



{kind=link}
You trained a machine learning model, validated its performance across several metrics which are looking good, you put it in production, and then something unforeseen happened (a pandemic like COVID-19 arrived) and the model predictions have gone crazy. Wondering what happened? You fell victim to a phenomenon called concept drift.
But don’t feel bad as it happens to all of us all the time.
Heraclitus, the Greek philosopher, said: “Change is the only constant in life.”
In the dynamic world, nothing is constant. This is especially true when it comes to the data. The data generated from a source of truth changes its underlying distribution over time.
As an example, think of a product recommendation system in eCommerce. Do you think a model that was trained before COVID-19, would work equally well during the COVID-19 pandemic? Due to these kinds of unforeseen circumstances, user behavior changed a lot. The majority of users are focusing on purchasing daily essentials rather than expensive gadgets. So, the user behavior data has changed. Along with that, as a lot of products are out of stock in the market during this kind of situation, we see a completely different kind of shopping pattern for users.
Often these changes in data make the model built on old data inconsistent with the new data, this problem is called “Concept Drift”.
In this article we will talk about:
– Concept drift, Covariate shift, Data Drift: What are those?
– How to detect Concept Drift and what are the types of it?
– Best practices when it comes to dealing with Concept Drift
Note:
You may want to check some other articles from our blog:
- Random Forest Regression: When Does It Fail and Why?
- Machine Learning Experiment Management: How to Organize Your Model Development Process
- The Best Tools, Libraries, Frameworks, and Methodologies that Machine Learning Teams Actually Use – Things We Learned from 41 ML Startups [ROUNDUP]
Open them in a new tab for later and get back to reading about concept drift 

{kind=link}
What does the Concept drift mean?
“Concept drift is the most undesirable yet prevalent property of streaming data as data streams are very unpredictable. Due to concept drift, the performance of mining techniques such as classification or clustering degrades as chances of misclassification increase. Therefore, it becomes necessary to identify such drifts in the data to get efficient results with accuracy.”
(Ref: Methods to Investigate Concept Drift in Big Data Streams)
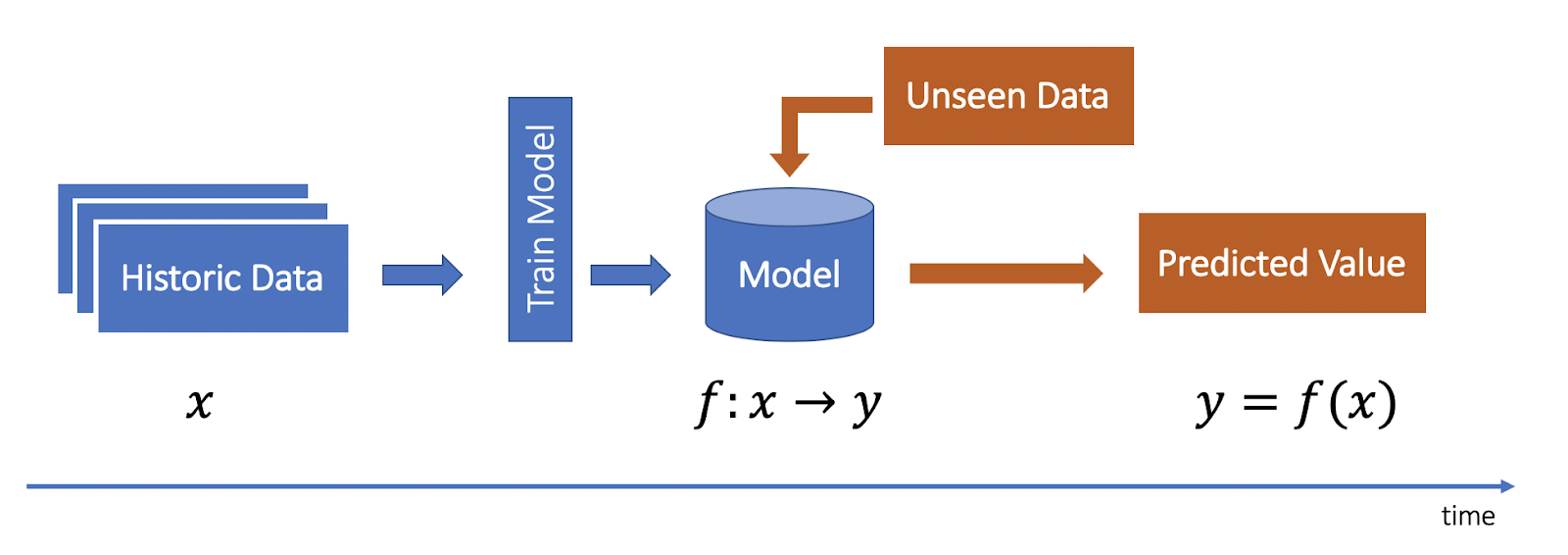
Fig 1: Life cycle of a predictive model
In predictive modeling (as depicted in the above figure), we build a supervised model based on historical data and then use the trained model to predict on unseen data. In the process, the model learns a relationship between the target variable and input features.
