



This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we will discuss advanced topics in hives which are required for Data-Engineering. Whenever we design a Big-data solution and execute hive queries on clusters it is the responsibility of a developer to optimize the hive queries.
Performance Tuning in the Hive
Hive performance tuning refers to the collection of steps designed to improve hive query performance. When queries are not optimised, simple statements take longer to execute, resulting in performance lags and downtime, and it takes effect on the other Application which is using the same cluster.
Optimize a Hive Advanced Query
Hive Provides different techniques to improve the performance. We can divide Hive optimisation into 3 parts.
- Design Level Optimisation
- Query Level Optimisation.
- Simplifying Query Expression
Design Level Optimisation
While optimising the hive query we should always start to optimize it by design based on our data so later it will not create many problems.
-While designing the table, First, tweak your data through partitioning, bucketing, and compression.
– Always Choose the right File format While designing Hive Queries selection of the correct file format plays a Very Important Role to improve your query performance.
– If you are doing writing more often then use the row-level file format, where writing is very easy and fast
– If you are doing reading more often they always go for column level format, which will help you to read data quickly.
Partitioning and Bucketing
Partition and Bucket are the design level optimisation technique in the hive.
Hive partitions are used to split the larger table into several smaller parts based on one or multiple columns (partition key, for example, date, state e.t.c).
Let’s say I have a department table which contains the data of different departments. i.e. IT,Sales,RND,Business,HR.
And IT team trying to query the data which contains IT level Information, In that case, the query will scan the full department table, although we are Interested only In IT data. This unnecessary scan will take Time.
Let’s consider we have the same number of rows for each department and for one department it’s should take 2 min, since we are not using partition here so it will scan all 5 departments’ data which will take around 10 min (2*5=10 min), which will decrease Hive query performance.
What is the Solution to Above Problem?
To avoid these kinds of Issues which will decrease hive table performance, we can with partitioning concept in the hive, which will logically divide data into small-small Partition based on PartitionColumnn and avoid full scan.
Let’s Say If we do partition on the Department column here then it will divide this big Department table into 5 different Partitions so whenever user file queries it will go to specific Partition and scan data from there.
At Hdfs it will scan data like the below:
/user/hdfs/…/Dept=IT
/user/hdfs/…/Dept=Sales
/user/hdfs/…/Dept=Business
/user/hdfs/…/Dept=HR
/user/hdfs/…/Dept=RND
From the above file structure, we can clearly see that it will store data based on the partition column and will scan only required files to return results.
How to decide PartitionColumn?
we should be very careful when we create partitions on Hive.
