



{kind=link}
As companies use machine learning (ML) and AI technologies across a broader suite of products and services, it’s clear that new tools, best practices, and new organizational structures will be needed. In recent posts, we described requisite foundational technologies needed to sustain machine learning practices within organizations, and specialized tools for model development, model governance, and model operations/testing/monitoring.
What cultural and organizational changes will be needed to accommodate the rise of machine and learning and AI? In this post, we’ll address this question through the lens of one highly regulated industry: financial services. Financial services firms have a rich tradition of being early adopters of many new technologies, and AI is no exception:

Learn faster. Dig deeper. See farther.
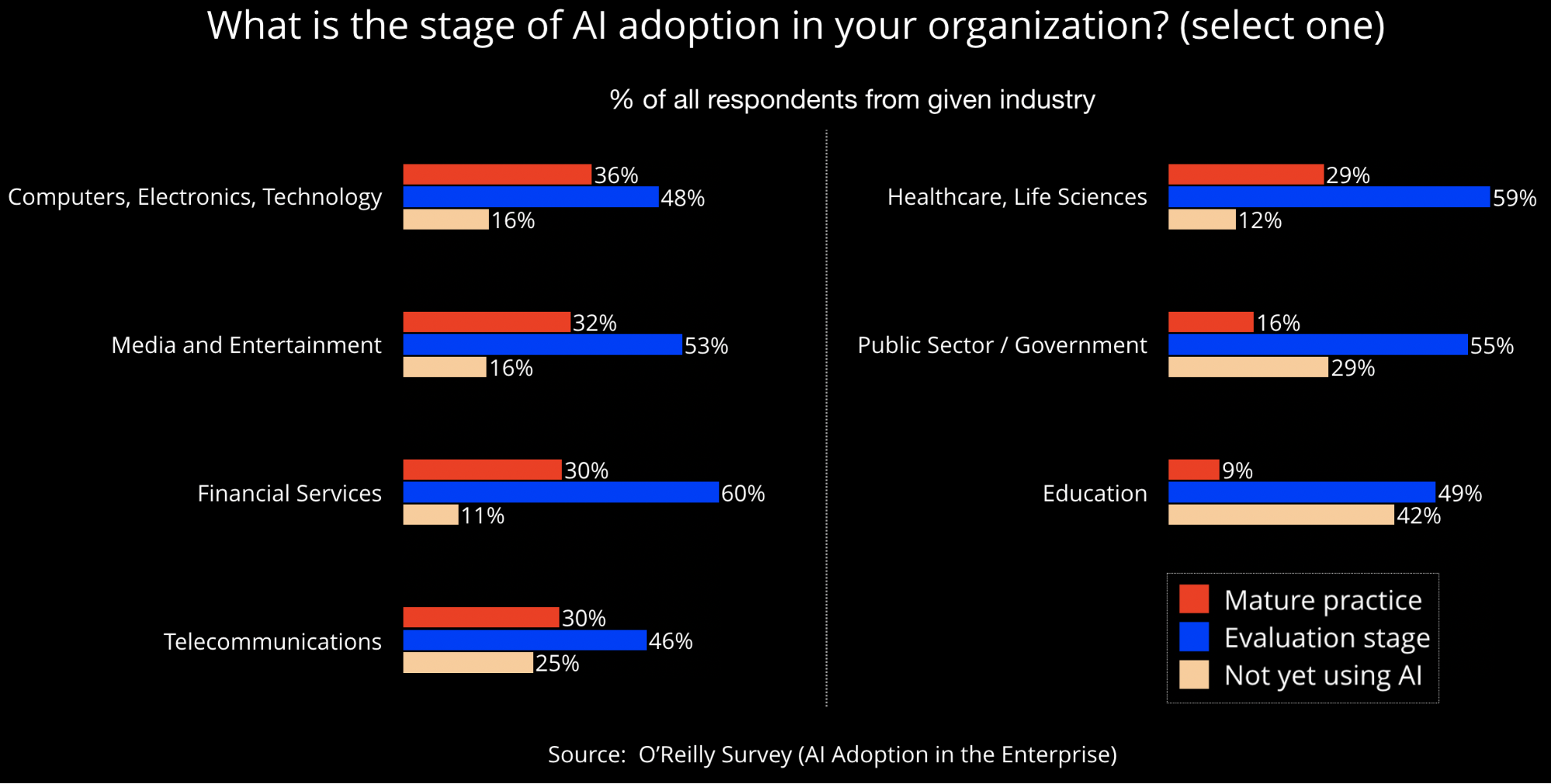
Alongside health care, another heavily regulated sector, financial services companies have historically had to build in explainability and transparency to some of their algorithms (e.g., credit scores). In our experience, many of the most popular conference talks on model explainability and interpretability are those given by speakers from finance.
