



{kind=link}
Data Science career journey presents a myriad of learning paths—from bootcamps to degrees. Amid this diversity, GitHub repositories emerge as an innovative and collaborative haven for aspiring data scientists. GitHub, a code-hosting platform, facilitates version control and collaboration, attracting individuals, companies, students, and educators. Renowned for its user-friendliness, support for public/private repositories, and a vibrant community, GitHub stands out as a learning portal and source of inspiration. In this article, we will be looking at the top 10 projects on Github for data science and machine learning enthusiasts.
Table of contents
- List of Top 10 Data Science Projects on Github For Beginners
- Exploring the Enron Email Dataset
- Predicting Housing Prices with Machine Learning
- Identifying Fraudulent Credit Card Transactions
- Image Classification with Convolutional Neural Networks
- Sentiment Analysis on Twitter Data
- Analyzing Netflix Movies and TV Shows
- Customer Segmentation with K-Means Clustering
- Medical Diagnosis with Deep Learning
- Music Genre Classification with Machine Learning
- Predicting Credit Risk with Logistic Regression
- How to Showcase your Data Science / Machine Learning Projects on GitHub?
- Conclusion
- Frequently Asked Questions
List of Top 10 Data Science Projects on Github For Beginners
Here is a list of Github machine learning and data science projects available for beginners with step by step procedure.
Exploring the Enron Email Dataset
The first on our list of data science capstone project on GitHub is about exploring the Enron Email Dataset. This will give you an initial idea of standard data science tasks. Link to the dataset: Enron Email Dataset.
Problem Statement
The project aims to explore the email dataset (of internal communications) from the Enron Corporation, globally known for a huge corporate fraud that led to the bankruptcy of the company. The exploration would be to find patterns and classify emails in an attempt to detect fraudulent emails.
Dataset
Let’s start by knowing the data. The dataset belongs to the Enron Corpus, a massive database of more than 6,00,000 emails belonging to the employees of Enron Corp. The dataset presents an opportunity for data scientists to dive deeper into one of the biggest corporate frauds, the Enron Fraud by studying patterns in the company data.
In this project, you will download the Enron dataset and create a copy of the original repository containing the existing project under your account. You can also create an entirely new project.
Step-by-Step Guide to the Project
The project involves you working on the following:
- Clone the original repository and familiarize yourself with the Enron dataset: This step would include reviewing the dataset or any documentation provided, understanding the data types, and keeping track of the elements.
- After the introductory analysis, you will move on to data preprocessing. Given that it is an extensive dataset, there will be a lot of noise (unnecessary elements), necessitating data cleaning. You may also need to work around the missing values in the dataset.
- After preprocessing, you should perform EDA (exploratory data analysis). This may involve creating visualizations to understand the distribution of data better.
- You can also undertake statistical analyses to identify correlations between data elements or anomalies.
Some relevant GitHub repositories that will help you to study the Enron Email Dataset are listed below:
Code Snippet:

Predicting Housing Prices with Machine Learning
Predicting housing prices is one of the most popular Github machine learning project:
Problem Statement
The goal of this project is to predict the prices of houses based on several factors and study the relationship between them. On completion, you will be able to interpret how each of these factors affects housing prices.
Dataset
Here, you will use a dataset with over 13 features, including ID (to count the records), zones, area (size of the lot in square feet), build type (type of dwelling), year of construction, year of remodeling (if valid), sale price (to be predicted), and a few more. Link to the dataset: Housing Price Prediction.
Step-by-Step Guide to the Project
You will work on the following processes while doing the machine learning project.
- Like any other GitHub project, you will start by exploring the dataset for data types, relationships, and anomalies.
- The next step will be to preprocess the data, reduce noise, and fill in the missing values (or remove the respective entries) based on your requirement.
- As predicting housing prices involves several features, feature engineering is essential. This could include techniques such as creating new variables through combinations of existing variables and selecting appropriate variables.
- The next step is to select the most appropriate ML model by exploring different ML models like linear regression, decision trees, neural networks, and others.
- Lastly, you will evaluate the chosen model based on metrics like root mean squared error, R-squared values, etc., to see how your model performs.