Let’s say if we have a requirement to scan data department-wise then we can create a partition on the Dept column and it will scan the data from there. But now consider you have a requirement to scan data yearly and you have created a partition on 4 columns (Year, month, day, hour) In this case Hive will distribute data based on (Year, month, day, hour) columns. So for a single year unnecessary, we need to scan multiple partitions.
1 year=12 Month12 months=365 Days365 days=365*24 Hours
So It will Create a 12*365*24 Number of Partitions at the hdfs location, and whenever we try to query the data for one year it will scan all the partitions (12*365*24) and will give the result.
Types of Partitions
- Static Partitioning
- Dynamic Partitioning
Static Partitioning: In static Partitioning, we should have an Idea of data and here we usually load each partition manually. It is required to pass the values of partitioned columns manually while loading the data into the table. Hence, the data file doesn’t contain the partitioned columns.
let’s say we have a country table and have a partition on State Column then in advance we know that there should be 28 partitions, so here we can use the static partitions.
cat mp.txt Rahul,1,Patidar,India Rahul,2,Patidar,India Rahul,3,Patidar,India Rahul,4,Patidar,India Rahul,5,Patidar,India cat up.txt Umesh,6,Patidar,India Umesh,7,Patidar,India Umesh,8,Patidar,India Umesh,9,Patidar,India Umesh,10,Patidar,India cat karnataka.txt Pawan,11,Patidar,India Pawan,12,Patidar,India Pawan,13,Patidar,India Pawan,14,Patidar,India Pawan,15,Patidar,India
create table CountryTable (name int, id string, lastname string, country string) partitioned by (state string) row format delimited fields terminated by ',';
describe student;
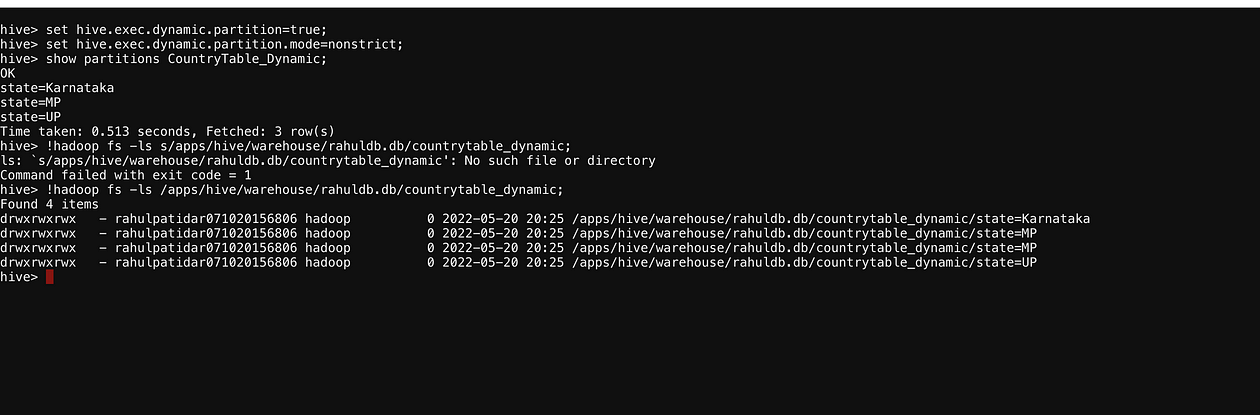
load data local inpath '/home/rahulpatidar071020156806/mp.txt' into table CountryTable partition(state= "MP"); load data local inpath '/home/rahulpatidar071020156806/Karnataka.txt' into table CountryTable partition(state= "Karnataka"); select * from CountryTable; select * from CountryTable where state='MP'; !hadoop fs -ls /apps/hive/warehouse/rahuldb.db/CountryTable/; load data local inpath '/home/rahulpatidar071020156806/up.txt' into table CountryTable partition(state= "UP"); load data local inpath '/home/rahulpatidar071020156806/karnataka.txt' into table CountryTable
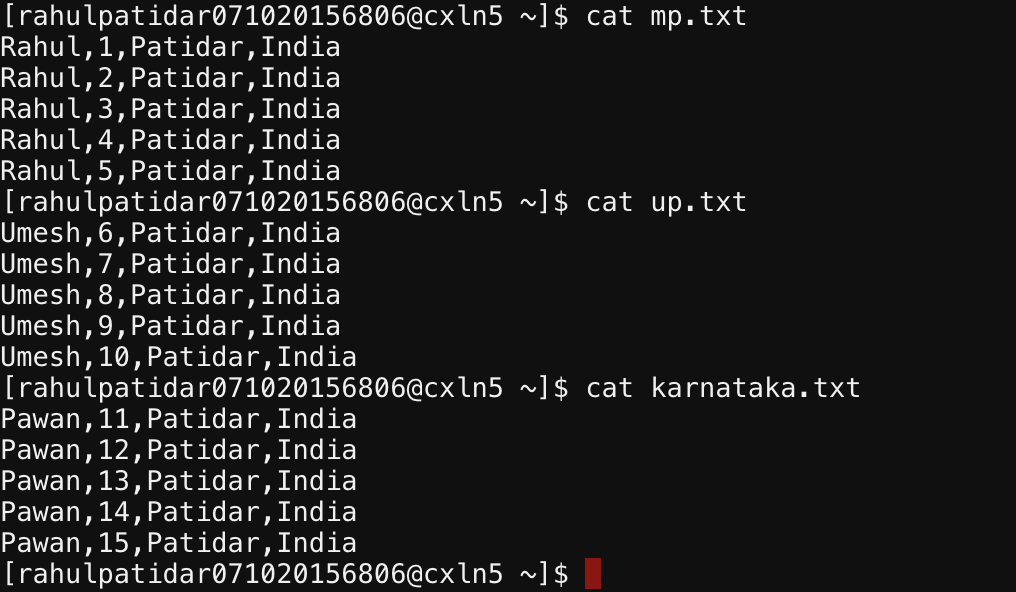
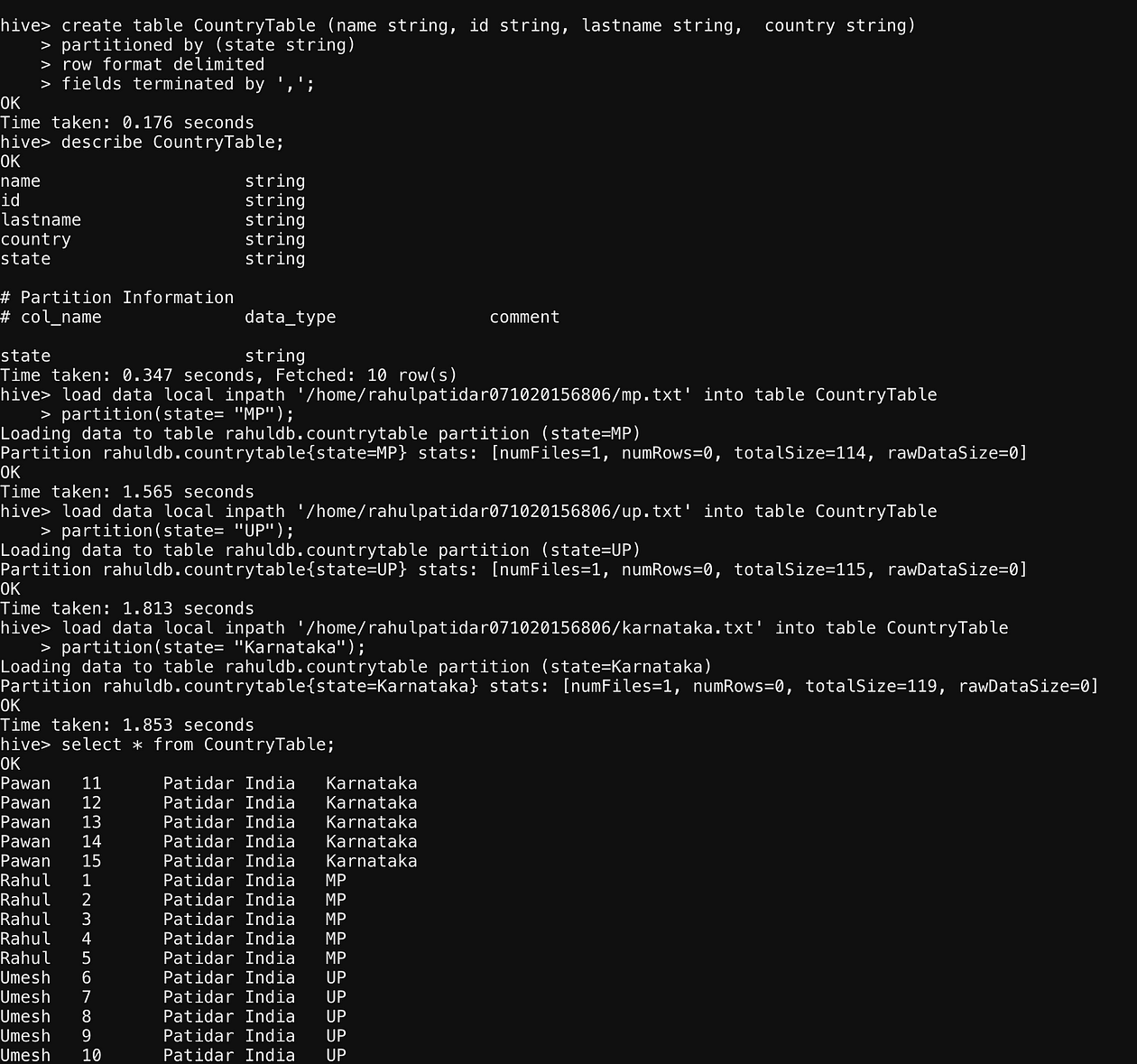
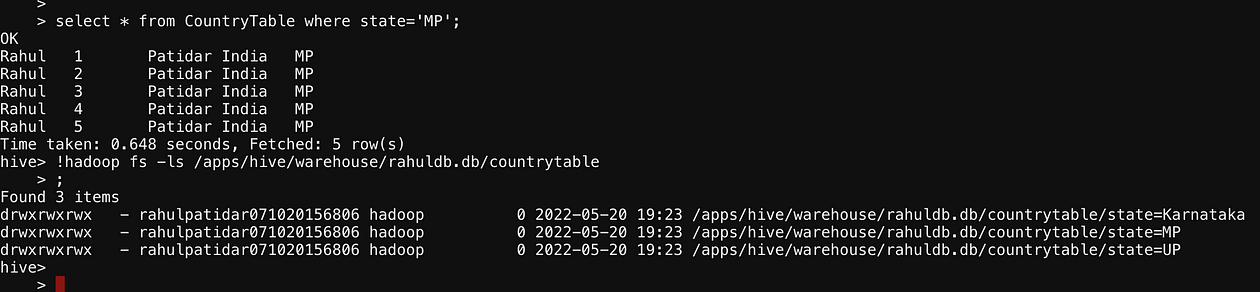
So In Above Screenshot, we saw that we don’t have a state Column in our actual data but we have added a state in table data, which is our PartitionColumn and passed its value manually from the Load command.
Dynamic Partitioning
In Dynamic partitioning, the values of partitioned columns exist within the Data. So, it is not required to pass the values of partitioned columns manually.
we just need to create this partition column in the hive and at run time-based on data, the system will decide and create the partition.
Let’s say we are loading data from one file and in the file we have state value as Tamilnadu, and next time in the next file we get state value as Kolkatta, In this case, the dynamic partition will create Karnataka partition at the run time automatically.
We need to set the below Properties to enable dynamic Partition in the hive.
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict;
The direct load command does not work in dynamic partitions in we need to follow the below steps:
create one non-partition table.
load data from a file in this table
Now create one partition table.
Insert data from non-partition to partition-table.
