



{kind=link}
Introduction
A good way to get in-depth knowledge about Transformer models is to learn about attention mechanisms. In this light, learning about multi-head attention in particular before learning other types of attention mechanisms is also a great choice. This is because the concept tends to be a bit easier to grasp.
Attention mechanisms can be seen as neural network layers that can be added to regular deep-learning models. This drive is to have models that focus on specific parts of the input using assigned weights to relevant parts thereby weighing their value. We will further look in detail at the attention mechanism using a multi-head attention mechanism.

Learning Objectives
- The concepts of the Attention Mechanism
- What Multi-Head Attention is about
- The Architecture of Multi-Head Attention in Transformers
- A quick look at Other types of Attention Mechanism
This article was published as a part of the Data Science Blogathon.
Understanding Attention Mechanism
We can start by looking at this concept from human psychology. In psychology, attention is the concentration of awareness on some events so that there is an exclusion of the effect of other stimuli. This means that even when there are other distractions, we still focus on what we selected. Attention selectively concentrates on a discrete portion of the whole.
This concept is what is used in Transformers. They are able to focus on a target portion of their input and ignore the remaining portion. This can make them act in a very effective way.
What is Multi-Head Attention?
The Multi-Head Attention is a central mechanism in Transformer just skip-joining in ResNet50 architecture. Sometimes there are multiple other points in the sequence to be attended to. Using the approach of finding an overall average will not distribute the weights around so that diverse value is given as weights as we would want. This brings about the idea of having an extension of creating individual attention mechanisms to multiple heads resulting in multiple attention mechanisms. The implementation now presents multiple different query-key-value triplets on a single feature.

The computations are performed in such a way that the attention module iterates over a number of times, organizing into parallel layers known as attention heads. Each separate head independently processes both the input sequence and the associated output sequence element. The cumulative scores from each head are then combined to obtain a final attention score, which incorporates every detail of the input sequence.
Mathematical Expression
Specifically, if we have a key and a value matrix, we can transform the values into ℎ sub-queries, sub-keys, and sub-values, which will pass through the attention independently. The concatenation gives a head and combines them with a final weight matrix.

The learnable parameters are the values in Attention assign to the head where the various parameters are referred to as the Multi-Head Attention layer. The diagram below illustrates this process.
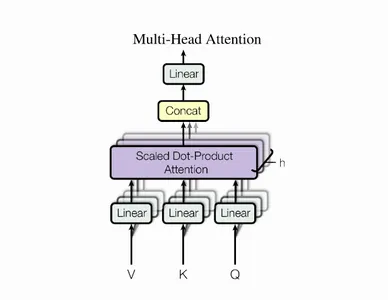
Lets us look at these variables briefly. Where the value of X is a concatenation of the matrix of word embeddings.
Matrices Explanation
Query: it is a feature vector providing insight into what the target is in the sequence. It places a request on the sequence of what needs attention.
Keys: This is a feature vector describing what contains in the element. It stands out to provide the identity of the elements and give attention by the query.
Values: Process the sequence of input, each input element uses a value to know what to provide an average on.
Score function: To create a score function, we assign the query and key to it to output a weight known as the query-key pair.
We can further understand the concept using the diagram below where Q: This stands for Query, K: This stands for Key, and V: Stands for Value