Some relevant GitHub repositories that will help you predict housing prices are listed below:
- House price prediction using regularized linear regression.
- Advanced regression techniques for house price prediction.
Code Snippet:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
housing_df = pd.read_csv('housing_data.csv')
housing_df = housing_df.drop(['MSZoning', 'LotConfig', 'BldgType', 'Exterior1st'], axis=1)
housing_df = housing_df.dropna(subset=['BsmtFinSF2', 'TotalBsmtSF', 'SalePrice'])
X = housing_df.drop('SalePrice', axis=1)
y = housing_df['SalePrice']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lr = LinearRegression()
lr.fit(X_train, y_train)Identifying Fraudulent Credit Card Transactions
Fraud detection in credit card transactions is an excellent area of practising GitHub data science projects. It will make you proficient in identifying data patterns and anomalies.
Problem Statement
This GitHub data science project is to detect patterns in data containing information about credit card transactions. The outcome should give you certain features/patterns that all fraudulent transactions share.
Dataset
In this GitHub project, you can work with any credit card transaction dataset, like the European cardholders’ data containing transactions made in September 2013. This dataset contains over 492 fraud transactions out of 284,807 total transactions. The features are denoted by V1, V2,…, etc. Link to the dataset: Credit Card Fraud Detection.
Step-by-step Guide to the Project
- You will start with data exploration to understand the structure and check for missing values in the dataset working with the Pandas library.
- Once you familiarize yourself with the dataset, preprocess the data, handle the missing values, remove unnecessary variables, and create new features via feature engineering.
- The next step is to train a machine-learning model. Consider different algorithms like SVM, random forests, regression, etc., and fine-tune them to achieve the best results.
- Evaluate its performance on various metrics like recall, precision, F1-score, etc.
Some relevant GitHub repositories that will help you detect fraudulent credit card transactions are listed below.
Code Snippet:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
creditcard_df = pd.read_csv('creditcard_data.csv')
X = creditcard_df.drop('Class', axis = 1)
y = creditcard_df['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state = 42)
rf = RandomForestClassifier(n_estimators=100, random_state = 42)
rf.fit(X_train, y_train)
Image Classification with Convolutional Neural Networks
Another one on our list of GitHub data science projects focuses on image classification using CNNs (convolutional neural networks). CNNs are a subtype of neural networks with built-in convolutional layers to reduce the high-dimensionality of images without compromising on the information/quality.
Problem Statement
The aim of this project is to classify images based on certain features using convolutional neural networks. On completion, you will develop a deep understanding of how CNNs proficiently work with image datasets for classification.
Dataset
In this project, you can use a dataset of Bing images by crawling image data from URLs based on specific keywords. You will need to use Python and Bing’s multithreading features for the same using the pip install bing-images command on your prompt window and import “bing” to fetch image URLs.
Step-by-step Guide to Image Classification
- You will start by filter-searching for the kind of images you wish to classify. It could be anything, for example, a cat or a dog. Download the images in bulk via the multithreading feature.
- The next is data organizing and preprocessing. Preprocess the images by resizing them to a uniform size and converting them to grayscale if required.
- Split the dataset into a testing and training set. The training set trains the CNN model, while the validation set monitors the training process.
- Define the architecture of the CNN model. You can also add functionality, like batch normalization, to the model. This prevents over-fitting.
- Train the CNN model on the training set using a suitable optimizer like Adam or SGD and evaluate its performance.
Some relevant GitHub repositories that will help you classify images using CNN are listed below.
Code Snippet:
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
from keras.utils import np_utils
# Load the dataset
(X_train, y_train), (X_test, y_test) = ‘dataset’.load_data()
# One-hot encode target variables
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
# Define the model architecture
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=X_train.shape[1:]))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# Compile the model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Train the model
history = model.fit(X_train, y_train, batch_size=128, epochs=20, validation_data=(X_test, y_test))
# Evaluate the model on the test set
scores = model.evaluate(X_test, y_test, verbose=0)
print("Test Accuracy:", scores[1])Sentiment Analysis on Twitter Data
Twitter is a famous ground for all kinds of data, making its data a good source for practicing machine learning and data science tasks.