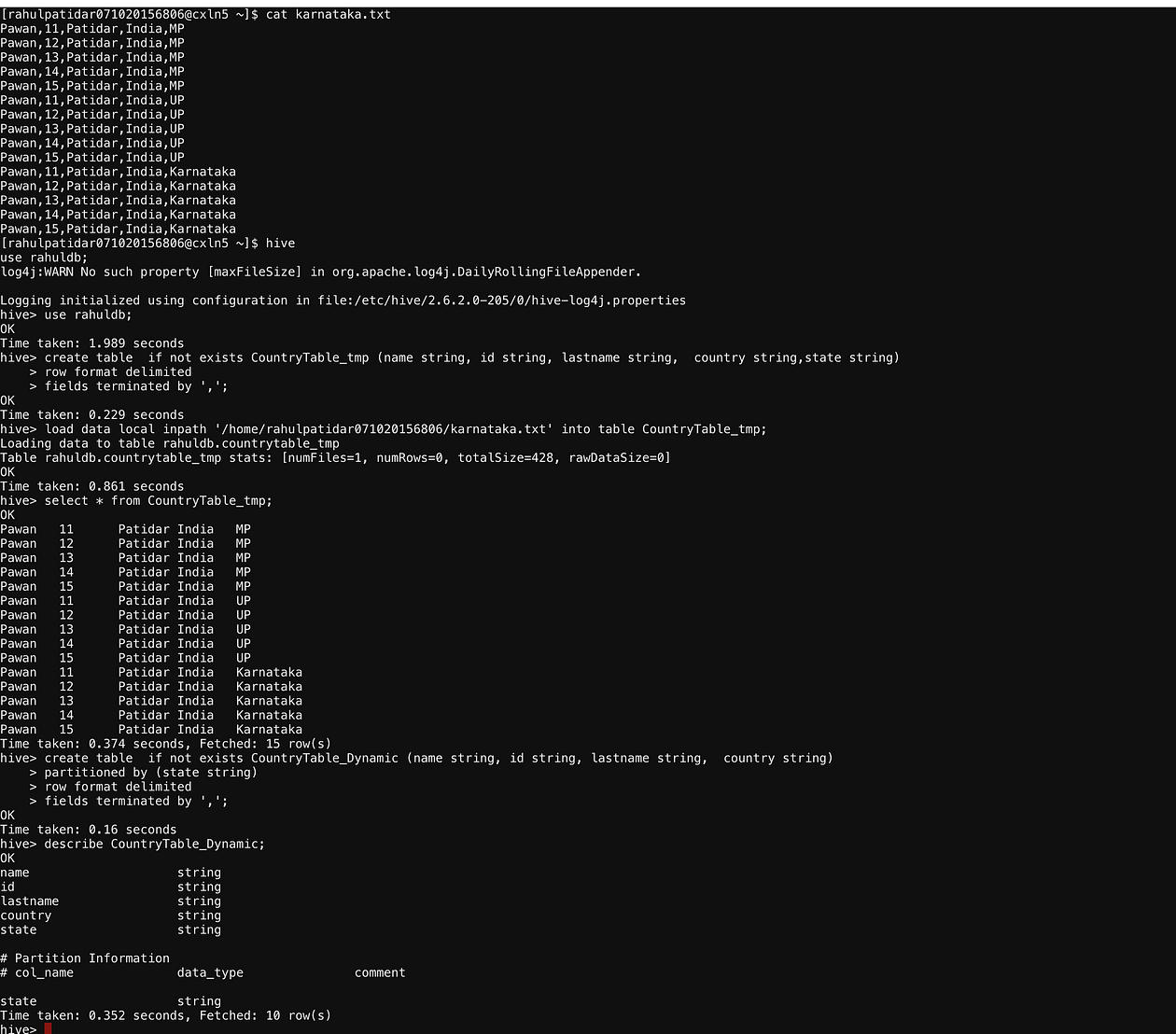
cat karnataka.txt
Pawan,11,Patidar,India,MP
Pawan,12,Patidar,India,MP
Pawan,13,Patidar,India,MP
Pawan,14,Patidar,India,MP
Pawan,15,Patidar,India,MP
cat UP.txt
Pawan,11,Patidar,India,UP
Pawan,12,Patidar,India,UP
Pawan,13,Patidar,India,UP
Pawan,14,Patidar,India,UP
Pawan,15,Patidar,India,UP
cat Karnataka.txt
Pawan,11,Patidar,India,Karnataka
Pawan,12,Patidar,India,Karnataka
Pawan,13,Patidar,India,Karnataka
Pawan,14,Patidar,India,Karnataka
Pawan,15,Patidar,India,Karnataka
// create Non-Partition Table
create table if not exists CountryTable_tmp (name string, id string, lastname string, country string,state string) row format delimited fields terminated by ','; // load data into non-partition table load data local inpath '/home/rahulpatidar071020156806/karnataka.txt' into table CountryTable_tmp; // create partition table create table if not exists CountryTable_Dynamic (name string, id string, lastname string, country string) partitioned by (state string) row format delimited fields terminated by ',';/ /enable dynamic partition properties set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; //Verify Partition Column describe CountryTable_Dynamic; //Insert data from non-partition to partition table. insert into CountryTable_Dynamic partition(state) select name, id, lastname, country, state from CountryTable_tmp; //verify data. show partitions CountryTable_Dynamic;
select * from CountryTable_Dynamic; select * from CountryTable_Dynamic where state='MP'; !hadoop fs -ls /apps/hive/warehouse/rahuldb.db/CountryTable_Dynamic/;

Static VS Dynamic Partitioning
1. Partition Creation
Static: We need to manually create each partition before inserting data into a partition.
Dynamic: Partitions will be created dynamically based on input data to the table.
2. Suitable for
Static: We need to know all partitions in advance. So it is suitable for use cases where partitions are defined well ahead and are small in number
Dynamic: Dynamic partitions are suitable when we have a lot of partitions and we can not predict in advance new partitions, ahead of time.
3. Examples
Static: Departments, State Names, etc.
Dynamic: Date, city names etc.
4. Performance
Static: Fast as compared to Dynamic because we are telling what to do.
Dynamic: Slow as compared to Static as the system needs to decode at run time based on data and generate Partition
Bucketing In Hive
- In the above example lets consider instead of Department, if want to want to distribute data on a different column, consider we need to do it based on some ID column then if there are 1000 distinct rows then it will create 1000 partitions and Hdfs location multiple Part files will be created and it will be difficult to manage multiple Partitions Files, So partitions work well when we have less no of distinct values like Dept or State etc.
- Now Consider we have the states UP and Goa, In that case, let’s say if for UP we have 10 Million records are there are for Goa has 1 Million records then the no of Records in each partition will not be the same all the times, Hive will distribute the data based on Partition column No matter if one partition has 10 Million and other has 10 records.
- Now Consider we have a requirement where we need to scan data based on the ID column.
select * from CountryTable_Dynamic where ID='11';
Now here to find the ID=11 it will scan the all the PartitionColumn and we will not be able to use the functionality of hive since it will work like a normal(non-partition) table and will scan complete data, and let’s say if we do partition here on ID column then in that case it can lead to so many partitions, if we have 1000 records for ID=’11′ then it will scan 1000 partitions.
What is the Solution to the above Problems?
To avoid the above problems we can use Bucketing concepts in a hive which will make sure that data will distribute equally among all the buckets.
The bucketing in Hive is a data organizing technique. It is similar to partitioning in Hive with an added functionality that it divides large datasets into more manageable parts known as buckets. So, we can use bucketing in Hive when the implementation of partitioning becomes difficult. However, we can also divide partitions further in buckets.
we need to define no of Buckets while creating the Table and it will be fixed and the hive will divide data into this fixed no of Buckets.
How Bucket Divides Data?
The concept of bucketing is based on the hashing technique.
Here, modules of the current column value and the number of required buckets are calculated (let’s say, F(x) % 3).
Now, based on the resulted value, the data is stored in the corresponding bucket.
Let's say We have created 3 bucket on ID column and we have 10000 records buckets.then hive will divide data as below.1%3=1st buckets 2%3=2nd buckets 3%3=0th buckets 4%3=1st buckets 5%3=2nd buckets 6%3=0th buckets . . . . . . . 10000%3=1st bucketsThis is hive will distribute the data into 3 buckets(0,1,2)

So when the no of distinct Values is high then we can use the concept of hive bucket and distribute the data among a fixed no of buckets.
How to Use Partition and Together?
we can also divide partitions further into buckets, So here Bucket will work as a file inside the partition Directory.
Consider we have a partition on state UP and we have used 4 Bucket on ID Column then hive will divide Partition into 4 buckets based on ID, so in an earlier case(Partition) if we have 10 million records in partition then hive bucket will divide it into 4 buckets and distribute 2.5 million records in each bucket file.
Data will Look Like the below at hdfs.