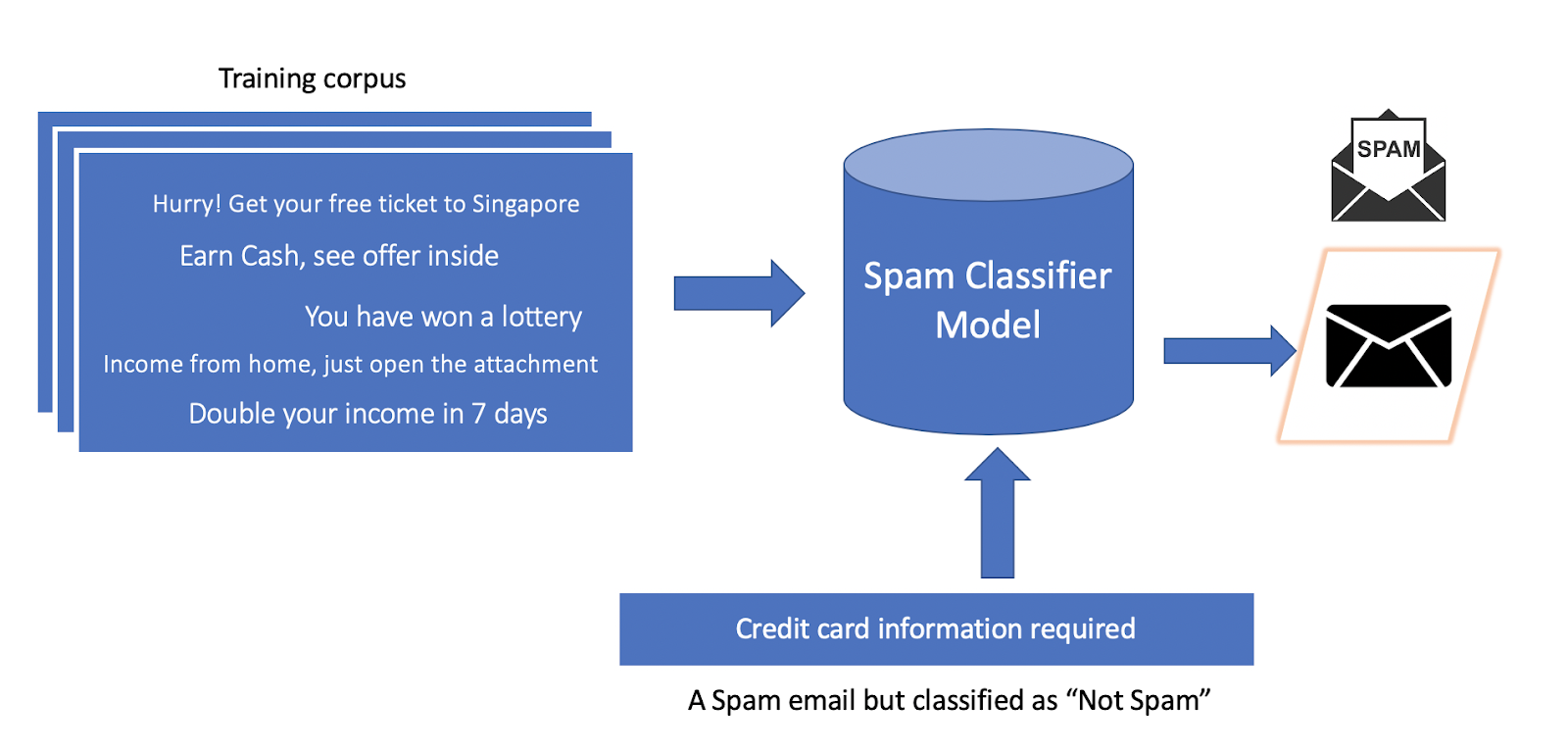
Fig 2: Trained model failed to correctly predict on out of corpus test data
For instance, an email spam classifier, that predicts whether an email is spam or not based on the textual body of the email. The machine learning model learns a relationship between the target variable (spam or not spam) and the set of keywords that appears in a spam email. These sets of keywords might not be constant, their pattern changes over time. Hence the model build on the old set of emails doesn’t work anymore on a new pattern of keywords. If this is the case, then there is a need for a model re-training on the current dataset.
