


First of all, I would like to point out that the skill of building MVP and microservices for a data scientist is extremely useful! When you can build a prototype and test it in a working environment it just feels so much better and allows you to better understand your final product.
There is a famous Venn diagram made by Drew Conway where hacker skills refer to programming skills. So according to this diagram programming skills are important for data science in general and for a data scientist particularly.
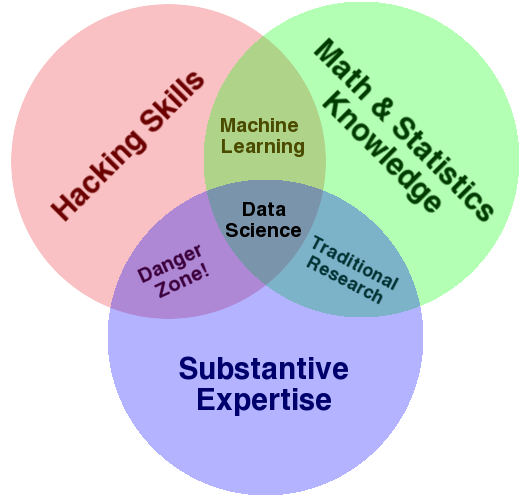
For disclaimer: I don’t think that Data Scientist should build production-ready systems from the ground up, this is work for professional backend developers.
Right, so programming skills are important, what next?
The first thing a data scientist needs is data. Twitter is a treasure trove of data that is publicly available. It’s a unique data set that anyone can access. There are plenty of studies that showed the predictive power of Twitter sentiment.
Here are some examples:
Practical project
Practical project for this weekend is building a microservice that can collect Twitter Data and perform some basic sentiment analysis.
Source code can be found in my repository
What it does:
- It receives POST request with the instruction of which Twitter it needs to collect
- Then it opens the socket connection with Twitter API and starts to receive real-time Twitter data
- Each tweet assigned with it sentiment score with help of TextBlob
- All data then goes to PostgreSQL database
Main features:
- Because it uses Nameko and RabbitMQ, you can asynchronously run many different tasks and collect different topics.
- Because it is based on Flask, you can easily connect this with other services that will communicate with this service by POST requests
- For each tweet, the service assigns sentiment score using TextBlob and stores it to the PostgreSQL, so latter you can perform analysis on that.
- It scalable and expandable — you can easily add other sentiment analysis tools or create visualization or web interface because it is based on Flask
Example of POST request json
{
"duration": 60,
"query": ["Bitcoin", "BTC", "Cryptocurrency", "Crypto"],
"translate": false
}
where duration is how many minutes you want to collect streaming twitter data, query is a list of search queries that Twitter API will use to send you relevant tweets, translate is boolean in case False will collect only English tweets, otherwise, the service will try machine translation from TextBlob.
What can be done next
- You can make for realtime visualization system (like on the picture on the cover)
- You can make models for predicting assets movements (for example Bitcoin price)
- You can try different sentiment analysis tools like Vader and Watson
- You can collect data enough for deep exploratory analysis and find some cool insights, like who is “an opinion leader” in some topic