/apps/hive/warehouse/rahuldb.d/Country_Table/partition=UP/bucket_0_file /apps/hive/warehouse/rahuldb.d/Country_Table/partition=UP/bucket_1_file /apps/hive/warehouse/rahuldb.d/Country_Table/partition=UP/bucket_2_file /apps/hive/warehouse/rahuldb.d/Country_Table/partition=UP/bucket_3_file
Now Based On Bucketing Concept Hive will understand which ID is available in which bucket.
so if we fire queries like:
select * from Country_Table where partition=’UP’ and ID=’3';
above query will first go on partition=’UP’ and will see ID=’3′, in the next condition, it will apply 3%3=0 and will get to know that it will be in the 0th bucket, so instead of searching complete partition=’UP’ partition, it will just scan a bucket inside partition=UP and will give the result.
let’s follow the same process which we followed earlier in the case of dynamic Partitions.
1. Create a Normal-table(without Bucket),can use the existing one.
2. Load data into Non Bucketing Table
3. Create new table with Bucket.
4. Insert data from non-bucket to Bucket Table.
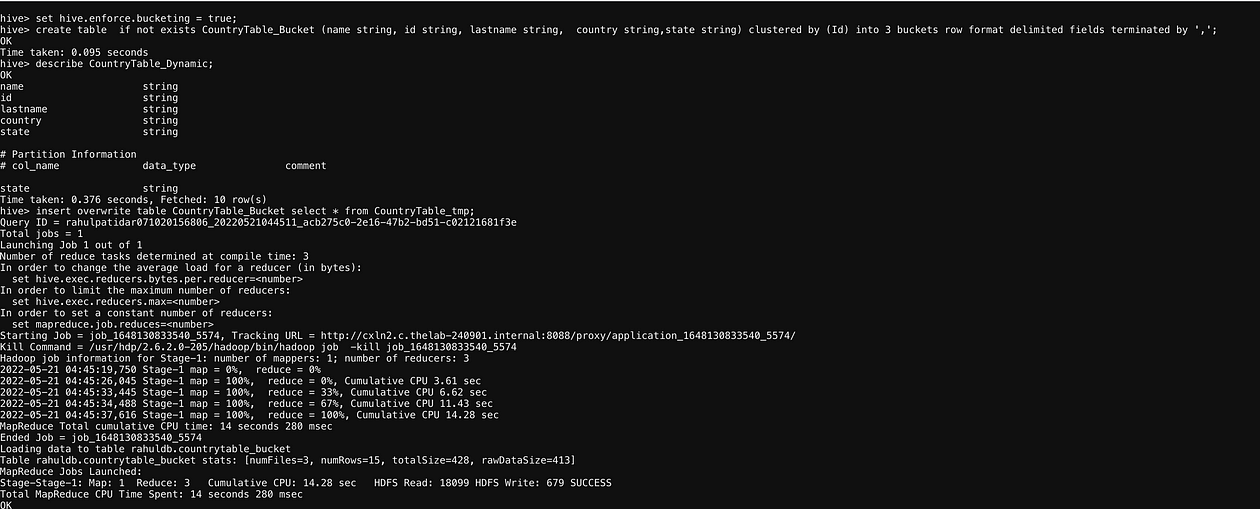
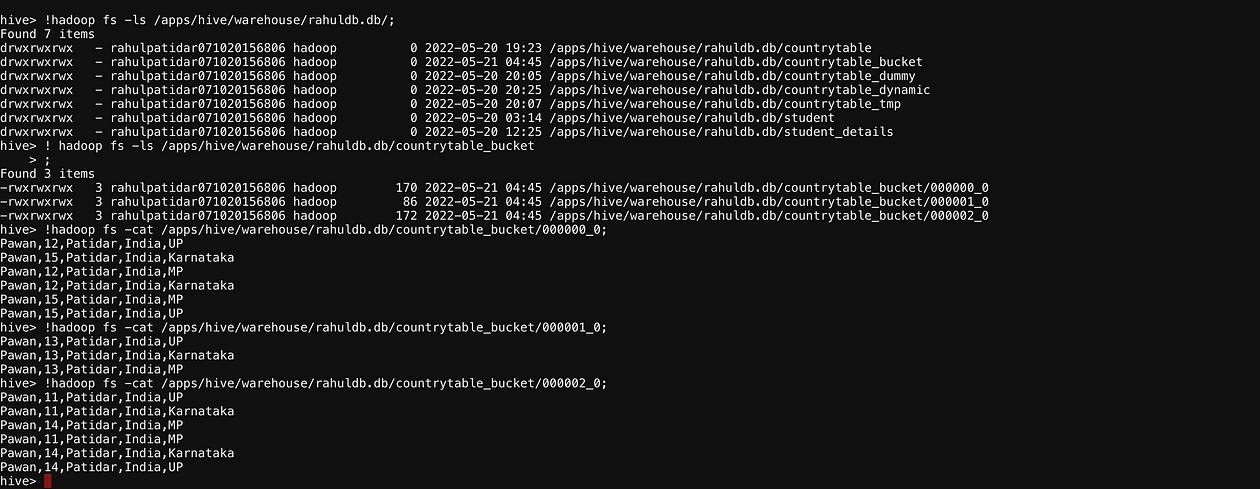
We need to use Below Property to use concept of Bucketing.set hive.enforce.bucketing = true;cat karnataka.txtPawan,11,Patidar,India,MP Pawan,12,Patidar,India,MP Pawan,13,Patidar,India,MP Pawan,14,Patidar,India,MP Pawan,15,Patidar,India,MP Pawan,11,Patidar,India,UP Pawan,12,Patidar,India,UP Pawan,13,Patidar,India,UP Pawan,14,Patidar,India,UP Pawan,15,Patidar,India,UP Pawan,11,Patidar,India,Karnataka Pawan,12,Patidar,India,Karnataka Pawan,13,Patidar,India,Karnataka Pawan,14,Patidar,India,Karnataka Pawan,15,Patidar,India,Karnataka// create Non-Bucket Table (Can use Existing)create table if not exists CountryTable_tmp (name string, id string, lastname string, country string,state string) row format delimited fields terminated by ',';// load data into non-Bucket table (Can use Existing)load data local inpath '/home/rahulpatidar071020156806/karnataka.txt' into table CountryTable_tmp;//enable Bucketing propertiesset hive.enforce.bucketing = true;// create partition tablecreate table if not exists CountryTable_Bucket (name string, id string, lastname string, country string,state string) clustered by (Id) into 3 buckets row format delimited fields terminated by ',';describe CountryTable_Dynamic;//Insert data from non-bucket to partition table.insert overwrite table CountryTable_Bucket select * from CountryTable_tmp;//verify data.Now as per the Bucketing Function we should have.11%3=2 12%3=0 13%3=1 14%3=2 15%3=0So, Bucket 0 should hold ID:12,15 Bucket 1should hold ID:13 Bucket 2 should hold ID:11,14! hadoop fs -ls /apps/hive/warehouse/rahuldb.db/countrytable_bucket;
Partition & Bucket Example
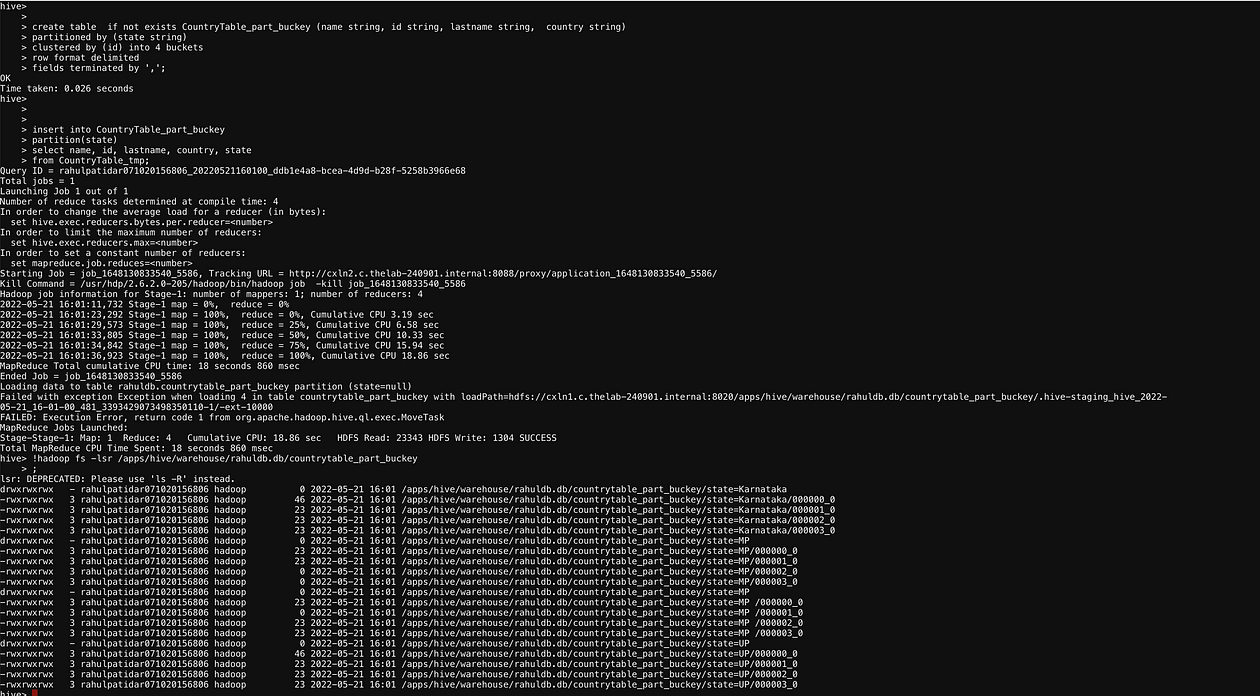
The below Example is exactly the same as the above only we are adding one extra partitioned by (state string) property which first crate the partition and on top of the partition will again create a bucket which will split the partition’s data into buckets.
