. Explain load balancing in Kafka.
We have the leader and follower nodes to ensure the load balancing in the Apache Kafka server. As we already discussed, the role of leader nodes is to do the writing/reading of data in a given partition. In contrast, follower systems perform the same task in passive mode to ensure data replication across different nodes. So that if any failure occurs due to any reasoning system or software upgrade, the data remains available.
Whenever the leader system fails or goes down for any reason, irrespective of any internal outage, the follower system is responsible for data persistence by becoming the new leader. Like a load balancer distributes loads across multiple systems in a caseload, Kafka replicates messages on multiple systems. When the leader system goes down, the other follower system becomes the leader to ensure the availability of data to subscribers’ systems and balance the loads.
Conclusion
This blog on interview questions covers most of the frequently asked Apache Kafka interview questions that could be asked in data science, Kafka developer, Data Analyst, and big data developer interviews. Using these interview questions as a reference, you can better understand the concept of Apache Kafka and start formulating practical answers for upcoming interviews. The key takeaways from this Kafka blog are:-
1. Apache Kafka is a popular publish-subscribe messaging application written in Java and Scala, which offers low latency, extensive throughput, and a unified real-time platform to handle the data.
2. Although we have many traditional message queues like JMS or RabbitMQ, Kafka is irreplaceable because of its reliability, scalability, performance, and durability.
3. Kafka can balance the loads even in odd conditions like an internal outage, software upgrades, etc., with the help of the leader-follower concept.
4. Kafka ensures three-step security, including encryption, authentication, and authorization to prevent data from fraudsters.
I hope you liked my interview questions guide. If you have more questions or suggestions, please post them in the comments below.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.