



{kind=link}
Introduction
Discover the ultimate guide to building a powerful data pipeline on AWS! In today’s data-driven world, organizations need efficient pipelines to collect, process, and leverage valuable data. With AWS, you can unleash the full potential of your data.
In this blog post, we will take you on a journey through the architecture and implementation of an end-to-end data pipeline on AWS. We will explore the three main stages of the pipeline: data collection, training endpoint, and prediction endpoint. Each stage plays a vital role in the overall pipeline, contributing to the successful extraction of insights from your data.
Learning Objectives
- Understand the benefits of breaking down a data pipeline into stages, including easier management and troubleshooting.
- Learn how to set up an AWS environment for a data pipeline project, including creating an S3 bucket, EC2 instance, and ECR.
- Become familiar with GitHub Actions and how to use them to automate deployment to AWS.
- Learn how to structure code for a data pipeline project, including organizing scripts and workflows into separate stages.
- Understand the costs associated with running a data pipeline on AWS, including storage and data transfer fees.
This article was published as a part of the Data Science Blogathon.
Table of contents

Benefits of Breaking Down a Data Pipeline into Stages
Increased Efficiency
By dividing the pipeline into smaller, more manageable stages, you can improve the overall efficiency of the pipeline. Each stage can be optimized to perform its specific function more efficiently, leading to faster processing times and better use of resources.
Improved Scalability
As the volume of data increases, it becomes more challenging to process and analyze it efficiently. By breaking down the pipeline into stages, you can scale each stage independently based on the specific needs of that stage. This allows you to add more resources to a particular stage if needed, without affecting the performance of the other stages.
Greater Flexibility
Dividing the pipeline into stages allows you to modify or replace a particular stage without affecting the entire pipeline. This makes it easier to make changes or improvements to the pipeline as your needs change or new technologies become available.
Easier Testing and Debugging
By breaking down the pipeline into stages, you can isolate problems to a specific stage, making it easier to test and debug the pipeline. This helps to identify and fix problems more quickly, reducing downtime and improving overall pipeline performance.
Split the Pipeline into Three Stages
First Stage – Data Collection Stage
In this stage, we’ll focus on collecting and storing the data we need to build our pipeline. We’ll use an AWS S3 bucket to store the data, and we’ll also send the data labels to MongoDB. Additionally, we’ll create a logger and exception handling to ensure that the data is collected and stored correctly.
Second Stage – Training Endpoint Stage
In this stage, we’ll train our model using the collected data. We’ll use Amazon SageMaker to train our model and create an endpoint that can be used for inference.
Third and Final Stage – Prediction Endpoint Stage
In this stage, we’ll deploy our model to a production environment. We’ll create a Docker image of our model and deploy it to Amazon Elastic Container Service (ECS) using Amazon Elastic Container Registry (ECR). Finally, we’ll create a prediction endpoint that can be used to make predictions based on new data.
By breaking the pipeline down into these three stages, we can ensure that each stage is completed before moving on to the next, making it easier to manage the entire workflow from start to finish.
Data Collection and Preprocessing
In the data collection stage of our end-to-end data pipeline project, we aim to collect and upload data to an AWS S3 bucket. This stage is critical as it serves as the foundation for our entire data pipeline. In this section, we will explain how to upload data to an S3 bucket using sync and highlight why we did not use boto3.
Uploading Data to S3 Bucket Using Sync
We begin by creating an S3 bucket in the AWS console, or programmatically using the AWS CLI. Once the bucket is created, we can use the AWS CLI to upload our data to the S3 bucket using the
sync command. The sync command is used to synchronize files between a local directory and an S3 bucket, and it works by comparing the contents of the source and destination, and then uploading only the changed or new files. This can save time and bandwidth when uploading large datasets.
Here is an example command to upload data to an S3 bucket using the sync command:
aws s3 sync /path/to/local/directory s3://your-s3-bucket-nameIn the above command, /path/to/local/directory is the local directory where your data is stored, and s3://your-s3-bucket-name is the S3 bucket name where you want to upload your data.