set hive.enforce.bucketing = true; set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict;create table if not exists CountryTable_part_buckey (name string, id string, lastname string, country string) partitioned by (state string) clustered by (id) into 4 buckets row format delimited fields terminated by ',';insert into CountryTable_part_buckey partition(state) select name, id, lastname, country, state from CountryTable_tmp;
Differences Between Hive Partitioning vs Bucketing
Partitioning
A directory is created on HDFS for each partition and these partition directories will contain part files to store actual data. .i.e. partition=UP/part_file1.txt
we can have one or more Partition columns. i.e partitioned by (year string, month string).
we can’t manage the number of partitions to create, hive will create partitions based on the distinct values in the partition Column.
We can not create partitions on buckets.
Need to use Uses PARTITIONED BY to create Partitions.
No Guarantee to distribute data equally among all the partitions.
Bucketing
A file is created on HDFS for each Bucket. i.e. bucket_file0
You can have only one Bucketing column.
we can manage the number of buckets to create by specifying the count. i.e clustered by (id) into 4 buckets
Bucketing can be created on a partitioned table
Need to use Uses CLUSTERED BY to create buckets.
Guarantee to distribute data equally among all the buckets using hash Function.
Query Level Optimisation
At the Query level, usually, complex join takes a lot of time which needs to optimize at the query level.
1. Hive works on the map-reduce Job Concept so whenever we submit a hive query basically it will submit an MR job to the cluster and then this map-reduce job will execute on the cluster and will give us the result.
2. This Map-reduce Job will depend on the of join columns for a single join it will create a single MR job.
No. of join column=No. of MR Jobs
So, we should always try to decrease No. Of Join column as this will decrease the MR Job and will execute query fast.
3. We should always try to partition and bucket on the Join column, so it will join only on a subset of data and this will Improve our hive join performance.
Partition and Bucketing On Join Column
Whenever we submit any Join Query it will execute Map-Reduce Job, where Reduce Job takes time since it will do Shuffle, Sort and Combine process we so should try to do all the things on the Map side, this will help execute our job without the reducer. In Hive, we can use the functionality of map-side Join where Mapper will only execute.
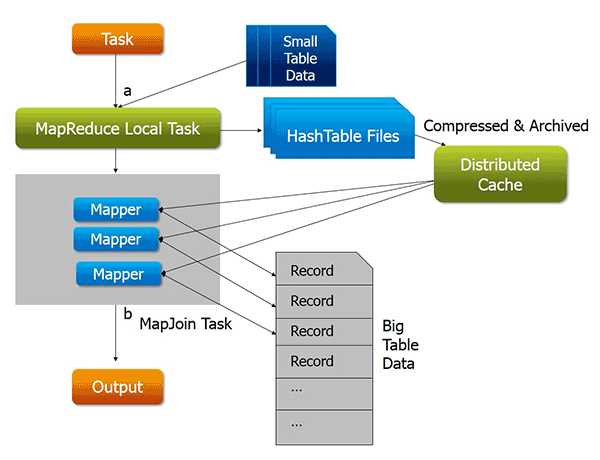
Map-Side Join
Apache Hive Map Join is also known as Auto Map Join, or Map Side Join, or Broadcast Join. we use Hive Map Side Join when one of the tables in the join is a small table and can be loaded into memory. So that a join could be performed within a mapper without using a Map/Reduce step.
In Map-side Join a local MapReduce Task will Execute.
– MapReduce local task will create a small hash table for the small table.
— This small hash table will move at the HDFS location.
– From HDFS this hash table will be broadcasted to all the nodes and will be available local disk of each node.
– Then from the local node, a Small table will be available in memory.
– Now Actual MapReduce Job Will Start which contains only Mapper tasks.
Condition For Map-side Join
One big and One small table should be Available do Map-side Join.
The small Table should be the secondary Table. i.e If you want to do left join then the right table should be small.
The default size for the small table is 25 MB. It Should be less than or equal to 25 Mb so we can load it into Memory. We can change this default size.
we can never convert Full outer joins to map-side joins.
Parameters of Hive Map Side Join
hive> set hive.auto.convert.join=true; hive> set hive.auto.convert.join.noconditionaltask=true; hive> set hive.auto.convert.join.noconditionaltask.size=20971520 hive> set hive.auto.convert.join.use.nonstaged=true; hive> set hive.mapjoin.smalltable.filesize = 30000000;
Now If we do the join b/w table then it will automatically be converted into map-side Join and a small table will be available in memory and only the mapper will execute.
select a.* from Departments Dept, IT_Dept IT_D where Dept.Dept_Id=IT_D.IT_ID;
Here my Department table is a big table which holds data for all the departments and the IT_Dept table is a small table which will load into memory.
Bucket Map-side Join
Bucket Map-side Join Process is exactly the same as Map-side Join, The only difference is in the last step where instead of loading a complete table in memory it will just load a required bucket in memory which is required.
– On the Bucket Map-side Join a local MapReduce Task will Execute this task will create a small hash table for the small table.
– This small hash table will move at the HDFS location.
– From HDFS this hash table will be broadcasted to all the nodes and will be available local disk of each node.
– Now Actual MapReduce Job Will Start which contains only Mapper tasks.
Conditions of Bucket Map-side Join
– Unlike Map-side Join we can Apply Bucket Map-side Join on 2 big tables also.
-Tables should be bucketed on Join Column.
– one table should have buckets in multiples of the number of buckets in another table in this type of join.
-For suppose if one table has 2 buckets then the other table must have either 2 buckets or a multiple of 2 buckets (2, 4, 6, and so on). Further, since the preceding condition is satisfied then the joining can be done on the mapper side only.
set hive.enforce.bucketing = true; set hive.optimize.bucketmapjoin=true;
SMB (Sort Merge Bucket Join)
– The Process of SMB Join is the same as Bucket Map-side Join.
– SMB Works can also be on 2 Big tables.
-Tables should be bucketed on Join Column.
– Number of Should be exactly the same in both the tables.
– Both the table should be sorted on Join Column.
As the Join Column data is in a sorted manner and the number of the bucket is also the same in both the tables, so this join will take the least time to join since it will do one to one bucket join. i.e. It will store data in a sorted manner so let’s say if, in bucket_1, it has id 1, then in table 2 also id 1 will be available in bucket_1, so hive will just join bucket_ 1 from both the tables.
