The big data industry is growing daily and needs tools to process vast volumes of data. That’s why you need to know about Apache Kafka, a publish-subscribe messaging system you can use to build distributed applications. It is scalable and fault-tolerant, making it suitable for supporting real-time and high-volume data streams. Because of this, Apache Kafka is used by big internet companies like LinkedIn, Twitter, Airbnb, and many others.
Source: www.indellient.com
Now you probably have questions. What value does Apache Kafka add? And how does it work? In this post, we will explore the use cases, terminology, architecture, and workings of Apache Kafka.
What is Apache Kafka?
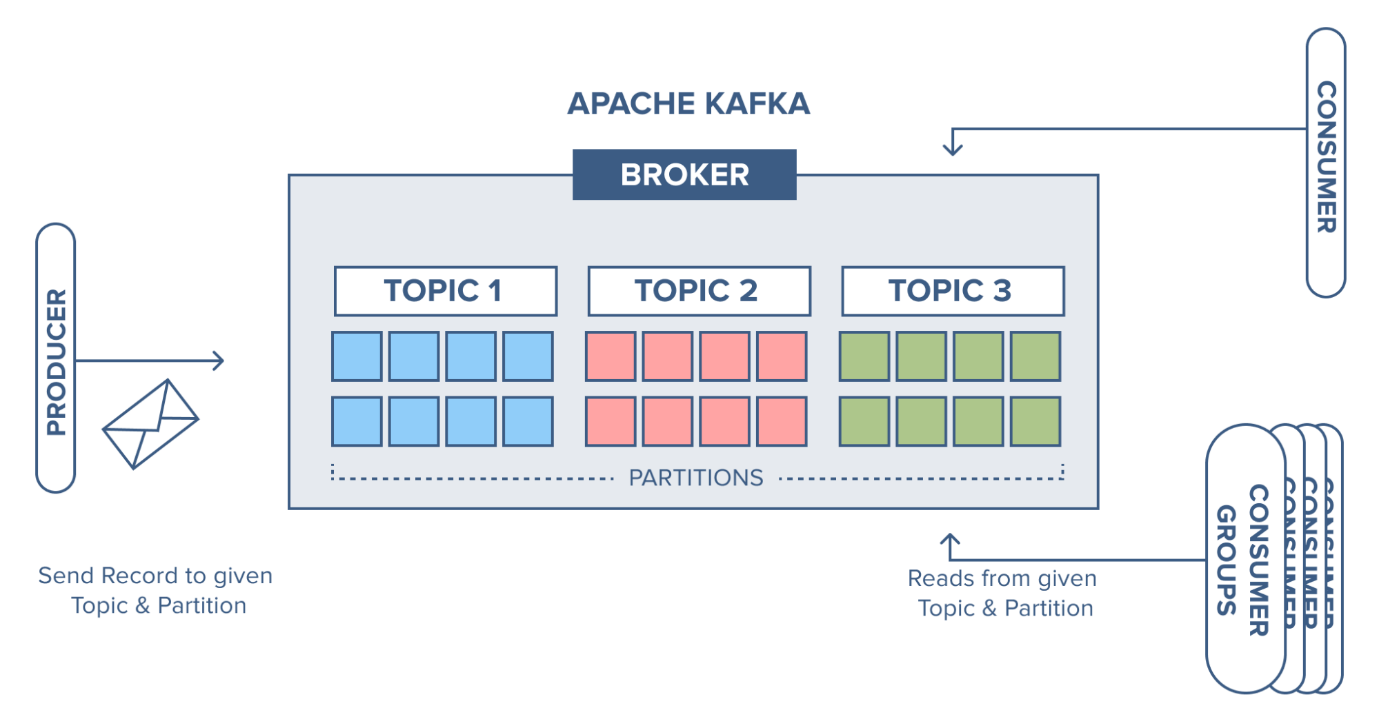
Kafka is a distributed publish-subscribe messaging system. It has a full queue that can accept large amounts of message data. With Kafka, applications can write and read data on topics. A topic presents a category for labeling data. Furthermore, the application can receive messages from one or more categories.
Kafka stores all received data on disk storage. Kafka then replicates the data within the Kafka cluster to prevent data loss.
Kafka can be speedy for several reasons. It uses the offset when the message was received. It also does not track consumers for a topic or who consumed a particular message. Consumers interested in this data should follow this information.
You can only enter an offset when loading data. Then, starting at that offset, Kafka will return the data to you in order. Many more speed optimizations are available with Kafka, but we won’t cover them in this post.
All these optimizations allow Kafka to process large amounts of data. However, to better understand the capabilities of Apache Kafka, we first need to understand the terminology.
source: https://kafka.apache.org/
Apache Kafka Terminology
Let’s discuss some terms that are key when working with Kafka.