After the 2008 financial crisis, the Federal Reserve issued a new set of guidelines governing models—SR 11-7: Guidance on Model Risk Management. The goal of SR 11-7 was to broaden a set of earlier guidelines which focused mainly on model validation. While there aren’t any surprising things in SR 11-7, it pulls together important considerations that arise once an organization starts using models to power important products and services. In the remainder of this post, we’ll list the key areas and recommendations covered in SR 11-7, and explain how they are relevant to recent developments in machine learning. (Note that the emphasis of SR 11-7 is on risk management.)
Sources of model risk
We should clarify that SR 11-7 also covers models that aren’t necessarily based on machine learning: “quantitative method, system, or approach that applies statistical, economic, financial, or mathematical theories, techniques, and assumptions to process input data into quantitative estimates.” With this in mind, there are many potential sources of model risk, SR 11-7 highlighted incorrect or inappropriate use of models, and fundamental errors. Machine learning developers are beginning to look at an even broader set of risk factors. In earlier posts, we listed things ML engineers and data scientists may have to manage, such as bias, privacy, security (including attacks aimed against models), explainability, and safety and reliability.
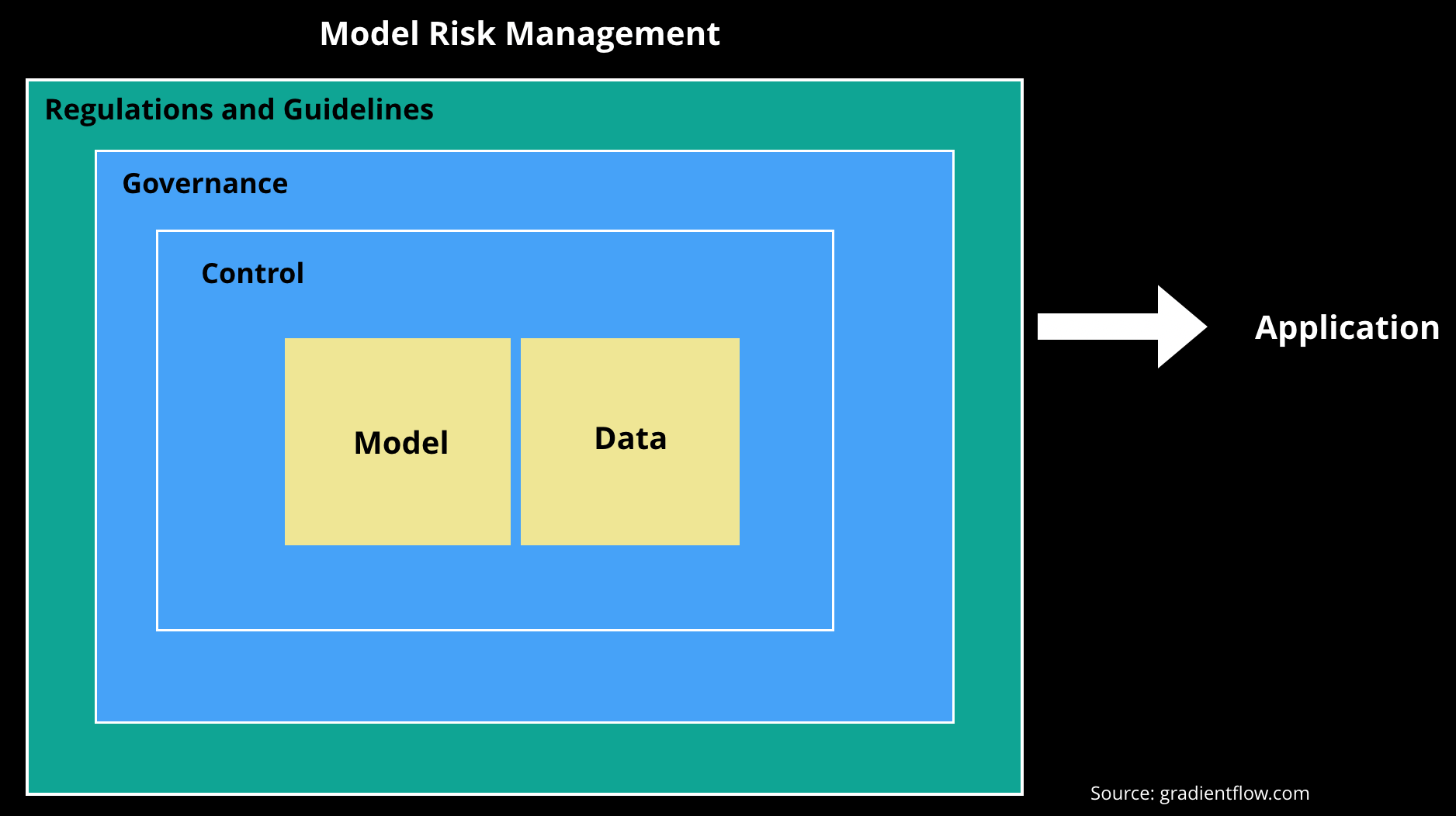
Model development and implementation