Here is a sample code :
def sync_data(self):
try:
print("\n====================== Starting Data sync ==============================\n")
os.system(f"aws s3 sync {self.images} s3://image-database-01")
print("\n====================== Data sync Completed ==========================\n")
except Exception as e:
raise SensorException(e, sys)
# message = CustomException(e, sys)
# return {"Created": False, "Reason": message.error_message}#import csvThe best practice when working with AWS is to keep all the sensitive information, such as AWS access keys and secret keys, in environment variables instead of hardcoding them in your code. This ensures that your credentials is secure and not accidentally exposed in your codebase.
To use environment variables in your code, you can create a .env file that contains the necessary values and use a package like dotenv to load them into your application at runtime. Here’s an example of what your .env file might look like:
AWS_ACCESS_KEY_ID=your_access_key_here
AWS_SECRET_ACCESS_KEY=your_secret_key_here
AWS_REGION=us-west-2
MY_BUCKET_NAME = image-database-01You can then load these values in your code like this:
import os
aws_access_key_id = os.environ.get("AWS_ACCESS_KEY_ID")
aws_secret_access_key = os.environ.get("AWS_SECRET_ACCESS_KEY")
aws_region = os.environ.get("AWS_REGION")
bucket_name = os.environ.get('MY_BUCKET_NAME')Note that you should never commit your .env file to source control or share it with others, as it contains sensitive information. Instead, you should keep it on your local machine or in a secure location such as a password manager.
By following this best practice, you can ensure that your AWS credentials are kept secure and your application is less vulnerable to security threats.
Why Did We Not Use Boto3?
While boto3 can be used to upload data to an S3 bucket, it requires additional setup and configuration. Using the AWS CLI sync command is a simpler and more straightforward approach, especially for smaller projects. Here’s an example of how to upload data to S3 bucket using boto3:
import boto3
def boto3():
try:
s3_client = boto3.client('s3')
s3_client.upload_file('/path/to/local/file', 'your-bucket-name', 'your-s3-key')
except Exception as e:
raise SensorException(e, sys)
Storing Labels or Metadata in MongoDB
After the data is uploaded to the S3 bucket, we can also store the labels or metadata associated with the data in a MongoDB database. This can be done using the PyMongo library, which allows us to interact with MongoDB from Python.
import pymongo
def MongodbClient():
try:
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["mydatabase"]
collection = db["mycollection"]
data = {"filename": "data_file.csv", "label": "positive"}
collection.insert_one(data)
except Exception as e:
raise SensorException(e, sys)
Implementing Logger and Exception Handling
In addition, we implemented a logger and exception handling to help with debugging and troubleshooting during the data collection stage. This is especially important when dealing with large datasets that may encounter errors or exceptions during the upload process.
import logging
logging.basicConfig(filename='data_collection.log', level=logging.DEBUG)
try:
# upload data to S3 bucket
awscli_command = 'aws s3 sync /path/to/local/directory s3://your-s3-bucket-name'
subprocess.check_call(awscli_command.split())
except subprocess.CalledProcessError as error:
logging.error('Error occurred during data upload: {}'.format(error))
#import csvArchitecture of our end-to-end data pipeline on AWS, we have created the following diagram:
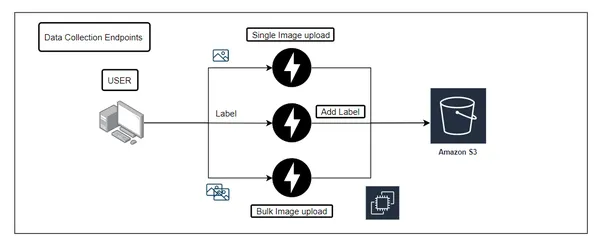
This diagram shows the flow of data in our pipeline, starting with the data collection stage. In this stage, data is collected from various sources and uploaded to an S3 bucket, where it is labeled and stored in a MongoDB database. We have also implemented a logger and exception handling to ensure the smooth flow of data.
The next stage is the training endpoint, where the data is preprocessed and trained using various algorithms. Once the training is complete, the model is saved and uploaded to an S3 bucket.
Finally, the prediction endpoint uses the trained model to make predictions on new data. The predictions are then stored in another MongoDB database.
To ensure seamless integration and deployment of our pipeline, we have used Docker and GitHub Actions. Our code is stored in a GitHub repository, and we have used GitHub workflows to automate the build and deployment process. We have also used AWS ECR and EC2 instances to deploy our pipeline.