Example of Map-side Join
Let’s try to understand the Map-side Join process by an example and we will see how actually it helps us to improve our join query performance.
Steps
To Perform Map-side Join we need one small and one big table, so we will create 2 tables, where the small table size we less than or equal to 25 MB.
Now disable the map-side join property.
Try to run the join query.
Enable the map-side join property.
Try to run the same join query again.
HDFS Files Screenshots

Tables Count
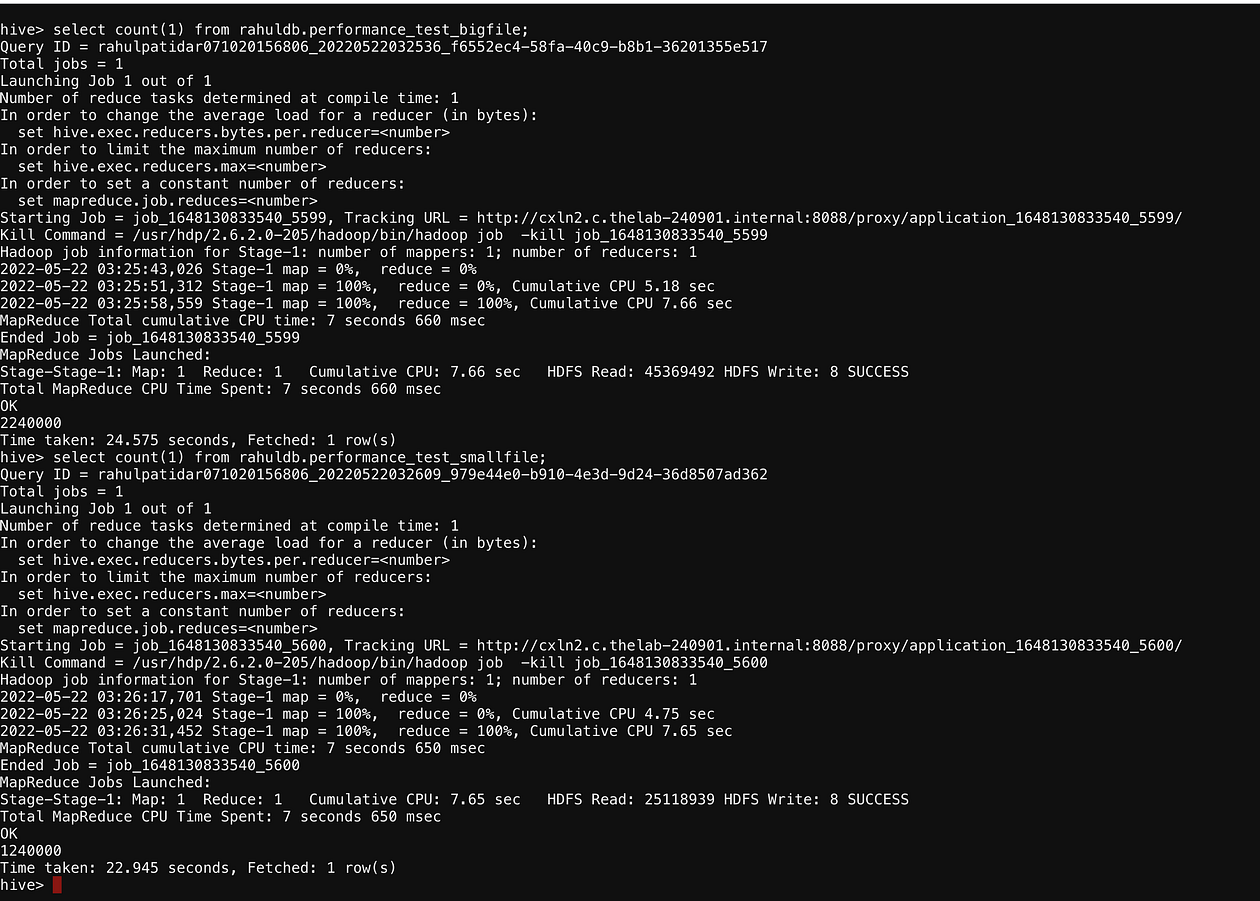
Create Statements for Tables
create table if not exists rahuldb.performance_test_bigfile (id Int,name string,salary string,company string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ lines terminated by ‘n’ stored as textfile location ‘/user/rahulpatidar071020156806/bigfile/’ TBLPROPERTIES (“skip.header.line.count”=”1");create table if not exists rahuldb.performance_test_smallfile (id Int,name string,salary string,company string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ lines terminated by ‘n’ stored as textfile location ‘/user/rahulpatidar071020156806/smallfile/’ TBLPROPERTIES (“skip.header.line.count”=”1");//Check the value of property hive.auto.convert.join and disable it.set hive.auto.convert.join; set hive.auto.convert.join=false; set hive.auto.convert.join;
Now Execute Join Query:
SELECT c.name, o.company FROM rahuldb.performance_test_bigfile o JOIN rahuldb.performance_test_smallfile c ON (o.company = c.company) limit 10;
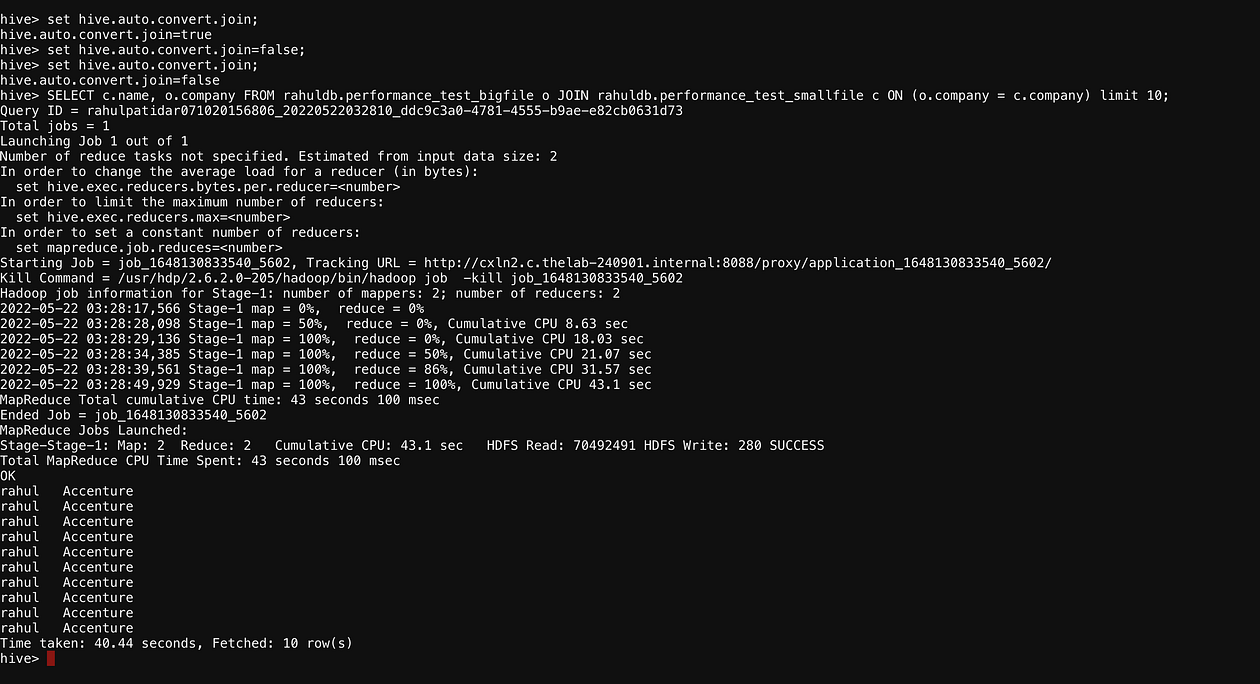
We can see here that reducers are also executing here.