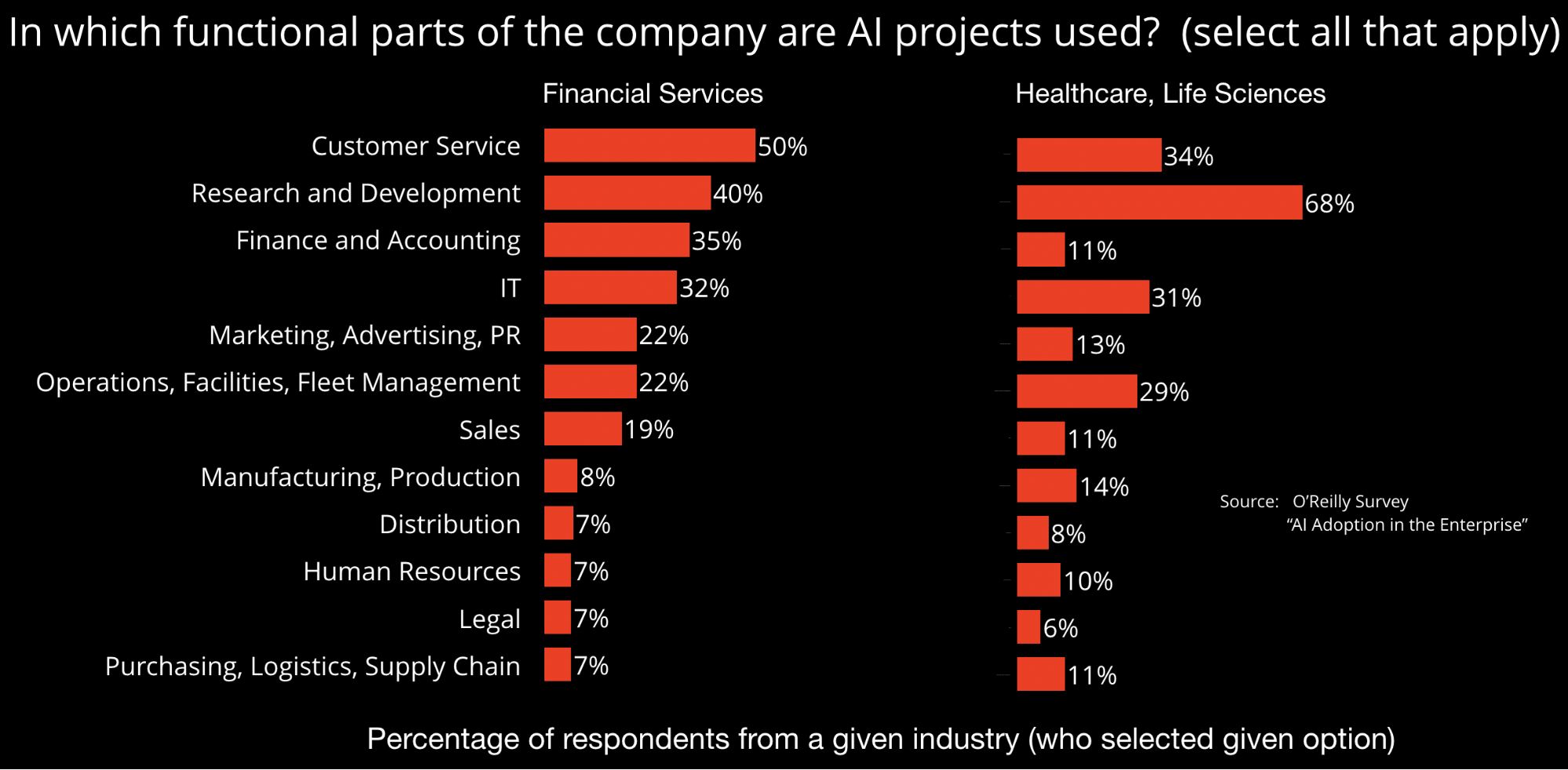
The authors of SR 11-7 emphasize the importance of having a clear statement of purpose so models are aligned with their intended use. This is consistent with something ML developers have long known: models built and trained for a specific application are seldom (off-the-shelf) usable in other settings. Regulators behind SR 11-7 also emphasize the importance of data—specifically data quality, relevance, and documentation. While models garner the most press coverage, the reality is that data remains the main bottleneck in most ML projects. With these important considerations in mind, research organizations and startups are building tools focused on data quality, governance, and lineage. Developers are also building tools that enable model reproducibility, collaboration, and partial automation.
Model validation
SR 11-7 has some specific organizational suggestions for how to approach model validation. The fundamental principle it advances is that organizations need to enable critical analysis by competent teams that are able to identify the limitations of proposed models. First, model validation teams should be comprised of people who weren’t responsible for the development of a model. This is similar to recommendations made in a recent report released by The Future of Privacy Forum and Immuta (their report is specifically focused on ML). Second, given the tendency to showcase and reward the work of model builders over those of model validators, appropriate authority, incentives, and compensation policies should be in place to reward teams that perform model validation. In particular, SR 11-7 introduces the notion of “effective challenge”:
Staff conducting validation work should have explicit authority to challenge developers and users, and to elevate their findings, including issues and deficiencies. … Effective challenge depends on a combination of incentives, competence, and influence.
Finally, SR 11-7 recommends that there be processes in place to select and validate models developed by third-parties. Given the rise of SaaS and the proliferation of open source research prototypes, this is an issue that is very relevant to organizations that use machine learning.
Model monitoring
Once a model is deployed to production, SR 11-7 authors emphasize the importance of having monitoring tools and targeted reports aimed at decision-makers. This is in line with our recent recommendation that ML operations teams provide dashboards with custom views for all principals (operations, ML engineers, data scientists, and business owners). They also cite another important reason to setup independent risk monitoring teams: the authors point out that in some instances, the incentive to challenge specific models might be asymmetric. Depending on the reward structure within an organization, some parties might be less likely to challenge models that help elevate their own specific key performance indicators (KPIs).