Topics
Remember when we talked about event streams? Of course, there can be many events at once – and we need a way to organize them. For Kafka, the basic unit of event organization is called a topic.
A topic in Kafka is a user-defined category or resource name where data is stored and published. In other words, a case is simply a log of events. For example, when using web activity tracking, there might be a topic called “click” that receives and stores a “click” event every time a user clicks a specific button.
Partition
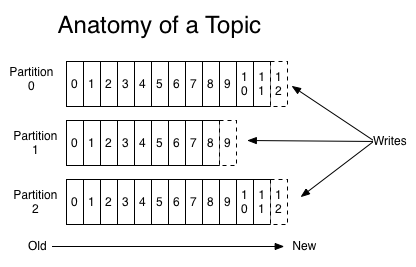
Topics in Kafka are partitioned, which is when we split a case into multiple log files that can live on separate Kafka brokers. This scalability is essential because it allows client applications to publish/subscribe to many brokers simultaneously and ensures high data availability as partitions are replicated across multiple brokers. So, for example, if one Kafka broker in your cluster goes down, Kafka can safely switch to replica partitions on the other brokers.
Finally, we must discuss how events are pleased and organized in sections. Let’s go back to our website traffic use case to understand this. Let’s say we split the “click” topic into three areas.
Every time our web client publishes a “click” event to our theme, that event will be attached to one of our three sections. If the key is part of the data part of the event, it is used to determine partition assignment. Events are added and partitioned sequentially, and each event’s ID (e.g., 0 for the first event, 1 for the second, etc.) is called an offset.
Replication of Kafka’s theme, leaders and followers
In the first section, we mentioned that partitions could live on separate Kafka brokers, a fundamental way Kafka protects against data loss. This is achieved by setting the topic replication factor, which determines the number of copies of data across multiple brokers.
For example, a replication factor of three will keep three copies of the topic for each partition in other brokers.
To avoid the inevitable confusion when both accurate data and copies of it are present in a cluster (e.g., how will a producer know which broker to publish data to for a particular partition?), Kafka follows a leader-follower system. In this way, one broker can be set as the leader of the thematic section and the rest of the brokers as followers of this section, while only the leader can process these client requests.
Message system
The messaging system transfers data between applications. This allows the application to focus on the data rather than how the data is shared.
There are two types of messaging systems. A classic example is a point-to-point system where producers keep data in a queue. After that, only one application can read data from the line. After reading, the message system removes the message from the queue.
Apache Kafka relies on a publish-subscribe messaging system. Consumers can subscribe to multiple topics in a message queue. They then receive specific messages that are relevant to their application. The Tutorials point website has a helpful image that illustrates this.
Broker
As the name suggests, a broker acts as an intermediary between a buyer and a seller. The Kafka broker receives messages from producers and stores them on its disk. It also makes loading messages easier.
Apache Kafka Architecture
Now let’s look at the internal architecture of Apache Kafka.
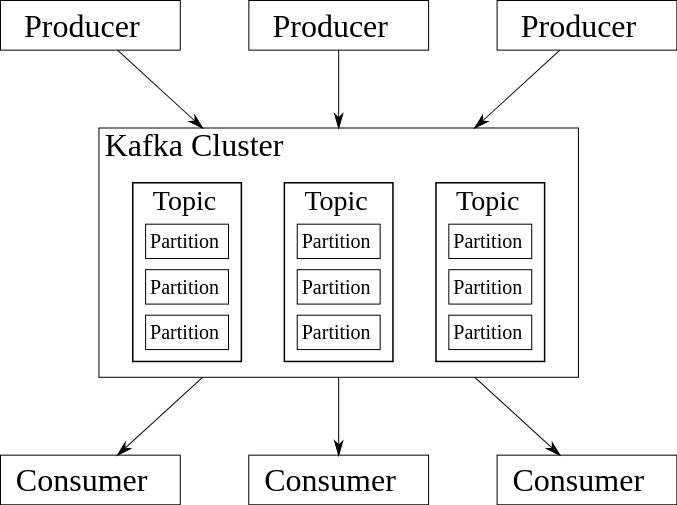
The Kafka ecosystem consists of a group of producers and consumers. For our purposes, producers and consumers are external actors. The internal ecosystem includes Kafka’s Zookeeper service and Kafka cluster. Zookeeper is a distributed configuration and synchronization service for managing and coordinating Kafka brokers. Zookeeper notifies producers and consumers when a broker is added to or fails in the Kafka system.
Brokers inside a Kafka cluster are responsible for load balancing. Zookeeper initializes multiple Kafka brokers inside the Kafka cluster to accommodate the higher load.
Again, the Tutorial point has a good image that can help you visualize the architecture.