Problem Statement
It has become necessary to analyze the sentiment behind things posted online. Following the same line, this project aims to study and analyze the sentiments behind the most popular social network, Twitter, using NLP (natural language processing).
Dataset
In this GitHub data science project, you will gather Twitter data using the Streaming Twitter API, Python, MySQL, and Tweepy. Then you will perform sentiment analysis to identify specific emotions and opinions. By monitoring these sentiments, you could help individuals or organizations to make better decisions on customer engagement and experiences, even as a beginner.
You can use the Sentiment 140 dataset containing over 1.6 million tweets. The tweets Link to the dataset: Sentiment140 dataset.
Step-by-step Guide to the Project
- The first step is to use Twitter’s API to collect data based on specific keywords, users, or tweets. Once you have the data, remove unnecessary noise and other irrelevant elements like special characters.
- You can also remove certain stop words (words that do not add much value), “the,” “and,” etc. Additionally, you can perform lemmatization. Lemmatization refers to converting different forms of the word into a single form; for example, “eat,” “eating,” and “eats” becomes “eat” (the lemma).
- The next important step in NLP-based analysis is tokenization. Simply put, you will break down the data into smaller units of tokens or individual words. This makes it easier to assign meaning to smaller chunks that constitute the entire text.
- Once the data has been tokenized, the next step is to classify the sentiment of each token using a machine-learning model. You can use Random Forest Classifiers, Naive Bayes, or RNNs, for the same.
Some relevant GitHub repositories that will help you analyze sentiments from Twitter data are listed below.
- Real-time sentiment tracking on Twitter for brand improvement.
- Positive/Negative emotion analysis on Twitter data.
Code Snippet:
import nltk
nltk.download('stopwords')
nltk.download('punkt')
nltk.download('wordnet')
import string
import re
import pandas as pd
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
# Load the dataset
data = pd.read_csv('tweets.csv', encoding='latin-1', header=None)
# Assign new column names to the DataFrame
column_names = ['target', 'id', 'date', 'flag', 'user', 'text']
data.columns = column_names
# Preprocess the text data
stop_words = set(stopwords.words('english'))
lemmatizer = WordNetLemmatizer()
def preprocess_text(text):
# Remove URLs, usernames, and hashtags
text = re.sub(r'http\S+', '', text)
text = re.sub(r'@\w+', '', text)
text = re.sub(r'#\w+', '', text)
# Remove punctuation and convert to lowercase
text = text.translate(str.maketrans('', '', string.punctuation))
text = text.lower()
# Tokenize the text and remove stop words
tokens = word_tokenize(text)
filtered_tokens = [token for token in tokens if token not in stop_words]
# Lemmatize the tokens
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in filtered_tokens]
# Join the tokens back into text
preprocessed_text = ' '.join(lemmatized_tokens)
return preprocessed_text
data['text'] = data['text'].apply(preprocess_text)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(data['text'], data['target'], test_size=0.2, random_state=42)
# Vectorize the text data
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(X_train)
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
# Train the model
clf = MultinomialNB().fit(X_train_tfidf, y_train)
# Test the model
X_test_counts = count_vect.transform(X_test)
X_test_tfidf = tfidf_transformer.transform(X_test_counts)
y_pred = clf.predict(X_test_tfidf)
# Print the classification report
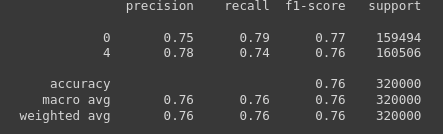
print(classification_report(y_test, y_pred))
Output:
Analyzing Netflix Movies and TV Shows
Netflix is probably everyone’s favorite movie streaming service. This GitHub data science project is based on analyzing Netflix movies and TV shows.
Problem Statement
The aim of this project is to run data analysis workflows, including EDA, visualization, and interpretation, on Netflix user data.
Dataset
This data science project aims to hone your skills and visually create and interpret Netflix data using libraries like Matplotlib, Seaborn, and worldcloud and tools like Tableau. For the same, you can use the Netflix Original Films and IMDb scores dataset available on Kaggle. It contains all Netflix Originals released as of June 1, 2021, with their corresponding IMDb ratings. Link to the dataset: Netflix Originals.