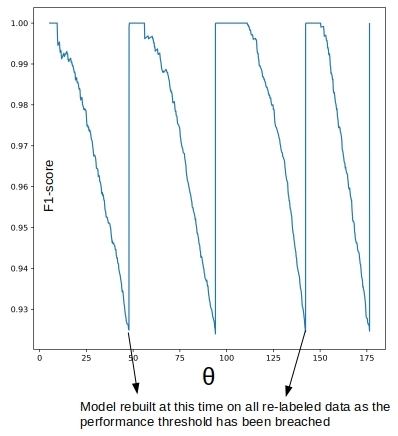
Fig 3: Performance of model over time (Reference)
This figure depicts the performance of a model over time, as you see the performance of the model (measured by F1-score) deteriorates as time is passing by. This phenomenon is called model decay. As the performance degrades below a threshold, the model is re-trained on a re-labeled dataset. This is how the problem of model decay is addressed. If this problem is not addressed or monitored then the model will keep deteriorating its performance and at some point in time, the model will no longer serve the purpose.
In general, Model decay could occur due to the following type of shift.
– Covariate Shift: Shift in the independent variables.
– Prior Probability Shift: Shift in the target variable.
– Concept Drift: Shift in the relationship between the independent and the target variable.
Concept drift vs Covariate shift
Consider a movie recommendation model that was trained on movies watched by retirees, will it give good accuracy when that model is used to recommend movies for children? it will not. The reason is that there is a wide gap in the interest and the activities between these two groups. So, the model will fail in these conditions. Such changes in the distribution of data in train and test sets are called the Covariate shift.
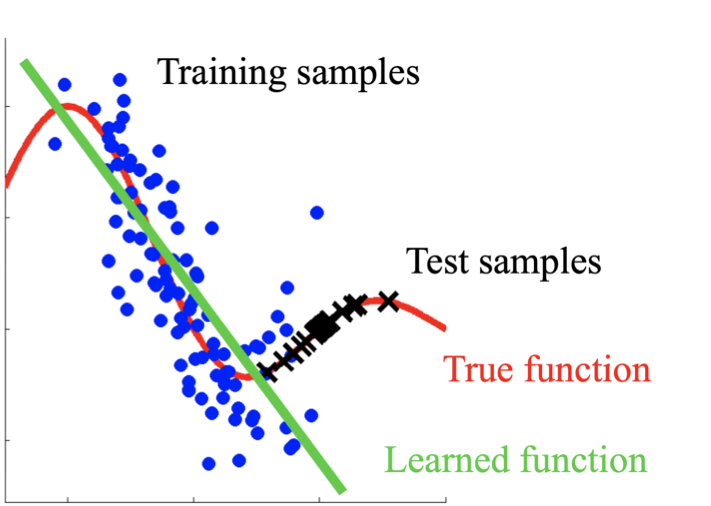
Fig 4: Difference in distribution between train and test dataset in case of Covariate Shift (Reference)
The primary reason behind the occurrence of the Covariate shift is Sample selection bias and non-stationary environments.
– Sample selection bias: It refers to a systematic flaw in the process of data collection or labeling which causes training examples to be selected nonuniformly from the population to be modeled uniformly from the population to be modeled.
– Non-stationary stationary environments: It appears when the training environment is different from the test one, whether it is due to a temporal or a spatial change.
Covariate Shift and Concept Drift, both are the cause of degrading model performance but both should be treated differently. So, one must disambiguate the covariate shift from concept drift and should apply preventive care based on the presence of a Covariate shift or Concept drift or both.
Data drift vs Concept drift:
In the world of Big Data, billions of data are generated at every moment. As we collect data from a source over a long time, the data itself might change and that could be due to multiple reasons. it could be due to the dynamic behavior of noise in the data or it could be due to a change in the data collection process.