Time Take: 40.44 seconds
Now enable map-side Join properties.
set hive.auto.convert.join; set hive.auto.convert.join=true; set hive.auto.convert.join;//Execute the same join Condition Again.SELECT c.name, o.company FROM rahuldb.performance_test_bigfile o JOIN rahuldb.performance_test_smallfile c ON (o.company = c.company) limit 10;
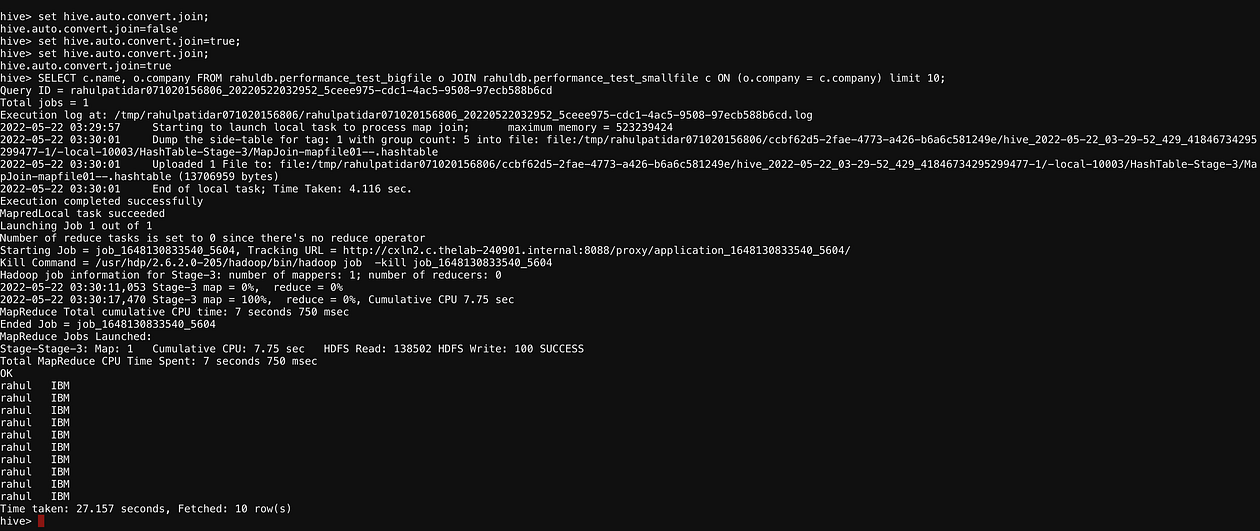
Now we can Observe that only the mapper is executed and no reducers are Involved here.
Time Taken: 27.157 seconds.
Conditions for Bucket Map join
Both the tables should be bucketed on the join column.
The number of buckets in the larger table should be an integral multiple of the number of buckets in the smaller table.
Note: Here both the tables can be large as well. So let us try to see an example. We need to create 2 tables bucked on join column. We need to set the below property set hive. enforce.bucketing=true;
set hive.enforce.bucketing=true;CREATE external TABLE rahuldb.performance_test_bigfile_bucket_Map(id Int,name string,salary string,company string) clustered by(company) into 4 buckets row format delimited fields terminated BY ','; insert into performance_test_bigfile_bucket_Map select * from performance_test_bigfile;CREATE external TABLE rahuldb.performance_test_smallfile_bucket_Map(id Int,name string,salary string,company string) clustered by(company) into 8 buckets row format delimited fields terminated BY ','; insert into performance_test_smallfile_bucket_Map select * from performance_test_smallfile;SELECT c.name, o.company FROM rahuldb.performance_test_bigfile_bucket_Map o JOIN rahuldb.performance_test_smallfile_bucket_Map c ON (o.company = c.company) limit 10;
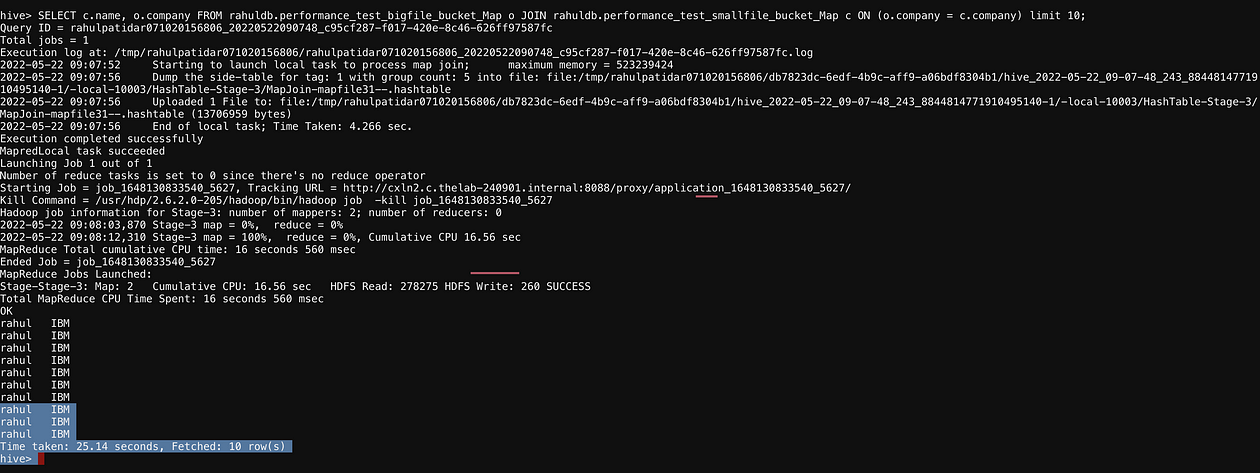
SMB Join
Additional Condition for SMB Join
The number of Buckets Should be equal in both the tables.
Data in both tables should be sorted based on the join column
set hive.auto.convert.sortmerge.join=true; set hive.auto.convert.sortmerge.join.noconditionaltask=true; set hive.optimize.bucketmapjoin=true; set hive.optimize.bucketmapjoin.sortedmerge=true; set hive.enforce.bucketing=true; set hive.enforce.sorting=true; set hive.auto.convert.join=true;CREATE external TABLE rahuldb.performance_test_bigfile_SMB(id Int,name string,salary string,company string) clustered by(company) sorted by(company asc) into 4 buckets row format delimited fields terminated BY ','; insert into performance_test_bigfile_SMB select * from performance_test_bigfile;CREATE external TABLE rahuldb.performance_test_smallfile_SMB(id Int,name string,salary string,company string) clustered by(company) sorted by(company asc) into 4 buckets row format delimited fields terminated BY ','; insert into performance_test_smallfile_SMB select * from performance_test_smallfile;SELECT c.name, o.company FROM rahuldb.performance_test_bigfile_SMB o JOIN rahuldb.performance_test_smallfile_SMB c ON (o.company = c.company) limit 10;
Simplifying Query Expression
After doing design level query level Optimisation we can also Simplify Query Expression and Improve the performance in the hive, and this we can do using the window function in the hive. This process just Simplifies Queries so we can write complex queries in a simple manner, this will not give much time difference but it will simplify our query.
Let’s Say If we want to do find the IPL player who is the highest scorer in last week.
so basically here we need to use 2 properties.
Window Size: Here we are only interested in the last week’s data, so this size will be 7 days.
Windows Operation: Here we will perform the operation which we want, so Rank will be a Windows Operation here.

Question: Find the sum of runs of batsmen after Every Match.
Solution
create external table if not exists rahuldb.performance_test_Windows (name string,runs Int,Match string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’ lines terminated by ‘n’ stored as textfile location ‘/user/rahulpatidar071020156806/windows/’ TBLPROPERTIES (“skip.header.line.count”=”1");from rahuldb.performance_test_Windows select Batsman,runs, match,sum(runs) over (order by Match rows between unbounded preceding and current row) as total_runs;Operation: sum(runs) order by Match : I want to sort the data based on match Number. unbounded preceding : First Row of Table. current row : Want to update data after every row.Here my Window size is : from first row to current row, and operation is sum of runs.