Step-by-step Guide to Analyzing Netflix Movies
- After downloading the dataset, preprocess the dataset by removing unnecessary noise and stopwords like “the,” “an,” and “and.”
- Then comes tokenization of the cleaned data. This step involves breaking bigger sentences or paragraphs into smaller units or individual words.
- You can also use stemming/lemmatization to convert different forms of words into a single item. For instance, “sleep” and “sleeping” becomes “sleep.”
- Once the data is preprocessed and lemmatized, you can extract features from text using count vectorizer, tfidf, etc and then use a machine learning algorithm to classify the sentiments. You can use Random Forests, SVMs, or RNNs for the same.
- Create visualizations and study the patterns and trends, such as the number of movies released in a year, the top genres, etc.
- The project can be extended to text analysis. Analyze the titles, directors, and actors of the movies and TV shows.
- You can use the resulting insights to create recommendations.
Some relevant GitHub repositories that will help you analyze Netflix Movies and TV Shows are listed below.
Code Snippet:
import pandas as pd
import nltk
nltk.download('vader_lexicon')
from nltk.sentiment import SentimentIntensityAnalyzer
# Load the Netflix dataset
netflix_data = pd.read_csv('netflix_titles.csv', encoding='iso-8859-1')
# Create a new column for sentiment scores of movie and TV show titles
sia = SentimentIntensityAnalyzer()
netflix_data['sentiment_scores'] = netflix_data['Title'].apply(lambda x: sia.polarity_scores(x))
# Extract the compound sentiment score from the sentiment scores dictionary
netflix_data['sentiment_score'] = netflix_data['sentiment_scores'].apply(lambda x: x['compound'])
# Group the data by language and calculate the average sentiment score for movies and TV shows in each language
language_sentiment = netflix_data.groupby('Language')['sentiment_score'].mean()
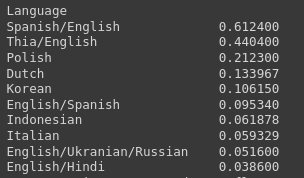
# Print the top 10 languages with the highest average sentiment score for movies and TV shows
print(language_sentiment.sort_values(ascending=False).head(10))
Output:
Customer Segmentation with K-Means Clustering
Customer segmentation is one of the most important applications of data science. This GitHub data science project will require you to work with the K-clustering algorithm. This popular unsupervised machine learning algorithm clusters data points into K clusters based on similarity.
Problem Statement
The goal of this project is to segment customers visiting a mall based on certain factors like their annual income, spending habits, etc., using the K-means clustering algorithm.
Dataset
The project will require you to collect data, undertake preliminary research and data preprocessing, and train and test a K-means clustering model to segment customers. You can use a dataset on Mall Customer Segmentation containing five features (CustomerID, Gender, Age, Annual Income, and Spending Score) and corresponding information about 200 customers. Link to the dataset: Mall Customer Segmentation.
Step-by-step Guide to the Project
Follow the steps below:
- Load the dataset, import all necessary packages, and explore the data.
- After familiarizing with the data, clean the dataset by removing duplicates or irrelevant data, handling missing values, and formatting the data for analysis.
- Select all relevant features. This could include annual income, spending score, gender, etc.
- Train a K-Means clustering model on the preprocessed data to identify customer segments based on these features. You can then visualize the customer segments using Seaborn and make scatter plots, heatmaps, etc.
- Lastly, analyze the customer segments to gain insights into customer behavior.
Some relevant GitHub repositories that will help you segment customers are listed below.