The attention weight of a Query token determines by the multi-head attention. Each Key’s token and its corresponding Value are multiplied together. It multiplies the Value associated with each Key after determining the relationship or attention weight between the Query and the Key.
Finally, multi-head attention enables us to handle various input sequence segments in various ways. Since each head will pay attention to a distinct input element individually, the model does a better job of capturing positional details. As a result, our representation is stronger.
Python Implementation of Multihead Attention
Now let’s see a practical implementation of a multi-head attention mechanism. We will implement this one using Python. We take the consecutive weight matrices transformed into the features with respect to the Queries, Keys, and Values.
class MultiheadAttention(nn.Module):
def __init__(self, input_dim, embed_dim, num_heads):
super().__init__()
assert embed_dim % num_heads == 0, "Embedding dimension must be 0 modulo number of heads."
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
# Stack all weight matrices 1...h together for efficiency
# Note that in many implementations you see "bias=False" which is optional
self.qkv_proj = nn.Linear(input_dim, 3*embed_dim)
self.o_proj = nn.Linear(embed_dim, embed_dim)
self._reset_parameters()
def _reset_parameters(self):
# Original Transformer initialization, see PyTorch documentation
nn.init.xavier_uniform_(self.qkv_proj.weight)
self.qkv_proj.bias.data.fill_(0)
nn.init.xavier_uniform_(self.o_proj.weight)
self.o_proj.bias.data.fill_(0)
def forward(self, x, mask=None, return_attention=False):
batch_size, seq_length, _ = x.size()
if mask is not None:
mask = expand_mask(mask)
qkv = self.qkv_proj(x)
# Separate Q, K, V from linear output
qkv = qkv.reshape(batch_size, seq_length, self.num_heads, 3*self.head_dim)
qkv = qkv.permute(0, 2, 1, 3) # [Batch, Head, SeqLen, Dims]
q, k, v = qkv.chunk(3, dim=-1)
# Determine value outputs
values, attention = scaled_dot_product(q, k, v, mask=mask)
values = values.permute(0, 2, 1, 3) # [Batch, SeqLen, Head, Dims]
values = values.reshape(batch_size, seq_length, self.embed_dim)
o = self.o_proj(values)
if return_attention:
return o, attention
else:
return oFind more detail here.
The Architecture of Multi-Head Attention in Transformers
The Transformer architecture, originally designed for machine translation, has an encoder-decoder structure. The encoder generates attention-based representations, while the decoder attends to encoded information and generates the translated sentence in an autoregressive manner. This structure is useful for Sequence-to-Sequence tasks with autoregressive decoding. This tutorial focuses on the encoder part, which is a small step to implement.
The encoder uses identical blocks applied sequentially, passing input through the Multi-Head Attention block, residual connection, and Layer Normalization. It calculates input and input to the attention layer, ensuring a crucial residual connection in Transformer architecture.
The Transformers can have over 24 encoder blocks, requiring residual connections for smooth gradient flow. Without residual connections, information about the original sequence is lost, while the Multi-Head Attention layer learns basis input features. Removing residual connections would result in lost information after initialization, and all output vectors represent similar information.
What are the Other types of Attention Mechanism?
Before rounding off, it is noteworthy that there are other types of attention mechanisms apart from multi-head and there is a variety of them. They only differ based on some adjustments done to them. The following are the types:
- Global Attention/Loung Mechanism: The Luong model can either attend to all source words or anticipate the target sentence, so attending to a smaller collection of words. Although the global and local attention models are equally effective, they use various context vectors depending on the particular implementation.
- Generalized Attention: A generalized attention model verifies input sequences and compares them to output sequences, capturing and comparing them. The mechanism then selects words or parts of the image to focus on.
- Additive Attention/Bahdanau: The Bahdanau attention mechanism uses alignment scores in a neural network, calculating at different points, ensuring a correlation between input and output sequence words, and considering hidden states. The final score is the sum of these scores.
- Self-Attention/Intra-attention: Self-attention mechanism, also known as intra-attention, picks up parts in the input sequence and computes initial output composition over time without considering the output sequence, as there is no manual data entry procedure.
Conclusion
Attention mechanism produces state-of-the-art results in its application such as in natural language processing tasks. It has contributed to breakthrough algorithms like GPT-2 and BERT. Transformers are a network that has hugely benefited from attention. Attention has been one of the finest efforts in building toward real natural-language understanding in systems transforming business environments and advancing AI solutions.
Key Takeaways
- To gain a deeper understanding of Transformer models, it’s essential to learn about attention mechanisms, particularly multi-head attention.
- The approach used allows for multiple attention mechanisms, presenting multiple query-key-value triplets on a single input feature.
- Transformers require residual connections for smooth gradient flow, preventing loss of original sequence information and learning based on input features.
Frequently Asked Questions (FAQs)
Multi-head attention is a type of attention mechanism that uses many mechanisms to control the way it consumes information of an input sequence, so that, it can have a more robust way of processing and learning from data.
In the Transformer, the Attention head is the module that helps to consume the information directly in parallel using Query, Key, and Value parameters. The heads provide a way of having independent or multiple ways of passing each section of an input that is valuable through various heads.
Attention mechanisms allow a transformer to focus on one part of the input data while giving less attention to other parts. Use it for learning from images, texts, videos, and various kinds of data.
Attention mechanisms offer advantages over traditional models due to their ability to focus or pay attention to only required details. These benefits include a shorter training time, high performance on large datasets and complex sequences, and higher accuracy in training.
Reference Links:
- Tutorial 6: Transformers and Multi-Head Attention – UvA DL Notebooks v1.2 documentationJAX+Flax version: In this tutorial, we will discuss one of the most impactful architectures of the last 2 years: the…uvadlc-notebooks.readthedocs.io
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. ArXiv. /abs/1706.03762
- https://d2l.ai/chapter_attention-mechanisms-and-transformers/multihead-attention.html
- https://w7.pngwing.com/pngs/400/754/png-transparent-comic-book-comics-pop-art-attention-miscellaneous-text-photography-thumbnail.png
- https://w7.pngwing.com/pngs/682/32/png-transparent-attention-psychology-homo-sapiens-graphy-information-attention-hand-photography-words-phrases-thumbnail.png
- https://upload.wikimedia.org/wikipedia/commons/8/8f/The-Transformer-model-architecture.png
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.