When data changes in general, this problem is called data drift whereas the changes in the context of the target variable are called concept drift. Both of these drift causes model decay but needs to be addressed separately.
Examples of concept drift:
– Personalization: Whether it’s eCommerce, Movie Recommendation, or Personal Assistant system, Personalization is the key to success for most of the customer-centric businesses. In eCommerce, a personalization system tries to profile the user shopping pattern and based on that provide personalized search results or recommend relevant products. Due to unforeseen circumstances, a user’s shopping behavior might change over time, it could be due to a life event like marriage, relocation to a different geographical location or it could be due to a pandemic like COVID-19. This event had drastically changed the user’s shopping habits. Due to these kinds of factors, a personalization system built today might not be so relevant after a few years, and that’s due to the problem of concept drift.
– Forecasting: Forecasting is a field of research where we predict future trends. It’s extensively used in finance, weather, and demand forecasting. Typically these kinds of models are built using historical data and the expectation is to capture the kind of trend and seasonality present in the historic data that might be followed in the future. But due to unforeseen circumstances, the trend might change which might result in concept drift. In weather data, there is a seasonal change that is extremely slow to happen. In other kinds of applications, these kinds of changes are typically much slower. But, over a long time, it makes the existing model obsolete.
How to monitor concept drift
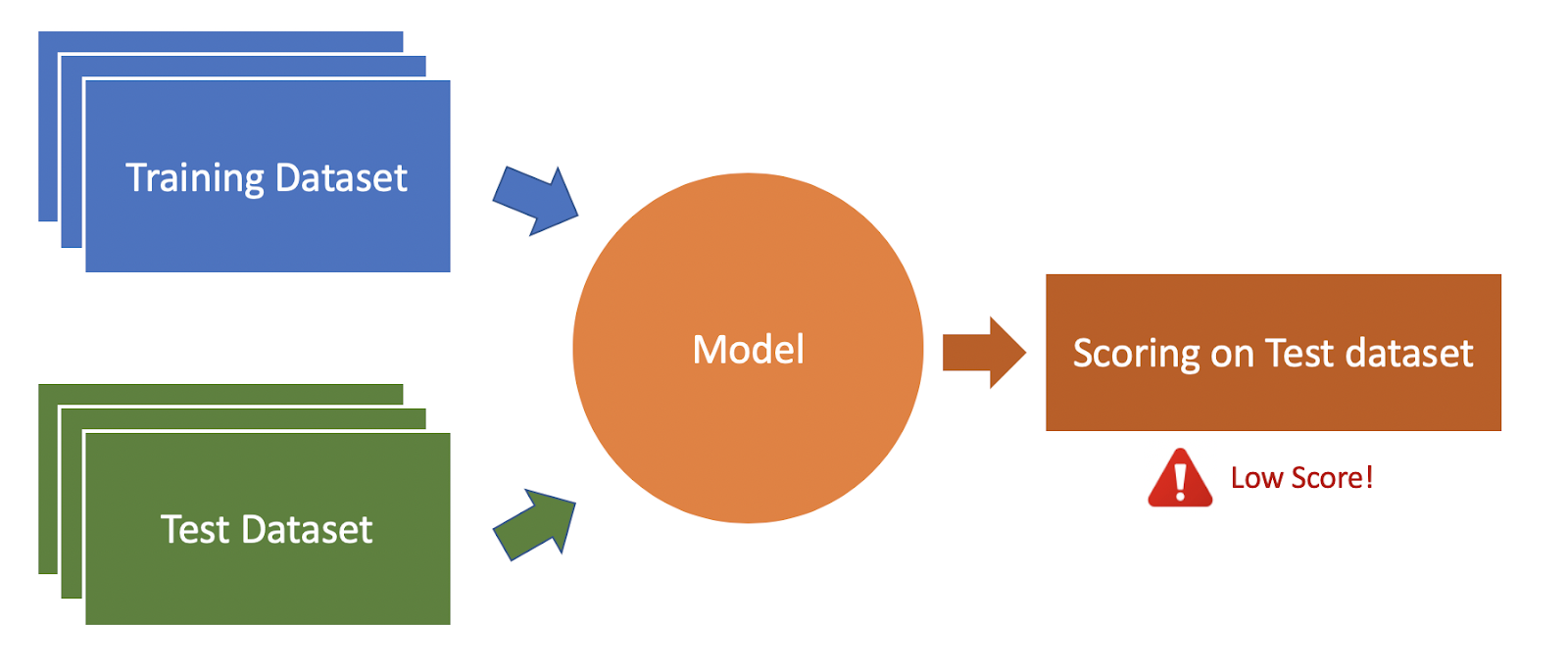
Fig 5: Concept drift monitoring system
The generic way to monitor concept drift is depicted in the following image:
– First, the training data set is collected and curated,
– then the model is trained on that.