Code Snippet:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
# Load the customer data
customer_data = pd.read_csv('customer_data.csv')
customer_data = customer_data.drop('Gender', axis=1)
# Standardize the data
scaler = StandardScaler()
scaled_data = scaler.fit_transform(customer_data)
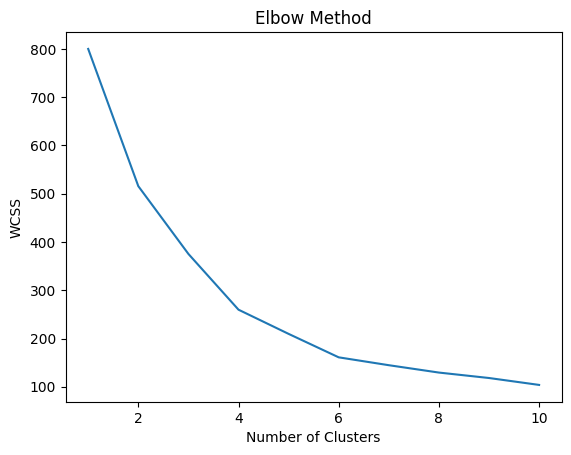
# Find the optimal number of clusters using the elbow method
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', random_state=42)
kmeans.fit(scaled_data)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Elbow Method')
plt.xlabel('Number of Clusters')
plt.ylabel('WCSS')
plt.show()
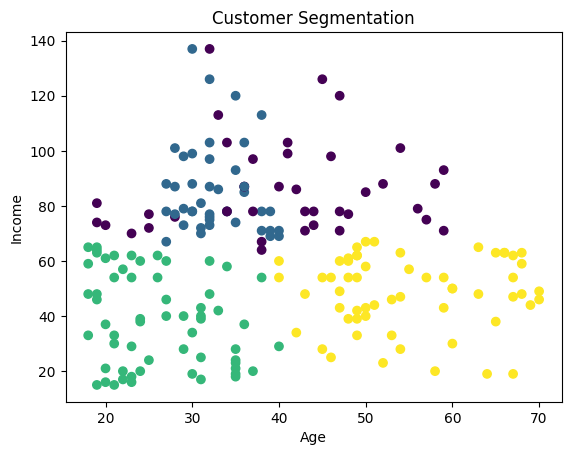
# Perform K-Means clustering with the optimal number of clusters
kmeans = KMeans(n_clusters=4, init='k-means++', random_state=42)
kmeans.fit(scaled_data)
# Add the cluster labels to the original DataFrame
customer_data['Cluster'] = kmeans.labels_
# Plot the clusters based on age and income
plt.scatter(customer_data['Age'], customer_data['Annual Income (k$)'], c=customer_data['Cluster'])
plt.title('Customer Segmentation')
plt.xlabel('Age')
plt.ylabel('Income')
plt.show()
Medical Diagnosis with Deep Learning
Deep learning is a relatively nascent branch of machine learning consisting of multiple layers of neural networks. It is widely used for complex applications because of its high computational capability. Consequently, working on a Github data science project, including deep learning, will be very good for your data analyst portfolio on Github.
Problem Statement
This GitHub data science project aims to identify different pathologies in chest X-rays using deep-learning convolutional models. Upon completion, you should get an idea of how deep learning/machine learning is used in radiology.
Dataset
In this data science capstone project, you will work with the GradCAM model interpretation method and use chest X-rays to diagnose over 14 kinds of pathologies, like Pneumothorax, Edema, Cardiomegaly, etc. The goal is to utilize deep learning-based DenseNet-121 models for classification.
You will work using a public dataset of chest X-rays with over 108,948 frontal view X-rays of more than 32,717 patients. A subset of ~1000 images would be enough for the project. Link to the dataset: Chest X-rays.
Step-by-step Guide to the Project
- Download the dataset. Once you have it, you must preprocess it by resizing the images, normalizing pixels, etc. This is done to ensure that your data is ready for training.
- The next step is to train the deep learning model, DenseNet121 using PyTorch or TensorFlow.
- Using the model, you could predict the pathology and other underlying issues (if any).
- You can evaluate your model on F1 score, precision, and accuracy metrics. If trained correctly, the model can result in accuracies as high as 0.9 (ideal is the closest to 1).
Some relevant GitHub repositories that will help you with medical diagnoses using deep learning are listed below.
Code Snippet:
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Set up data generators for training and validation sets
train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
train_generator = train_datagen.flow_from_directory('train_dir', target_size=(128, 128), batch_size=32, class_mode='binary')
val_datagen = ImageDataGenerator(rescale=1./255)
val_generator = val_datagen.flow_from_directory('val_dir', target_size=(128, 128), batch_size=32, class_mode='binary')
# Build a convolutional neural network for medical diagnosis
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(128, 128, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model on the training set and evaluate it on the validation set
history = model.fit(train_generator, epochs=10, validation_data=val_generator)
# Plot the training and validation accuracy and loss curves
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
Music Genre Classification with Machine Learning
This is among the most interesting GitHub data science projects. While it is a great project, it is equally challenging as getting a proper dataset would be a very time-consuming part of this project, given it’s all music!
