



{kind=link}

Introduction
Natural Language Processing or NLP is a field of linguistics and deep learning related to understanding human language. NLP deals with tasks such that it understands the context of speech rather than just the sentences.
Some common tasks in Natural language Processing include:
- Text Classification: Classification of whole text into classes i.e. spam/not spam etc
- Text Generation: Generating text or autocomplete with generated text etc
- Sentiment Analysis: Analysing the sentiment of the text i.e. positive/Negative, toxic/non-toxic etc
- Language Translation: Translating text into different languages etc
The applications of NLP isn’t just limited to text but has a wide range of applications in speech recognition, conversational AI, computer vision etc
The Transformers architecture introduced in the paper “Attention Is All You Need”, has changed the scenario of creating more complex and advanced NLP models.
The transformers architecture consists of encoder and decoder models which work together to generate meaningful results.
- Encoder: The encoder model builds a representation/features of the input such that it acquires understanding and meaning from the given input text. It is optimized to get feature representation from the inputs. Examples: BERT, DistilBERT, RoBERTa etc
- Decoder: The decoder model uses the encoder’s representation with other inputs to perform generation tasks. Usually, decoder models are good Language models i.e. used to generate the next word from given input text. Examples: GPT, GPT-2, Transformer-XL etc
Hence this architecture can be used to train models to solve almost any kind of NLP task as mentioned above.
Now let’s dive into the Transformers Library by HuggingFace.
To proceed with the tutorial, a Jupyter Notebook with a GPU is recommended. The same can be accessed through Google Colaboratory which provides a cloud-based jupyter notebook environment with a free Nvidia GPU.
Transformers Library
The HuggingFace Transformers Library consists of thousands of pre-trained models which are trained on huge datasets for thousands of GPU hours and made available to us such that we can use it or fine-tune it for our specific applications.
The ModelHub consists of various pre-trained models for different tasks which can be downloaded and used easily. It also supports Hosted Inference API such that we can directly enter the input text and get the output.
Now let’s get started by installing the transformers library,
Installation
If you are using a jupyter notebook then, run this command in the cell to install transformers library,
To install the library in the local environment, follow this link.
Before we get started, create an HuggingFace account to access models from ModelHub and many other objects.
Pipeline API
The pipeline API is a high-level API that performs all the required steps i.e. preprocessing of inputs, getting model predictions and performing post-processing of outputs. This API allows us to directly input any text and get an intelligible answer.
It supports a variety of NLP tasks, some being:
- Sentiment Analysis: Classifying input sentences as positive or negative
- Feature Extraction: Getting vector representation of the input
- Question Answering: Answering questions given the context
- Summarization: Getting the summary given the input text. etc…
Now let’s look at some of the tasks that the Pipeline API support
Sentiment Analysis
First, let’s import the pipeline API,
from transformers import pipeline
Now let’s create a classifier object for the sentiment analysis task,
classifier = pipeline('sentiment-analysis')
When the above code is executed, the pipeline API selects a particular pre-trained model that has been fine-tuned for sentiment analysis in English. This model is downloaded and cached when you create the classifier object. Hence if you rerun the above command, the cached model will be loaded instead of downloading it.
We can check which model our classifier object is using by,
classifier.model.name_or_path
Output:

The output of the model gives the name of the model. In the above case, the classifier selects a type of bert model. You can search for this model in the ModelHub for more information.
Now let’s perform some inferences by passing an input sentence into the model,
classifier("I am really excited about about today !! ")
Output:

We can see that the classifier classifies the input sentence as a POSITIVE sentence with almost 100% confidence.
Now let’s try using the classifier to classify more than one inputs,
classifier(["I am very excited for this new movie !!",
"I not very unhappy",
"I hate this weather !!",
"I really hate that movie.."])
Output:

We can see that the classifier has classified the sentiment of the sentences correctly with really good confidence.
Task: Just play around by entering different inputs and see how the model behaves…
Zero-Shot Classification
In Zero-Shot Classification the input texts are not labelled and we can define the labels according to our needs. Hence we don’t need to rely on the labels of the pre-trained model it has been trained on.
Let’s check some examples,
from transformers import pipeline
classifier = pipeline('zero-shot-classification')
While entering inputs, we should also specify the relevant labels for the model to classify,
classifier(
["This is a course about the Transformers library",
"This App can generate more than 100 million in revenue",],
candidate_labels=["education", "politics", "business"],
)
Output:

We can see that we have decided on the labels i.e. education, business and politics and the model was able to classify the sentence based on given inputs i.e. the model returns the probabilities of the classes which we have entered. It is 85% confident that the first sentence is about education and almost 99% sure that the second sentence is about business.
Task: Just play around by entering different sequences and labels and check how the model behaves…
Text Generation
This is one of the most exciting tasks i.e. generating text provided the initial prompt and model with auto-complete by generating the remaining text. Also, text generation involves some randomness and hence the results might not match exactly.
from transformers import pipeline
generator = pipeline('text-generation')
Let’s give a prompt and specify the num_return_sequences argument to define the number of sentences to be generated and the max_length argument to define the maximum length of generated sentence.
results = generator("I am really happy because ",
num_return_sequences=2,
max_length=30)
Let’s check the result,
for i in results:
print(i['generated_text'])
print('n')
Output:

Task: Play around to generate some sentences by giving different prompts and changing max_length or num_return_sequences…
Question Answering
The question answering pipeline answers questions using the information given the context.
from transformers import pipeline
question_answerer = pipeline("question-answering")
Give the inputs in the following format,
question_answerer(
question = "What is the capital of India ?",
context = """India, officially the Republic of India, is a country in South Asia.
It is the second-most populous country, the seventh-largest country by land area, and the most populous democracy in the world.
The capital is New Delhi"""
)
Output:
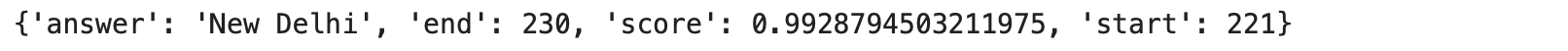
We can see that the answer is extracted from the context and it is not generated.
Task: Try giving different contexts and questions to understand better…
Summarization
The Summarization pipeline API generates the summary of the given input text while keeping most of the important aspects in the referenced text.
from transformers import pipeline
summarizer = pipeline('summarization')
We should enter the input text along with max_length or min_length argument for text/summary generation.
summarizer("""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
""")
Output:

There are many more tasks that can be done using pipeline API like
- Text Translation
- Named Entity Recognition
- Mask Filling etc
We have seen that the pipeline object automatically chooses a particular pre-trained model. Now finally let’s see that we can also define/choose the model to be defined in the pipeline API.
Task: Play around to generate some summaries of text and try using min_length/max_length.
Using any Model from Hub in Pipeline
We can specify the model which is being used in the pipeline by specifying the name of the model in the model argument while initialising the pipeline object. We can choose from any model for the particular task from ModelHub.
For example, if we are initialising pipeline object for text generation, then choose the Text Generation task from the Tasks menu on the left-hand side of Model Hub. Then choose a model from the list displayed.
Let’s create a text generation pipeline object by using the GPT2 model
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
To verify we can check the model by following,
generator.model.name_or_path
Output:

Hence, our pipeline object is using model ‘gpt2’
Conclusion
As we have seen how immensely popular and powerful pre-trained models can be used on a plethora of NLP tasks, we can realise that there is very high potential in creating/training models for our own applications by fine-tuning them on our custom datasets. Thus enabling AI to become an integral part of daily applications.
References:
Link for the above colab notebook: Link
About the Author:
I’m Narasimha Karthik, Deep Learning Practioner.
Currently working with Computer Vision and NLP. Experience in working with PyTorch, Fastai, Tensorflow and Keras frameworks. You can contact me through LinkedIn and Twitter for any projects or discussions. Link of this blog in Github.
Thank you
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.