– the model is continuously monitored against a golden data set which is curated by human experts.
– If the performance score is degraded below a threshold, an alarm is triggered to re-train the model.
Primarily there are 3 kinds of concept drift as depicted in Fig 2 and each type of phenomenon requires a different method to detect it (and monitor the change).
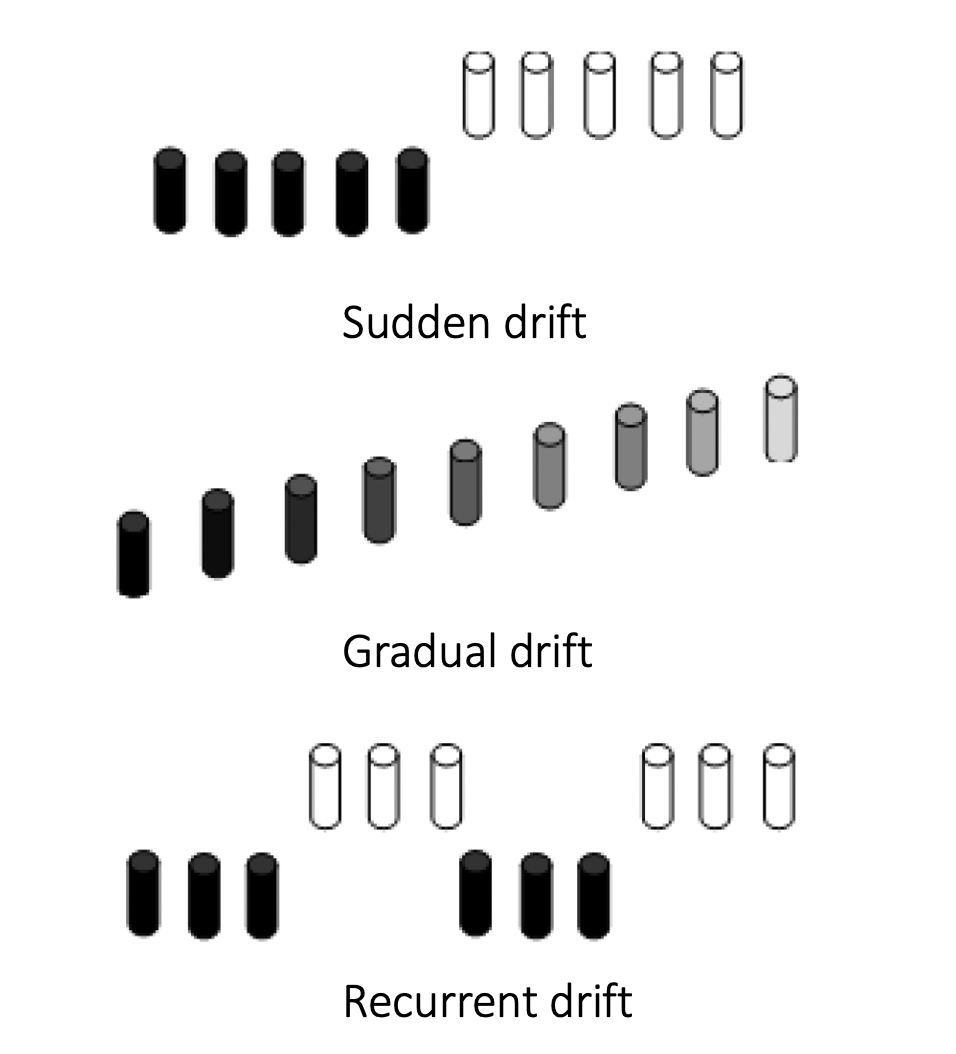
Fig 6: Types of concept drift
– Sudden: Where the concept drift happens abruptly due to unforeseen circumstances like COVID-19 pandemic which affected several sectors like eCommerce, health care, finance, insurance, and many more. Such abrupt change might happen in as short as a few weeks. This kind of drift is usually driven by some external event. If there is no active monitoring system to detect drift in data, it’s natural to perform a quick evaluation of the presence of concept drift after a major event.