Problem Statement
This unique GitHub project is aimed to help you learn how to work with non-standard data types like musical data. Further, you will also learn how to classify such data based on different features.
Dataset
In this project, you will collect music data and use it to train and test ML models. Since music data is highly subject to copyrights, we make it easier using MSD (Million Song Dataset). This freely available dataset contains audio features and metadata for almost a million songs. These songs belong to various categories like Classical, Disco, HipHop, Reggae, etc. However, you need a music provider platform to stream the “sounds.”
Link to the dataset: MSD.
Step-by-step Guide to the Project
- The first step is to collect the music data.
- The next step is to preprocess data. Music data is typically preprocessed by converting audio files into feature vectors that can be used as input.
- After processing the data, it is essential to explore features like frequency, pitch, etc. You can study the data using the Mel Frequency Cepstral Coefficient method, rhythm features, etc. You can classify the songs later using these features.
- Select an appropriate ML model. It could be multiclass SVM, or CNN, depending on the size of your dataset and desired accuracy.
Some relevant GitHub repositories that will help you segment customers are listed below.
Code Snippet:
import os
import librosa
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from keras import models, layers
# Set up paths to audio files and genre labels
AUDIO_PATH = 'audio'
CSV_PATH = 'data.csv'
# Load audio files and extract features using librosa
def extract_features(file_path):
audio_data, _ = librosa.load(file_path, sr=22050, mono=True, duration=30)
mfccs = librosa.feature.mfcc(y=audio_data, sr=22050, n_mfcc=20)
chroma_stft = librosa.feature.chroma_stft(y=audio_data, sr=22050)
spectral_centroid = librosa.feature.spectral_centroid(y=audio_data, sr=22050)
spectral_bandwidth = librosa.feature.spectral_bandwidth(y=audio_data, sr=22050)
spectral_rolloff = librosa.feature.spectral_rolloff(y=audio_data, sr=22050)
features = np.concatenate((np.mean(mfccs, axis=1), np.mean(chroma_stft, axis=1), np.mean(spectral_centroid), np.mean(spectral_bandwidth), np.mean(spectral_rolloff)))
return features
# Load data from CSV file and extract features
data = pd.read_csv(CSV_PATH)
features = []
labels = []
for index, row in data.iterrows():
file_path = os.path.join(AUDIO_PATH, row['filename'])
genre = row['label']
features.append(extract_features(file_path))
labels.append(genre)
# Encode genre labels and scale features
encoder = LabelEncoder()
labels = encoder.fit_transform(labels)
scaler = StandardScaler()
features = scaler.fit_transform(np.array(features, dtype=float))
# Split data into training and testing sets
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.2)
# Build a neural network for music genre classification
model = models.Sequential()
model.add(layers.Dense(256, activation='relu', input_shape=(train_features.shape[1],)))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.2))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dropout(0.1))
model.add(layers.Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the model on the training set and evaluate it on the testing set
history = model.fit(train_features, train_labels, epochs=50, batch_size=128, validation_data=(test_features, test_labels))
# Plot the training and testing accuracy and loss curves
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Testing Accuracy')
plt.title('Training and Testing Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Testing Loss')
plt.title('Training and Testing Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
Predicting Credit Risk with Logistic Regression
Predicting credit risk is one of the most vital applications of data science in the financial industry. Almost all lending institutions undertake credit risk prediction using machine learning. So if you want to advance your skills as a data scientist and leverage machine learning, doing a GitHub machine learning project is an excellent idea.
Problem Statement
This project is another application of machine learning in the financial sector. It aims to predict the credit risks of different customers based on their financial records, income, debt size, and a few other factors.
Dataset
In this project, you will be working on a dataset including lending details of customers. It includes many features like loan size, interest rate, borrower income, debt-to-income ratio, etc. All these features, when analyzed together, will help you determine the credit risk of each customer. Link to the dataset: Lending.