By following this architecture, we can unlock the full potential of our data and leverage it to make better decisions and gain valuable insights.
Requirements
Here are the requirements for setting up the data pipeline:
- AWS Account: You will need an AWS account to set up the data pipeline.
- GitHub Account: You will need a GitHub account to create a repository and configure secrets for the pipeline.
- EC2 Instance: You will need an EC2 instance to run the data pipeline.
- S3 Bucket: You will need an S3 bucket to store the raw data and processed data.
- MongoDB: You will need a MongoDB instance to store the data after processing.
- Elastic Container Registry: You will need an ECR to store the Docker images used in the pipeline.
- Docker: You will need to have Docker installed on the EC2 instance to run the pipeline.
- Python: You will need to have Python installed on the EC2 instance to run the pipeline.
How to Set the Code?
1. First, create a repository on GitHub
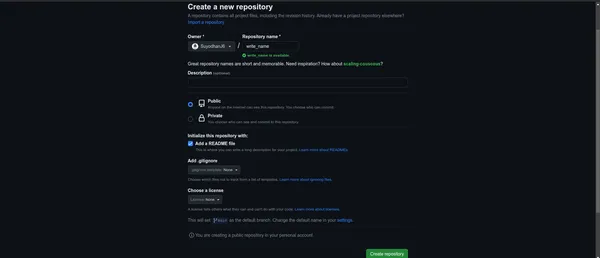
2. To create a folder for the project, follow these steps: Open your terminal or command prompt. Navigate to the directory where you want to create the project folder using the cd command. For example,
cd ~/Desktop will take you to the Desktop directory on a Mac or Linux machine.
- Once you are in the desired directory, use the mkdir command followed by the name of the folder you want to create.
- For example, mkdir my_project will create a new folder named my_project.
mkdir my_project - Change into the newly created directory using the cd command. For example, cd my_project.
cd my_project.3. Clone the repository
- To clone the repository, open your terminal or command prompt and navigate to the folder where you want to clone the repository. Then, use the git clone command followed by the URL of the repository. For example:
git clone https://github.com/your-username/your-repository.git
- This will create a local copy of the repository in your current working directory.
4. Open Vscode :
- For Example,
code .5. Create a virtual environment for our pipeline using the following command:
conda create -p venv python=3.9 -Y
6. Activate the virtual environment:
# Actiavte the environment
conda actiavte ./venv7. Install the required packages by running:
pip install -r requirements.txt
Structure of Code
To get started with building an end-to-end data pipeline on AWS, the first step is to create an AWS account. If you don’t already have an account, you can easily create one by following these simple steps:
- Go to the AWS website and click on the “Create an AWS Account” button.
- Enter your email address and choose a password.
- Fill in your personal information, such as name and address.
- Enter your payment information. Some AWS services offer a free tier for new accounts, so it will be free for some duration.
- Verify your identity by entering a valid phone number and credit card information.
- Read and accept the AWS customer agreement and other terms and conditions.
To create an S3 bucket in AWS, follow these steps
- Log in to your AWS console and go to the S3 service dashboard.
- Click on the “Create bucket” button.
- Enter a unique and meaningful name for your bucket. Use this name in your code later to access the bucket.
- Choose a region for your bucket. This should be the same region where you plan to run your code and data pipeline.
- Configure the bucket settings as per your requirements. You can choose to enable versioning, logging, and encryption, among other options.
- Click on the “Create bucket” button to create your S3 bucket.
Create your bucket, and then upload your data to it using the AWS console or by using code in your data pipeline. Make sure to keep the bucket name and region in a safe place, as you will need to reference them in your code.
