



{kind=link}
In this post, I share slides and notes from a keynote that Roger Chen and I gave at the 2019 Artificial Intelligence conference in New York City. In this short summary, I highlight results from a — survey (AI Adoption in the Enterprise) and describe recent trends in AI. Over the past decade, AI and machine learning (ML) have become extremely active research areas: the web site arxiv.org had an average daily upload of around 100 machine learning papers in 2018. With all the research that has been conducted over the past few years, it’s fair to say that we now have entered the implementation phase for many AI technologies. Companies are beginning to translate research results and developments into products and services.
An early indicator of commercial activity and interest is the number of patent filings. I was fortunate enough to contribute to a recent research report from the World Intellectual Patent Office (WIPO) that examined worldwide patent filings in areas pertaining to AI and machine learning. One of their key findings is that the number of patent filings is growing fast: in fact, the ratio of patent filings to scientific publications indicates that patent filings are growing at a faster rate than publications.

Learn faster. Dig deeper. See farther.

Looking more closely into specific areas, the WIPO study found that Computer Vision is mentioned in 49% of all AI-related patents (167,000+). In addition, the number of computer vision patent filings is growing annually by an average of 24%, with more than 21,000 patent applications filed in 2016 alone.

It has been an extremely productive year for researchers in natural language. Every few months there seems to be new deep learning models that establish records in many different natural language tasks and benchmarks.

Much of this research was done in the open, accompanied by open source code and pre-trained models. While applications of AI and machine learning and AI to text are not new, the accuracy of some of these models has drawn interest from practitioners and companies. Some of the most popular trainings, tutorials, and sessions at our AI conferences are ones that focus on text and natural language applications. It’s important to point out that, depending on your application or setting, you will likely need to tune these language models for your specific domain and application.
We continue to see improvements in tools for deep learning. Our surveys show that TensorFlow and PyTorch remain the most popular libraries. There are new open source tools like Ludwig and Analytics Zoo aimed at non-experts who want to begin using deep learning. We are also seeing tools from startups like Weights & Bias and Determined AI (full disclosure: I am an advisor to Determined AI), and open source tools like Nauta, designed specifically for companies with growing teams of deep learning engineers and data scientists. These tools optimize compute resources, automate various stages of model building, and help users keep track and manage experiments.
In our survey that drew more than 1,300 respondents, 22% signaled they are beginning to use reinforcement learning (RL), a form of ML that has been associated with recent prominent examples of “self-learning” systems. There are a couple of reasons for this. We are beginning to see more accessible tools for RL—open source, proprietary, and SaaS—and more importantly, companies like Netflix are beginning to share use cases for RL. Focusing on tooling for RL, there have been a variety of new tools that have come online over the last year. For example, Danny Lange and his team at Unity have released a suite of tools that enable researchers and developers to “test new AI algorithms quickly and efficiently across a new generation of robotics, games, and beyond.”
Let’s look at another one of these tools more closely. At our AI conferences, we’ve been offering a tutorial on an open source computing framework called Ray, developed by a team at UC Berkeley’s RISE Lab.