Question: Find the sum of runs for every Batsman after each match.
solution: Query Will be exactly the same Just we need to use Partition by in the existing Query:
create external table if not exists rahuldb.performance_test_Windows_Part
(name string,runs Int,Match string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
lines terminated by 'n'
stored as textfile
location '/user/rahulpatidar071020156806/windows2/'
TBLPROPERTIES ("skip.header.line.count"="1");from rahuldb.performance_test_Windows_Part select name as Batsman,runs, match,sum(runs) over (partition by name order by Match rows between unbounded preceding and current row) as total_runs;

So this was all about Hive Optimisation Techniques, which we can use to optimize Hive Queries. Other than these optimisation Techniques we can also use different kind of file formats which stores data in row and column.
In Row-based file format writing is quite simple, you just need to append the data at the end, but reading is difficult because you need to read from multiple places.
In column-based file format, writing is difficult, you just need to write in multiple places, but reading is simple because you need to read from one place.
Types of file Format

In the above screenshot, we can see that whenever new data come in row-based file format it will just append at the end and will not take much time, but when we try to read the data it needs to scan the entire row to select the data, let’s say if we have 100+ columns and we want data only for 2 columns to fetch these 2 columns data hive need to scan entire row(100+) column then will fetch the data and will show the output.
In the later Scenario(column-based file format), whenever we want to write the data it’s stored based on a column.
let’s say we have two rows with empid, name, salary and below data in that
1,rahul,1000
2,Sonu,2000
Above data in Row-based file format
1,rahul,1000 2,Sonu,2000
Above data in column-based file format
1 2,rahul sonu,1000 2000
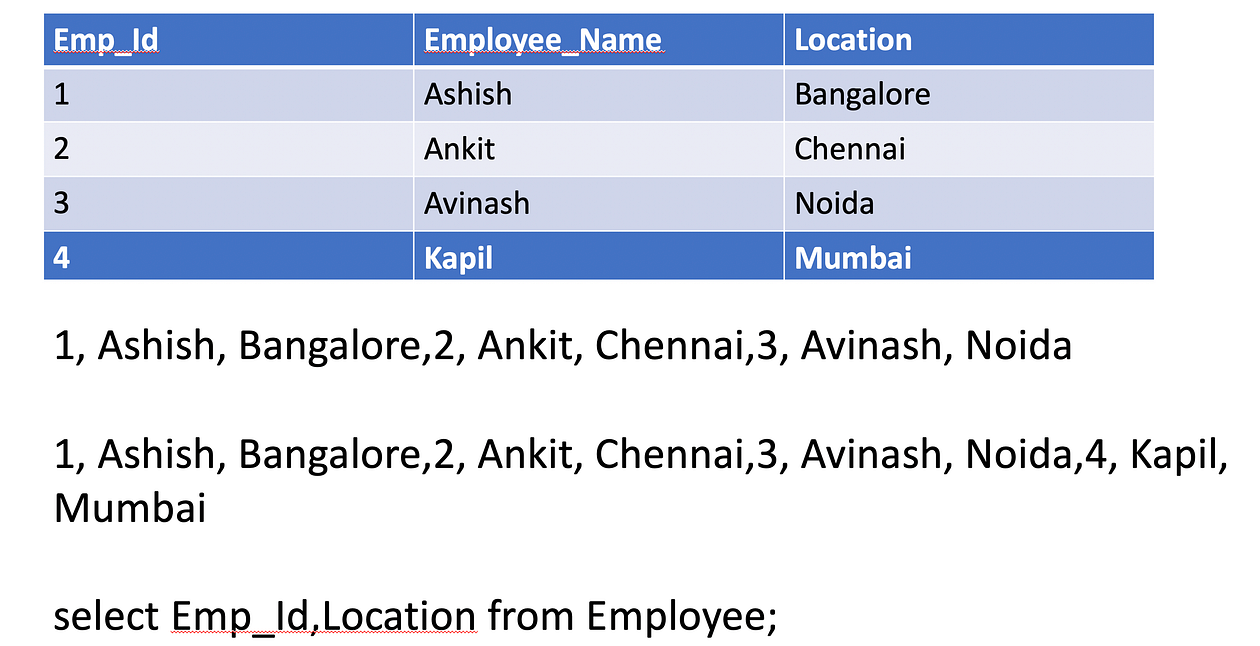
So in column-based file format hive first stores data for empid at the same place, then name and then salary, so basically to write the data it needs to go at multiple places, but for reading can select from a single place. Suppose I want to select only empid from the table then it will go only first place where empid is available and show the result.
Example Of Row Based File Format:
Example Of Column Based File Format:

Few Analytical Function in the hive( NOT RELATED TO HIVE OPTIMISATION)
Rank(): gives the ranking within the ordered partition. Same values(ties) are assigned same rank with next rankings are skipped.
let say if we have salaries 1000,1000,2000 then rank will assign 1,1,3 since first 2 salaries are same so it will skip 2nd rank and will assign 3 rank to 3 rd salary.
DENSE_RANK() : It is similar to RANK, but leaves no gaps in the ranking sequence when there are ties.
let say if we have salaries 1000,1000,2000 then rank will assign 1,1,2 ,it will not skip sequence and will assign 2nd to 3rd salary.
ROW_NUMBER() : assigns a unique sequence number starting from 1 to each row.
let say if we have salaries 1000,1000,2000 then rank will assign 1,2,3 ,it will not skip sequence and will assign 2nd to 3rd salary.
lead(): The number of rows to lead can optionally be specified. If the number of rows to lead is not specified, the lead is one row.
let say if we have salaries 1000,2000,3000 then lead() will assign 2000,3000, null .It will give the value of next row.
leg(): The number of rows to leg can optionally be specified. If the number of rows to leg is not specified, the leg is one row.
let say if we have salaries 1000,2000,3000 then leg() will assign null,1000,2000, null .It will give the value of next row.
cat /home/rahulpatidar071020156806/windows.txtID,Department,name,salary
1,IT,Rahul,10000
2,IT,Umesh,10000
3,IT,Avinash,20000
4,sales,Ashish,30000
5,sales,Sonu,40000
6,research,Kapil,40000
7,Acting,Ankit,50000
8,HR,Jagadeesh,50000
9,HR,Surya,60000
10,Management,Satya,70000create table if not exists rahuldb.Employee_Test
(id Int,Department string,name string,salary string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
lines terminated by 'n'
stored as textfile
TBLPROPERTIES ("skip.header.line.count"="1");load data local inpath '/home/rahulpatidar071020156806/windows.txt' into table rahuldb.Employee_Test;select ID as ID,Department as dept,name as name,salary as salary from rahuldb.Employee_Test order by salary;select ID as id ,Department as dept,name as name,salary as salary,
rank() over(order by salary) rnk,
dense_rank() over(order by salary) d_rnk,
ROW_NUMBER() over(order by salary) rno,
lead(salary) OVER (ORDER BY salary) as leadVal,
LAG(salary) OVER (ORDER BY salary) as lagval
from rahuldb.Employee_Test order by salary;
select ID as ID,Department as dept,name as name,salary as salary from rahuldb.Employee_Test order by salary;

{kind=link}
select ID as id ,Department as dept,name as name,salary as salary, rank() over(order by salary) rnk, dense_rank() over(order by salary) d_rnk, ROW_NUMBER() over(order by salary) rno, lead(salary) OVER (ORDER BY salary) as leadVal, LAG(salary) OVER (ORDER BY salary) as lagval from rahuldb.Employee_Test order by salary;
Conclusion on Hive Advance
Partitioning/Bucketing and Join Optimisations are the most important topics in the Hive and it is used to improve the performance of queries. In this post, We have learned all kinds of performance Optimisation Techniques. We will learn more about hive in the next Post.
Happy Learning !!!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.