Step-by-step Guide to the Project
- After sourcing the data, the first step is to process it. The data needs to be cleaned to ensure it is suitable for analysis.
- Explore the dataset to gain insights into different features and find anomalies and patterns. This can involve visualizing the data with histograms, scatterplots, or heat maps.
- Choose the most relevant features to work with. For instance, target the credit score, income, or payment history while estimating the credit risk.
- Spilt the dataset into training and testing and used the training data to fit a logistic regression model using maximum likelihood estimation. This stage approximates the likelihood of customers who fail to repay.
- Once your model is ready, you can evaluate it using metrics like, precision, recall, etc.
Some relevant GitHub repositories that will help you predict credit risk are listed below.
Code Snippet:
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix
# Load data from CSV file
data = pd.read_csv('credit_data.csv')
# Clean data by removing missing values
data.dropna(inplace=True)
# Split data into features and labels
features = data[['loan_size', 'interest_rate', 'borrower_income', 'debt_to_income',
'num_of_accounts', 'derogatory_marks', 'total_debt']]
labels = data['loan_status']
# Scale features to have zero mean and unit variance
scaler = StandardScaler()
features = scaler.fit_transform(features)
# Split data into training and testing sets
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.2)
# Build a logistic regression model for credit risk prediction
model = LogisticRegression()
# Train the model on the training set
model.fit(train_features, train_labels)
# Predict labels for the testing set
predictions = model.predict(test_features)
# Evaluate the model's accuracy and confusion matrix
accuracy = accuracy_score(test_labels, predictions)
conf_matrix = confusion_matrix(test_labels, predictions)
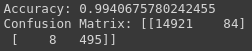
print('Accuracy:', accuracy)
print('Confusion Matrix:', conf_matrix)
Output:
How to Showcase your Data Science / Machine Learning Projects on GitHub?
If you are wondering how to put your GitHub data science project forward, this section is there for your reference. You can start by building a legitimate data analyst or data scientist portfolio on GitHub. Follow the below steps once you have a profile.
- Create a new repository with a descriptive name and a brief description.
- Add a README file with an overview of your GitHub data science project, dataset, methodology, and any other information you want to provide. This can include your contributions to the project, impact on society, cost, etc.
- Add a folder with the source code. Make sure that the code is clean and well-documented.
- Include a license if you want to publicize your repository and are open to receiving feedback/suggestions. GitHub provides numerous license options.
Conclusion
As someone interested in the field, you must have seen that the world of data science is constantly evolving. Whether exploring new data sets or building more complex models, data science constantly adds value to day-to-day business operations. This environment has necessitated people to explore it as a profession. For all aspiring data scientists and existing professionals, GitHub is the go-to platform for data scientists to showcase their work and learn from others. This is why this blog has explored the top 10 GitHub data science projects for beginners that offer diverse applications and challenges. By exploring these projects, you can dive deeper into data science workflows, including data preparation, exploration, visualization, and modelling.
To gain more insight into the field, Analytics Vidhya, a highly credible educational platform, offers numerous resources on data science, machine learning, and artificial intelligence. With these resources (blogs, tutorials, certifications, etc.), you can get practical experience working with complex datasets in a real-world context. Moreover, AV offers a comprehensive Blackbelt course that introduces you to the application of AI and ML in several fields, including data science. Head over to the website and see for yourself.
Frequently Asked Questions
A. Choose projects aligned with your interests and goals, such as analyzing real-world datasets, building predictive models, creating visualizations, conducting sentiment analysis, or developing recommendation systems. Opt for projects showcasing expertise in specific data science areas.
A. Identify a problem, set clear objectives, gather relevant data, preprocess it, and choose tools like statistical modeling or machine learning. Document your process, present findings effectively, and communicate insights for a successful project.
A. A systematic effort applying data analysis techniques to derive insights from data. Involves defining a problem, collecting and preprocessing data, conducting exploratory data analysis, applying statistical or machine learning methods, and interpreting results for decision-making.
A. Showcase skills with projects demonstrating data analysis, technique application, and effective communication. Examples include predicting customer churn, sentiment analysis, or building a recommendation system, emphasizing problem-solving proficiency in data science.