As I noted in a previous post, Ray has grown across multiple fronts: number of users, contributors, and use cases. Ray’s support for both stateless and stateful computations, and fine-grained control over scheduling allows users to implement a variety of services and applications on top of it, including RL. The RL library on top of Ray—RLlib—provides both a unified API for different types of RL training, and all of its algorithms are distributed. Thus, both RL users and RL researchers are already benefiting from using RLlib.
There’s also exciting news on the hardware front. Last year we began tracking startups building specialized hardware for deep learning and AI for training and inference as well as for use in edge devices and in data centers. We already have specialized hardware for inference (and even training—TPUs on the Google Cloud Platform). Toward the latter part of this year, in the Q3/Q4 time frame, we expect more companies to begin releasing hardware that will greatly accelerate training and inference while being much more energy efficient. Given that we are in a highly empirical era for machine learning and AI, tools that can greatly accelerate training time while lowering costs will lead to many more experiments and potential breakthroughs.
In our survey, we found more than 60% of companies were planning to invest some of their IT budget into AI. But the level of investment depended on how much experience a company already had with AI technologies. As you can see in Figure 5, those with a mature practice plan to invest a sizable portion of their IT budget into AI. There’s a strong likelihood that the gap between AI leaders and laggards will further widen.
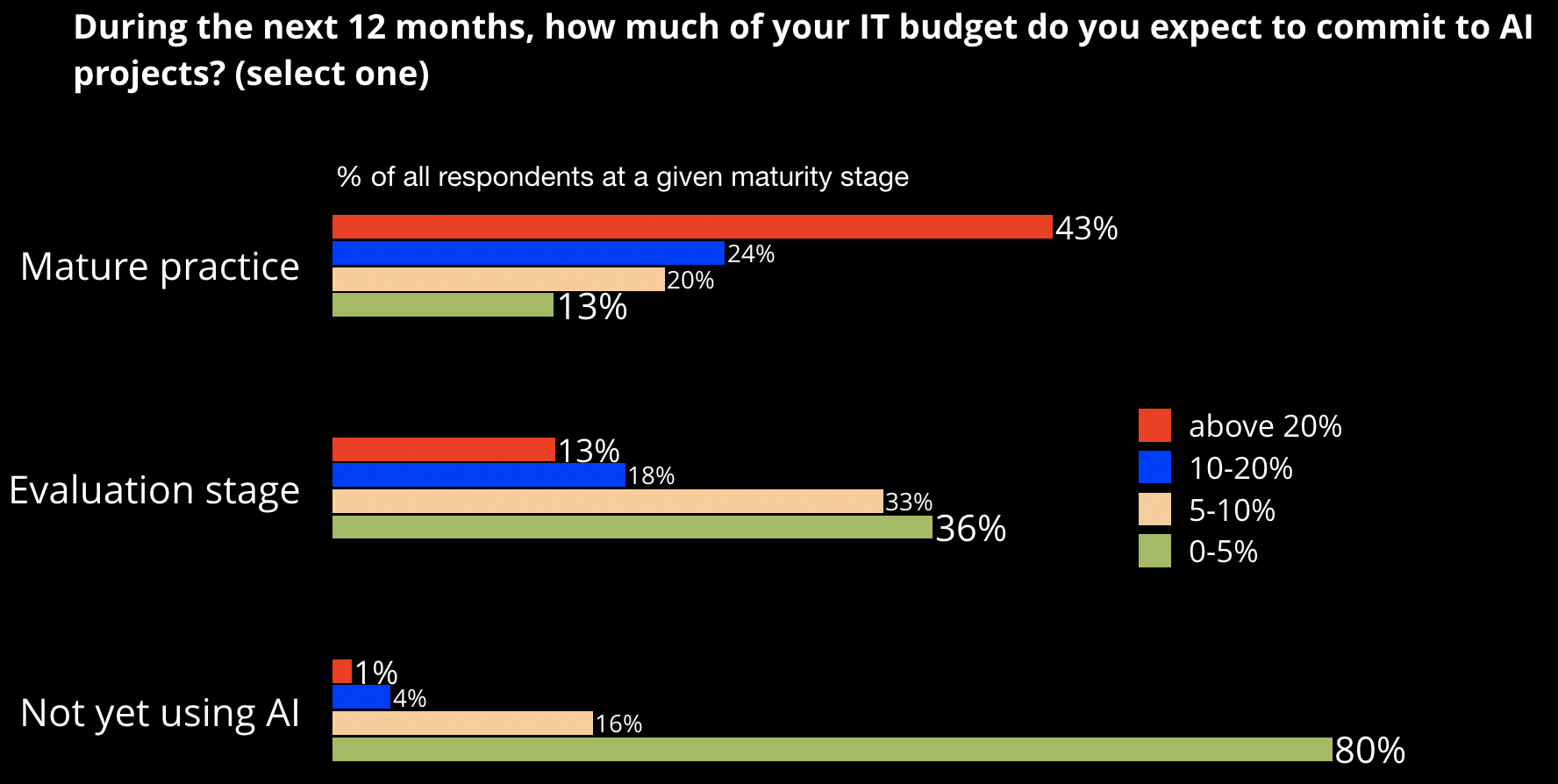
So, what is holding back adoption of AI? According to our survey, the answer depends on the maturity level of a company.