– Gradual: This kind of drift takes a long time to occur and for many use-cases, it’s quite natural to happen. As an example, inflation can affect a pricing model which might take a long time to put a significant impact. Gradual or sometimes called incremental changes, are usually addressed in time series model by capturing the change in seasonality, if not addressed, this is a matter of concern and needs to be addressed.
– Recurrent: This kind of drift happens periodically, maybe during a specific time in a year. As an example, during events like Black Friday, Halloween, etc, users’ shopping pattern is different compared to other times in the year. So, a different model specifically trained on the Black Friday data is used during the time of that event. Recurrent patterns are difficult to monitor as the periodicity of a pattern might also be dynamic.
Based on the type of concept drift that exists, there is a diverse set of methods to monitor concept drift.
Some of the most prominent methods are:
– Monitoring the performance of the model over a long time. As an example, one might monitor F1-score as an accuracy metric and if the score is deteriorating over a long time then this could be a signal of concept drift.
– Monitoring the classification confidence (applicable only to classification). The confidence score of a prediction reflects the probability of a data point belonging to the predicted class. A significant difference in the average confidence score in two windows represents the occurrence of concept drift.
How to prevent concept drift
Now, the biggest question is whether this problem can be avoided and what are the ways to prevent it from happening.
An ideal concept drift handling system should be able to:
– quickly adapt to concept drift,
– be robust to noise and distinguish it from concept drift,
– recognize and treat significant drift in model performance.
At a high level, there are 5 kinds of ways to address concept drift.
– Online learning where the learner is updated on the fly as the model processes one sample at a time. In reality, the majority of the real-life applications run on streaming data and online learning is the most prominent way to prevent concept drift.
– Periodically re-train the model which can be triggered at different instances like once the model performance degrades below a specified threshold or once average confidence score between 2 windows of data observes major drift.
– Periodically re-train on a representative subsample. If the presence of concept drift is detected, select a sub-sample of the population using a method like an instance selection where the sample is representative of the population and follow the same probability distribution as the original data distribution. Then, explicitly re-label those data points with the help of human experts and train the model on the curated dataset.
– Ensemble learning with model weighting where multiple models are ensembled and the output is generally a weighted average across the individual model output.
– Feature dropping is another way to deal with the concept drift. Multiple models are built using one feature at a time and drop those features where AUC-ROC response is not up to the mark.
Online learning
In machine learning, models are often trained in a batch setting, where the learner is optimized on a batch of data in one go. This results in a static model that assumes a static relationship between the independent and target variable. So, after a long time, this kind of model might require re-training to learn patterns from new data.
In real life, most of the application works on real-time streaming data feed where the model processes one sample at a time and therefore can be updated on the fly. This process is called Online learning or incremental learning which helps the model to avoid concept drift as new data is used to update the model hypothesis constantly.
This process allows us to learn from a massive data stream and can seamlessly be applied to an application like time series forecasting, movie or eCommerce recommender system, spam filtering, and many more.

Fig 7: Online learning system
In online learning, a sequence of instances is observed, one at a time which might not be equally spaced in a time interval. So, at every timestamp t, we have labeled historic data, (X1,……Xt). Using this historic data (X1,…, Xt) or a sub-sample of that is used to build a model say Lt.
As the next data point Xt+1 arrives, the target variable (yt+1) is predicted using Lt. Once the next instance Xt+2 has arrived, the real yt+1 is available. So, the model is updated with historic data (X1,….Xt, Xt+1). The chance of concept drift increases, when the data at a different time is generated from a different source. Many times, we fail to disambiguate between Concept drift and random noise and misjudge noise as concept drift. We should be extremely careful in handling noise.
Note:
Please note periodic seasonality is not considered a concept drift except if the seasonality is not known with certainty. As an example, a peak in sales of ice cream is associated with summer but it can start at a different time every year depending on the temperature and other factors, therefore it is not known exactly when the peak will start.
Creme is a python library for online machine learning where the model learns from single observation at a time and can be used to learn from streaming data. This is one of the fantastic tools available for online learning and helps us to keep the model away from concept drift.