import os
import sys
from zipfile import ZipFile
import shutil
from src.exception import CustomException
from src.exception1 import SensorException
class DataStore:
def __init__(self):
self.root = os.path.join(os.getcwd(), "data")
self.zip = os.path.join(self.root, "archive.zip")
self.images = os.path.join(self.root, "caltech-101")
self.list_unwanted = ["BACKGROUND_Google"]
def prepare_data(self):
try:
print(" Extracting Data ")
with ZipFile(self.zip, 'r') as files:
files.extractall(path=self.root)
files.close()
print(" Process Completed ")
except Exception as e:
message = CustomException(e, sys)
return {"Created": False, "Reason": message.error_message}
def remove_unwanted_classes(self):
try:
print(" Removing unwanted classes ")
for label in self.list_unwanted:
path = os.path.join(self.images,label)
shutil.rmtree(path, ignore_errors=True)
print(" Process Completed ")
except Exception as e:
message = CustomException(e, sys)
return {"Created": False, "Reason": message.error_message}
def sync_data(self):
try:
print("\n====================== Starting Data sync ==============================\n")
os.system(f"aws s3 sync {self.images} s3://image-database-01/images/")
print("\n====================== Data sync Completed ==========================\n")
except Exception as e:
raise SensorException(e, sys)
# message = CustomException(e, sys)
# return {"Created": False, "Reason": message.error_message}
def run_step(self):
try:
self.prepare_data()
self.remove_unwanted_classes()
self.sync_data()
return True
except Exception as e:
message = CustomException(e, sys)
return {"Created": False, "Reason": message.error_message}
if __name__ == "__main__":
store = DataStore()
store.run_step()
Here are the steps to create an Amazon Elastic Container Registry (ECR) in AWS
- Open the AWS Management Console and navigate to the Amazon ECR service.
- Click on the “Create repository” button.
- Enter a name for your repository, such as “my-ml-pipeline-app”.
- Select the “Tag immutability” setting that best suits your needs.
- Click on the “Create repository” button to create your ECR repository.
Once you have created your ECR repository, you can use it to store your Docker images and deploy your ML pipeline application.
Launch the EC2 instance
- Now that we have set up the necessary resources on AWS, we need to launch an EC2 instance where our code will run. To launch an EC2 instance, follow these steps:
- Go to the EC2 Dashboard on the AWS Management Console.
- Click on “Launch Instance”.
- Choose an Ubuntu 22.04 LTS. for your instance. For this project, we recommend using the Ubuntu 22.04 LTS.
- Choose an instance type. The instance type will depend on the requirements of your project.
- Configure the instance details such as the VPC, subnet, security group, and other settings. Ensure that you select the same VPC and subnet where you created your S3 bucket and launched your MongoDB instance.
- Add storage to your instance.
- Add tags to your instance for better organization.
- Configure the security group to allow incoming traffic from your IP address and allow outgoing traffic to the S3 bucket and MongoDB instance.
- Review your instance details and launch it.
- Once the instance is launched, connect to it using SSH.
With these steps, you should be able to launch an EC2 instance on AWS. Make sure to configure the instance properly to ensure that your pipeline runs smoothly.
Github and create secrets and variables, follow these steps
- Go to the Github website and log in to your account.
- Navigate to your repository where you want to create secrets and variables.
- Click on the “Settings” tab in the repository.
- From the left-hand sidebar, click on “Secrets”.
- Click on the “New repository secret” button.
- Add the secret name and value.
- Click on the “Add secret” button.
- Similarly, for creating variables, click on the “Actions” tab in the repository.
- Click on the “New workflow” button.
- Add a name to the workflow and click on the “Set up a workflow yourself” button.
- In the code, add the required environment variables.
- Commit the changes to the repository.
After following these steps, you will have successfully created secrets and variables in your GitHub repository.