Those who are just getting started struggle with finding use cases or explaining the importance of AI. Also, we are far from General AI: we are at a stage where these technologies have to be tuned and targeted, and many AI systems work by augmenting domain experts. Thus, these technologies require training at all levels of an organization, not just in technical teams. It’s important that managers understand the capabilities and limitations of current AI technologies, and see how other companies are using AI. Take the case of robotic process automation (RPA), a hot topic among enterprises. It’s really the people closest to tasks (“bottoms up approach”) who can best identify areas where RPA is most suitable.
On the other hand, those with mature AI practices struggle with lack of data and lack of skilled people. Let’s look at the skills gap more closely in Figure 7.
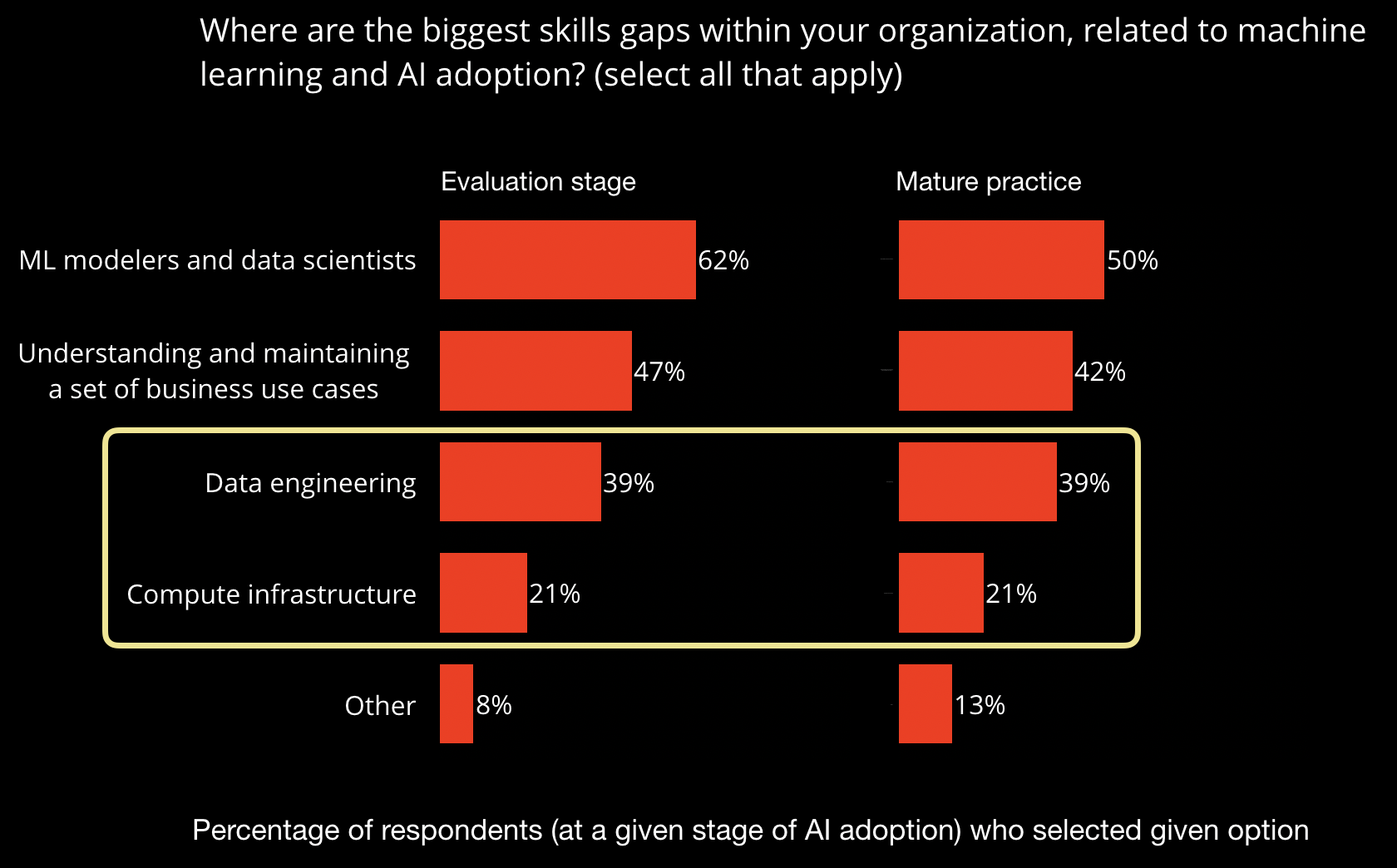
Skills requirements depend on the level of maturity as well. Companies with more mature AI practices have less trouble finding use cases and have less need for data scientists. However, the need for data and infrastructure engineers cuts across companies. It’s important to remember that much of AI today still requires large amounts of training data to train large models that require large amounts of compute resources. I recently wrote about the requisite foundational technologies needed to succeed in machine learning and AI.
As the use of AI technologies grows within companies, we will need better tools for machine learning model development, governance, and operations. We are beginning to see tools that can automate many stages of a machine learning pipeline, help manage the ML model development process, and search through the space of possible neural network architectures. Given the level of excitement around ML and AI, we expect tools in these areas to improve and gain widespread adoption.
With the growing interest in AI among companies, this is a great time to be building tools for ML. When we asked our survey respondents, “Which tools are you planning to incorporate into your ML workflows within the next 12 months?”, we found:
- 48% wanted tools for model visualization
- 43% needed tools for automated model search and hyperparameter tuning