Model re-training
Another way to deal with concept drift is to periodically re-train the model to learn from historical data. If the model observes concept drift, the model should be re-trained with recent data.
As an example, an application in the finance domain might require a re-training in the first week of April to accommodate changes due to the financial year-end. Another example could be a sudden change in user preference due to an epidemic.
The difficult part is to detect the moment when model re-training is needed but as we discussed it earlier there are ways to do it. In any case, once the drift is detected we retrain the model on new data to incorporate the changing conditions.
This process might be costly because, in a supervised setting, the additional data points need to be re-labeled. So, rather than re-training on the whole dataset, one might consider selectively creating a sub-sample from the complete population and re-train on that. This approach is discussed in the next section.
Re-Sampling using instance selection
Instance selection is the concept of selecting a subset from the population by maintaining the underlying distribution intact so that the sampled data is representative of the characteristics of the overall data population.
To put it simply the idea is that we:
– Choose a tiny but representative sample of the population (by using a method like an instance selection)
– run the model on the sub-sample
– find out data points from the sub-sample where the model performance is not up to the mark.
– while running instance selection, we maintain a map between a representative sample and the group of data points represented by that sample. Once we have figured out the list of observations (from the tiny sub-sample) where the model performance is not good, we consider all the data points represented by these samples and re-train the model on those.
Ensemble learning with model weighting
Ensemble learning maintains an ensemble of multiple models that make a combined prediction. Typically the final prediction is a weighted average of individual predictions where the weight reflects the performance of an individual model on recent data.
The motivation behind an ensemble learning method is that during a change, data might be generated from a mixture of multiple distributions. The ensemble of multiple models where each model individually tries to characterize the data distribution and relationship between the feature and the target variable should work better.
There are different variations of ensemble learning based on how models are updated. One of the ways is that for each new batch of data, a new classifier is trained and combined using a dynamically weighted majority voting strategy.
Feature dropping
Feature dropping is one of the simplest but effective methods to deal with concept drift and widely used in the industry. The idea is to build multiple models where one feature is used at a time keeping the target variable unchanged. For each model, after prediction on test data, the AUC-ROC response is monitored and if the value of AUC-ROC for a particular feature goes beyond a particular threshold (maybe 0.8), that particular feature might be considered as drifting and hence that feature might be dropped.
Best practices for dealing with the concept drift
In recent times, a lot of research is going on in this field and there is no single de-facto standard algorithm or methodology followed to deal with the concept drift. That said, during my work on those problems I arrived at the following end-to-end process that can detect and prevent the presence of concept drift:
Step1: Data Collection and Preprocessing:
This step involves dealing with missing values, outliers, label encoding for categorical variables, and so on.
Step2: Data labeling:
i) Divide the data stream into a series of windows.
iii) Assign a class label to individual data points based on the business context.
Step3: Detection of concept drift:
i) Data points of adjacent windows are analyzed to identify concept drift. Accuracy metrics like accuracy, precision, recall, AUC-ROC response curve and execution time, classification, or clustering error might be analyzed in order to detect concept drift.
Step4: Avoid or remove concept drift:
If the presence of concept drift is detected, follow an appropriate methodology to get rid of that.
Final thoughts
Concept drift is an important issue in Machine Learning and Data mining and should be addressed carefully.
The big problem is how to detect the presence of concept drift as there is no one-size-fits-all solution. It occurs in the presence of many hidden factors that are difficult to figure out. Mostly “concept drift”-related methods are very subjective to the nature of the problem. Nevertheless, with the kind of methods mentioned throughout this article, could be a good reference for building a baseline system to detect and prevent concept drift.
There is plenty of research going on in this topic and those are mostly around developing criteria for detecting crucial changes. More research is needed to build a robust system which can trigger an alert based on different kinds of concept drift and different level of noise.
References:
- Creme
- Methods to Investigate Concept Drift in Big Data Streams
- Dataset Shift in Classification Approaches and Problems
- A Survey on Concept Drift Adaptation
- An overview of concept drift applications
- Concept Drift Detection Through Resampling
- Learning under Concept Drift: an Overview
- Methods to Investigate Concept Drift in Big Data Streams
- Online Methods of Learning in Occurrence of Concept Drift
- The problem of concept drift: definitions and related work
- Understanding Concept Drift
- Covariate Shift – Unearthing hidden problems in Real-World Data Science