name: workflow
on:
push:
branches:
- main
paths-ignore:
- 'README.md'
permissions:
id-token: write
contents: read
jobs:
integration:
name: Continuous Integration
runs-on: ubuntu-latest
steps:
- name: Checkout Code
uses: actions/checkout@v3
- name: Lint code
run: echo "Linting completed"
- name: Reformat Code
run: echo "Reformat code completed"
## Below code is available on GitHub GitHub Configurations
- Go to “Settings” -> “Actions” -> “Runners”
- Click on “Add a runner” and follow the instructions to set up the runner on your EC2 instance
- Make sure to select the correct architecture (X86_64 for most instances)
- Add pages for GitHub (if necessary)
- Go to “Settings” -> “Pages” and follow the instructions to set up a new GitHub Pages site
- Configure repository secrets
- Go to the “Secrets” tab and add any necessary secrets (e.g., AWS access keys, S3 bucket name) as repository secrets
- Access these secrets in your GitHub Actions workflow YAML file using the ${{ secrets.SECRET_NAME }} syntax
Infrastructure Details
- S3 Bucket: S3 stands for Simple Storage Service, and it’s a fully managed cloud storage service provided by AWS. You can use it to store and retrieve any amount of data, at any time, from anywhere on the web. To create an S3 bucket, follow the instructions provided in the AWS documentation:
- Mongo Database: MongoDB is a NoSQL database program that uses JSON-like documents with optional schemas. It’s a popular choice for many applications due to its flexible data model and scalability. To create a MongoDB instance, you can use a managed service such as MongoDB Atlas, or you can set up your own MongoDB instance on a virtual machine. Here’s a link to get started with MongoDB Atlas:
- Elastic Container Registry (ECR): ECR is a fully-managed Docker container registry that makes it easy for developers to store, manage, and deploy Docker container images. You can use it to store and manage Docker images for your applications, and then deploy them to your production environment when you’re ready. To create an ECR repository, follow the instructions provided in the AWS documentation:
Env variable
export ATLAS_CLUSTER_USERNAME=<username>
export ATLAS_CLUSTER_PASSWORD=<password>
export AWS_ACCESS_KEY_ID=<AWS_ACCESS_KEY_ID>
export AWS_SECRET_ACCESS_KEY=<AWS_SECRET_ACCESS_KEY>
export AWS_REGION=<region>
export AWS_BUCKET_NAME=<AWS_BUCKET_NAME>
export AWS_ECR_LOGIN_URI=<AWS_ECR_LOGIN_URI>
export ECR_REPOSITORY_NAME=<name>
export DATABASE_NAME=<name>
Cost Involved
- For s3 bucket : Since we are using S3 Standard
- For Ec2 Instance : Since we are using t2.small with 20Gb storage 1vCpu and 2Gb ram
- For Mysql : Since we are using
- For ECR : Storage is $0.10 per GB / month for data stored in private or public repositories.
- Data Transfer IN – All data transfer in
- Data Transfer OUT – Next 9.999 TB / month
Conclusion
In conclusion, building an end-to-end data pipeline on AWS unlocks the full potential of your data by enabling efficient collection, preprocessing, and deployment of machine learning models. By breaking down the pipeline into stages, you can achieve improved scalability, modularity, and easier troubleshooting. Throughout this blog post, we have explored the first stage of the pipeline, which is data collection and preprocessing, and discussed the necessary infrastructure components such as the S3 bucket, MongoDB, and Elastic Container Registry.
Key Takeaways:
- Breaking down a data pipeline into stages offers benefits such as scalability, modularity, and easier troubleshooting.
- AWS services like S3, EC2, and ECR provide a robust infrastructure for building and deploying data pipelines.
- GitHub Actions automates the deployment process, facilitating continuous integration and deployment.
- Securely managing sensitive information using GitHub secrets and environment variables ensures protection.
- Consider cost optimization strategies to minimize expenses, such as utilizing AWS Free Tier resources and setting up lifecycle policies.
Thank you for joining us on this journey of building an end-to-end data pipeline on AWS. I hope this blog post has provided valuable insights and practical guidance for your data science endeavours. Happy data pipelining!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
A. In AWS, a data pipeline is a managed service that allows you to orchestrate and automate the movement and transformation of data from various sources to different destinations. It enables you to efficiently process, transform, and analyze data in a scalable and reliable manner.
A. You can use the AWS Data Pipeline service to create a data pipeline in AWS. Start by defining your data sources, activities, and destinations in a pipeline definition. Then, use the AWS Management Console, AWS CLI, or SDKs to create and configure the pipeline based on your requirements.
A. The main purpose of a data pipeline is to streamline and automate the process of ingesting, processing, transforming, and delivering data from its source to its destination. It helps organizations efficiently manage and analyze data by ensuring timely availability in the right format, enabling data-driven decision-making and business insights.
A. AWS data pipeline offers several benefits, including:
Scalability: It can handle large volumes of data and automatically scale to accommodate varying workloads.
Flexibility: You can design and customize your data pipelines to fit your specific data processing and transformation needs.
Automation: It enables you to automate the movement and processing of data, reducing manual effort and improving efficiency.
Reliability: AWS data pipeline provides built-in fault tolerance and error handling capabilities to ensure the reliable execution of data workflows.