Governance, policies, controls
SR 11-7 highlights the importance of maintaining a model catalog that contains complete information for all models, including those currently deployed, recently retired, and under development. The authors also emphasize that documentation should be detailed enough so that “parties unfamiliar with a model can understand how the model operates, its limitations, and its key assumptions.” These are relevant to ML, and the early tools and open source projects for ML lifecycle development and model governance will need to be supplemented with tools that facilitate the creation of adequate documentation.
This section of SR 11-7 also has specific recommendations on roles that might be useful for organizations that are beginning to use more ML in products and services:
- Model owners make sure that models are properly developed, implemented, and used. In the ML world, these are data scientists, machine learning engineers, or other specialists.
- Risk-control staff take care of risk measurement, limits, monitoring, and independent validation. In the ML context, this would be a separate team of domain experts, data scientists, and ML engineers.
- Compliance staff ensure there are specific processes in place for model owners and risk-control staff.
- External regulators are responsible for making sure these measures are being properly followed across all the business units.
Aggregate exposure
There have been many examples of seemingly well-prepared financial institutions caught off-guard by rogue units or rogue traders who weren’t properly accounted for in risk models. To that end, SR 11-7 recommends that financial institutions consider risk from individual models as well as aggregate risks that stem from model interactions and dependencies. Many ML teams have not started to think of tools and processes for managing risks stemming from the simultaneous deployment of multiple models, but it’s clear that many applications will require this sort of planning and thinking. Creators of emerging applications that depend on many different data sources, pipelines, and models (e.g., autonomous vehicles, smart buildings, and smart cities) will need to manage risks in the aggregate. New digital-native companies (in media, e-commerce, finance, etc.) that rely very heavily on data and machine learning also need systems to monitor many machine learning models individually and in aggregate.
Health care and other industries
While we focused this post in guidelines written specifically for financial institutions, companies in every industry will need to develop tools and processes for model risk management. Many companies are already affected by existing (GDPR) and forthcoming (CCPA) privacy regulations. And, as mentioned, ML teams are beginning to build tools to help detect bias, protect privacy, protect against attacks aimed at models, and ensure model safety and reliability.
Health care is another highly regulated industry that AI is rapidly changing. Earlier this year, the U.S. FDA took a big step forward by publishing a Proposed Regulatory Framework for Modifications to AI/ML Based Software as a Medical Device. The document starts by stating that “the traditional paradigm of medical device regulation was not designed for adaptive AI/ML technologies, which have the potential to adapt and optimize device performance in real time to continuously improve health care for patients.”
The document goes on to propose a framework for risk management and best practices for evolving such ML/AI based systems. As a first step, the authors list modifications that impact users and thus need to be managed:
- modifications to analytical performance (i.e., model re-training)
- changes to the software’s inputs
- changes to its intended use.
The FDA proposes a total product lifecycle approach that requires different regulatory approvals. For the initial system, a premarket assurance of safety and effectiveness is required. For real-time performance, monitoring is required—along with logging, tracking, and other processes supporting a culture of quality—but not regulatory approval of every change.
This regulatory framework is new and was published in order to receive comments from the public before a full implementation. It still lacks requirements for localized measurement of safety and effectiveness, as well as for the evaluation and elimination of bias. However, it’s an important first step for developing a fast-growing AI industry for health care and biotech with a clear regulatory framework, and we recommend that practitioners stay educated on it as it evolves.
Summary
Every important new wave of technologies brings benefits and challenges. Managing risks in machine learning is something organizations will increasingly need to grapple with. SR 11-7 from the Federal Reserve contains many recommendations and guidelines that map well over to the needs of companies that are integrating machine learning into products and services.
Related content:
- “Managing risk in machine learning”
- “What are model governance and model operations?”
- “Becoming a machine learning company means investing in foundational technologies”
- “The quest for high-quality data”
- Andrew Burt and Steven Touw on how companies can manage models they cannot fully explain.
- David Talby: “Lessons learned turning machine learning models into real products and services”
- Ira Cohen: “Applying machine learning for insights into machine learning algorithms”
- “You created a machine learning application. Now make sure it’s secure”
- Jike Chong on “Applications of data science and machine learning in financial services”
- Gary Kazantsev on how “Data science makes an impact on Wall Street”