



This year’s World Cup in Russia was the most watched sporting event in history. GlobalWebIndex reports that up to 3.4 billion people – around half of the world’s population – watched some part of the tournament.
As with past World Cups, a global prediction market emerged allowing spectators to bet on match results – from early matchups to the tournament’s final winner. And while the prophecies of supposedly-psychic animals garnered the most headlines, economists and data scientists were hard at work setting their algorithms to the task of predicting the Cup’s results.
But how did they fare? Very poorly, it turns out.
Investment Banks
It’s become a tradition among large investment banks to attempt to forecast the World Cup winner. Apart from the fun element, one might assume that a bank’s ability to predict the top team bodes well for its ability to pick the right investments. Unfortunately, the major banks have a remarkably bad record in soccer forecasting.
Goldman Sachs’ forecast combined team level data with player characteristics to build “200,000 probability trees, and 1 million simulations” of the entire tournament. Although the specifics of its model have been kept secret, it may have veered more towards conventional statistics as opposed to machine learning. Nevertheless, the bank’s prediction failed rather spectacularly.
Its first iteration heralded a Germany-Brazil final resulting in a Brazil victory. In reality, Germany was knocked out in the group stage after losing to Mexico and South Korea, and Brazil fell in the quarter final to Belgium. On July 9th (just before the semi-final matches) Goldman Sachs updated its model to suggest a Belgium-England final, with Belgium the winner. Thus, of the four possible teams that could have been in the final at that point, it predicted the exact two that failed to get there.
Goldman Sachs’ wasn’t the only model that fell short. Other investment banks, including ING, UBS, and Australia’s Macquarie, also produced wildly incorrect predictions. Only the Japanese bank Nomura seems to have correctly predicted a French victory, using a “portfolio-based” approach. Whether Nomura’s success actually represents predictive prowess as opposed to blind luck, however, is certainly up for debate (after all, with so many competing predictions, somebody had to get it right).

{kind=link}
The 32 Teams of the 2018 FIFA World Cup in Russia
Academia
A number of academic teams also took to the task of analyzing the World Cup, in some cases using machine learning to foretell the winner. For example, a team of German researchers at the Technical University of Dortmund used a random forest approach for the task, calculating the outcome of many different randomly generated branches (in this case matches) and averaging them to make a prediction.
On the surface, this approach presents clear advantages over others, like Goldman Sachs’ (apparent) decision tree method. Most notably, decisions trees trained on sparse historical data (as with events like the World Cup) are highly vulnerable to overfitting, or an over-reliance on ostensible patterns in the data that actually represent random noise. On the other hand, random forest averages the results of many randomly selected matches, making it less prone to the overfitting risk stemming from limited historical data. In addition, the Dortmund team seems to have incorporated more data into their model, with information ranging from the economic factors of the teams’ countries to the average age of their players.
Yet even with this more sophisticated approach, the academics’ predictions also fell short. The Dortmund team envisioned a Brazil-Germany winner, with a 64% chance of a German triumph.
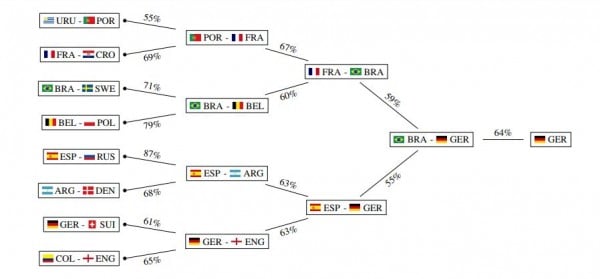
Chart from ‘Prediction of the FIFA World Cup 2018 – A random forest approach with an emphasis on estimated team ability parameters’ by Andreas Groll, Christophe Ley, Gunther Schauberger, and Hans Van Eetvelde
Data in Sports Predictions
As it turns out, soccer is one of the most difficult sports to predict accurately, even with data-driven approaches. Several studies have shown that soccer has among the highest “upset” rates of all popular team sports, an effect that seems to gain confirmation from off-the-cuff analysis by internet statisticians. For example, when a Quora user named Martin Hum analyzed money-line odds data from popular sports betting sites he was able to calculate the rates of successful prediction for a number of major sports:

So what makes soccer so hard to predict? Here are a few possible explanations:
Ties and penalties
Holding everything else equal, predictability decreases when the number of possible outcomes increases. So the possibility of a tie in soccer means that the a priori probability of a correct prediction is ⅓ versus the ½ chance in other sports like tennis and baseball. While it’s true that this effect only applies to the World Cup during the group stage (before games go to overtime or penalties to decide the winner), it still puts predictive models at a disadvantage when trying to foresee the entire tournament. And when ties are decided by penalty shootouts in the knockout rounds, the picture may be even more complicated. That’s because success in penalties may have more to do with psychological or circumstantial differences between teams than it does with strength or ability, injecting additional kinds of randomness. Interestingly, the only sport which had a lower rate of successful prediction than soccer in Hum’s analysis was ice hockey, which also incorporates penalty-style tiebreakers.
Low-scoring
High-scoring sports may be more likely to expose strength differences among competitors. Probabilistically, if we imagine every scoring opportunity as a trial, then as the number of trials increases, the law of large numbers starts to show, creating a scoreline to reflect the “true” strength differential among the teams. In layman’s terms, this just means that stronger teams will prevail when they have more opportunities to show their strength. The converse is to say that low-scoring sports, like soccer, are more conducive to upsets. Some might point to Spain’s match against Russia in this World Cup as a prime example, when the #10 ranked Spaniards fell to the #70 ranked home team in penalties following a 1-1 tie.
Small samples
The World Cup only happens once every 4 years, with just 21 taking place since the first one in Uruguay in 1930 (two were skipped due to the Second World War). In the tournament, even the teams that make it all the way to the final play only 7 games in total, with half the teams knocked out after just 3 matches. Adding to the difficulty, the time spans between the tournaments mean that a country’s team can change radically from Cup to Cup. Contrast that to a sport like basketball, where the exact same starting 5 players can win the NBA championship for several years consecutively. All this adds up to the fact that the sample sizes for World Cup soccer teams are small, not only in absolute terms, but especially in terms of particular squads. True, a model might incorporate data from players’ professional careers outside of the World Cup, but as we’ve seen, these approaches have demonstrated limited success.
Undoubtedly, the same factors that make soccer unpredictable are the ones that make it so exciting to billions around the world. But that doesn’t mean that data scientists should give up trying to predict the World Cup’s outcome. I myself and many others will look forward to the novel approaches that data scientists and AI experts come up with for the 2022 World Cup in Qatar, and especially the 2026 World Cup in Mexico-USA-Canada, when the number of teams will increase from 32 to 48. But for now, the “psychic” animals won’t have to worry about losing their jobs.