Companies are realizing that ML and AI is much more than optimizing a business or a statistical metric. Over the past year, I’ve tried to summarize some of these considerations under the umbrella of “risk management,” a term and practice area many companies are already familiar with. Researchers and companies are beginning to release tools and frameworks to explain various techniques they are using to develop “responsible AI.” When we asked our survey respondents, “What kinds of risks do you check for during ML model building and deployment?”, we found the following:
- 45% assessed model interpretability and explainability
- 41% indicated that they had tests for fairness and bias
- 35% checked for privacy
- 34% looked into safety and reliability issues
- 27% tested for security vulnerabilities
A word about data security. In the age of AI, there are situations where data integrity will be just as critical as data security. That’s because AI systems are highly dependent on data used for training. Building data infrastructure that can keep track of data governance and lineage will be very important, not only for security and quality assurance audits, but also for compliance with existing and future regulations.

We are very much in the implementation phase for machine learning and AI. The past decade has produced a flurry of research results, and we are beginning to see a wide selection of accessible tools aimed at companies and developers. But we are still in the early stages of AI adoption, and much work remains in many areas on the tooling front. With that said, many startups, companies, and researchers are hard at work to improve the ecosystems of tools for ML and AI. Over the next 12 months, I expect to see a lot of progress in tools that can ease ML development, governance, and operations.
Related content:
- “Modern Deep Learning: Tools and Techniques” – a new tutorial at the Artificial Intelligence conference in San Jose.
- “Becoming a machine learning company means investing in foundational technologies”
- “Lessons learned building natural language processing systems in health care”
- “The evolution and expanding utility of Ray”
- “Practical applications of reinforcement learning in industry”
- “Specialized tools for machine learning development and model governance are becoming essential”