Source: https://aws.amazon.com/msk/
Apache Kafka Use Cases
Next, let’s look at some use cases for Apache Kafka.
Tracking Website’s Activity
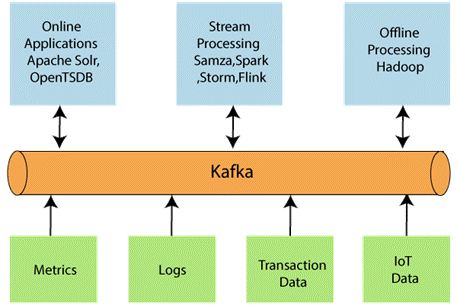
The original use case for Kafka was to be able to refactor a user activity tracking channel as a set of tracks to publish and subscribe to in real-time. This means that website activity (page views, searches, or other actions users can take) is issued to central topics, with one for each type of activity. These resources are available for subscription for various use cases, including real-time processing, monitoring, and loading intoHadoop systems or offline data warehouses for offline processing and reporting.
Activity tracking is often very bulky because many activity reports are generated for each user page view.
Kafka is often used for operational monitoring data. This includes aggregating statistics from distributed applications to create centralized active data sources.
Log aggregation
Many people use Kafka as a replacement for log aggregation solutions. Log aggregation typically collects physical log files from servers and stores them in a central location (perhaps a file server or HDFS) for processing. Kafka abstracts the details of files and provides a cleaner abstraction of log or event data as a message stream. This enables lower latency processing and more accessible support for multiple data sources and distributed data consumption. Compared to log-centric systems like Scribe or Flume, Kafka offers equally good performance, stronger resiliency guarantees through replication, and much lower end-to-end latency.
Stream processing
Many Kafka users process data in multi-stage processing pipelines where raw input data from Kafka topics are consumed and then aggregated, enriched, or otherwise transformed into new topics for further consumption or post-processing. For example, a process feed for recommending news articles can crawl article content from RSS feeds and publish it under the “articles” topic. Further processing may normalize or deduplicate this content and publish the cleansed article content to a new topic; the final stage of processing may attempt to recommend this content to users. These process pipelines create real-time graphs of data flows based on individual issues. Starting with version 0.10.0.0, a lightweight yet powerful streaming library called Kafka Streams is available in Apache Kafka that performs the kind of data processing described above. In addition to Kafka Streams, alternative open source stream processing tools include Apache Storm and Apache Samza.
Advantages of Apache Kafka
There are some advantages of using Kafka:
Reliability: Kafka distributes, replicates, and partitions data. Additionally, Kafka is fault tolerant.
Scalability: Kafka’s design allows you to process massive amounts of data. And it can scale without any downtime.
Durability: Received messages are stored as quickly as possible. So we can say that Kafka is resilient.
Performance: Finally, Kafka maintains the same level of performance even under extreme data loads (many terabytes of message data). So you can see that Kafka can handle large volumes of data with zero downtime and no data loss.
Disadvantages of Apache Kafka
After discussing the pros, let’s look at the cons:
Limited flexibility: Kafka does not support extended queries. For example, it is impossible to filter specific asset data in reports. (Features like this are the responsibility of the consumer application that reads the messages.) With Kafka, you can retrieve messages from a specific offset. Notes will be sorted as Kafka receives them from the message producer.
Not designed to keep historical data: Kafka is great for streaming data, but the design doesn’t allow you to store recorded data in Kafka for more than a few hours. Additionally, data is duplicated, so storage can quickly become expensive for large volumes of data. You should use Kafka as a temporary store where information is consumed as soon as possible.
No support for wildcard topics: Last on the list of disadvantages is that it is impossible to consume from multiple issues with a single consumer. For example, if you want to use both log-2019-01 and log-2019-02, you cannot use a topic selection wildcard like log-2019-*.
The above drawbacks are design limitations designed to improve Kafka’s performance. For some use cases that expect more flexibility, the above limitations may limit the application from consuming Kafka.
Conclusion
Apache Kafka is an excellent tool for ordering messages. It can handle vast amounts of message data by scaling the number of available brokers. Zookeeper also ensures that everything is coordinated and stays in sync. Still, if your application processes large amounts of message data, you should consider Apache Kafka for your technology stack.
Kafka can be speedy for several reasons. It uses the offset when the message is received. It also does not track consumers for a topic or who consumed a particular message. Consumers interested in this data should follow this information.
The Kafka ecosystem consists of a group of producers and consumers. For our purposes, producers and consumers are external actors.
Apache Kafka relies on a publish-subscribe messaging system. Consumers can subscribe to multiple topics in a message queue. They then receive specific messages that are relevant to their application.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.




{kind=link}