



This article was published as a part of the Data Science Blogathon
Sentiment Analysis
Sentiment Analysis is the process of finding the sentiments of the text data. Sentiment Analysis falls under the text classification in Natural Language Processing. Sentiment Analysis would help us to know our customer reviews better. A sentiment denotes any one of the following, Positive, Negative, and Neutral. When we analyze the negative reviews of our products we can easily use those reviews to surmount the problems we face and provide a better product.
{kind=link}
Benefits of using sentiment analysis include,
- Understand customer better
- Improvise the product features based on customer reviews
- We will be able to identify the mistakes in the features and resolve them to satisfy the customer.
Sentiment analysis can be done in two different ways,
- Rule-based sentiment analysis
- Automated sentiment analysis
In rule-based sentiment analysis, we define a set of rules, if the data satisfies those rules then we can classify them accordingly. For example, if the text data contains the words like good, beautiful, amazing, and etc., we can classify it as positive sentiment. The problem with rule-based sentiment analysis is that it can’t generalize well and may not classify accurately. For example, the rule-based system is more likely to classify the following sentence as positive according to the rules, “The product is not good”. The reason is that the rule-based systems identifies the word good in the sentence and classifies it as positive sentiment, but the context is different and the sentence is negative. In order to surmount these problems, we can use deep learning techniques to perform sentiment analysis.
In automated sentiment analysis, we leverage deep learning to learn the feature-target mapping in the data. In our case, the features are the reviews and the target is the sentiment. So in our post, we leverage automated sentiment analysis using deep learning models.
Sentiment Analysis using TensorFlow
In this post, we are going to leverage deep learning to find the sentiments of the IMDB reviews. We are going to use the IMDB reviews data in this post. You can download the data here. The data contains two columns namely review and sentiment. The sentiment column contains only two unique values namely positive and negative indicating the sentiment of the corresponding reviews. So we can infer that our problem is a binary classification problem. Our model is going to learn the feature-target mapping, in our case, it is the review-sentiment mapping.
In this post, we are going to use regex and spaCy for preprocessing and TensorFlow’s Bidirectional LSTM model for training.
To install spaCy refer to this webpage for instructions. To install TensorFlow refer to this webpage for instructions.
After installing spaCy, use the following command to download the trained pipeline package of spaCy called en_core_web_sm which we are going to use if for preprocessing.
python -m spacy download en_core_web_sm
Import Required Libraries
import re
import spacy
import numpy as np
import pandas as pd
import en_core_web_sm
import tensorflow as tf
from nltk.stem import WordNetLemmatizer
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import Sequential
from spacy.lang.en.stop_words import STOP_WORDS
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional, Dropout
nlp = en_core_web_sm.load()
lemmatizer = WordNetLemmatizer()
stopwords = STOP_WORDS
EMOJI_PATTERN = re.compile(
"["
u"U0001F600-U0001F64F" # emoticons
u"U0001F300-U0001F5FF" # symbols & pictographs
u"U0001F680-U0001F6FF" # transport & map symbols
u"U0001F1E0-U0001F1FF" # flags (iOS)
u"U00002702-U000027B0"
u"U000024C2-U0001F251"
"]+", flags=re.UNICODE
)
FILTERS = '!"#$%&()*+,-/:;?@[\]^_`{|}~tn'
HTML_TAG_PATTERN = re.compile(r']*>')
NUMBERING_PATTERN = re.compile('d+(?:st|[nr]d|th)')
DISABLE_PIPELINES = ["tok2vec", "parser", "ner", "textcat", "custom", "lemmatizer"]
We are loading the spaCy’s trained pipeline called en_core_web_sm using the command en_core_web_sm.load(). We are also loading the stopwords available in spaCy. Stopwords are words that don’t have much of a meaning associated with them, some of the examples include words like the, he, she, it, and etc.
The emoji pattern defined above is used to remove the emojis in the review data. The filters defined above are the possible special characters that might be available in the reviews. The HTML tag pattern defined above is used to remove the HTML tags and retain only the data inside the tags. The numbering pattern defined above is used to remove numberings like 1st, 2nd, 3rd, and so on. The disable pipelines defined above are used to disable certain pipelines in the spaCy language model such that resulting in completing the processing efficiently and with low latency.
def initial_preprocessing(text):
"""
- Remove HTML tags
- Remove Emojis
- For numberings like 1st, 2nd
- Remove extra characters > 2 eg:
ohhhh to ohh
"""
tag_removed_text = HTML_TAG_PATTERN.sub('', text)
emoji_removed_text = EMOJI_PATTERN.sub(r'', tag_removed_text)
numberings_removed_text = NUMBERING_PATTERN.sub('', emoji_removed_text)
extra_chars_removed_text = re.sub(
r"(.)1{2,}", r'11', numberings_removed_text
)
return extra_chars_removed_text
def preprocess_text(doc):
"""
Removes the
1. Spaces
2. Email
3. URLs
4. Stopwords
5. Punctuations
6. Numbers
"""
tokens = [
token
for token in doc
if not token.is_space and
not token.like_email and
not token.like_url and
not token.is_stop and
not token.is_punct and
not token.like_num
]
"""
Remove special characters in tokens except dot
(would be useful for acronym handling)
"""
translation_table = str.maketrans('', '', FILTERS)
translated_tokens = [
token.text.lower().translate(translation_table)
for token in tokens
]
"""
Remove integers if any after removing
special characters, remove single characters
and lemmatize
"""
lemmatized_tokens = [
lemmatizer.lemmatize(token)
for token in translated_tokens
if len(token) > 1
]
return lemmatized_tokens
labels = imdb_data['sentiment'].iloc[:10000]
labels = labels.map(lambda x: 1 if x=='positive' else 0)
"""
Preprocess the text data
"""
data = imdb_data.iloc[:10000, :]
column = 'review'
not_null_data = data[data[column].notnull()]
not_null_data[column] = not_null_data[column].apply(initial_preprocessing)
texts = [
preprocess_text(doc)
for doc in nlp.pipe(not_null_data[column], disable=DISABLE_PIPELINES)
]
How does the above code work?
First of all, we are taking the first 10000 rows of data. The label/ target in this data is the column named ‘sentiment’. The sentiment column consists of two unique values namely ‘positive’ and ‘negative’ indicating the sentiment of the corresponding reviews. We are replacing the value ‘positive’ with integer 1 and the value ‘negative’ with integer 0.
We are taking only the rows which are not null which means we are omitting the reviews with null values. After obtaining the not null reviews we are applying the initial preprocessing function defined above.
The steps followed by the method initial preprocessing are,
- Removing HTML tags like , and extracting the data defined inside the tag
- Removing the emojis in the data
- Removing the numbering patterns in the data like 1st, 2nd, 3rd, and etc.
- Removing extra characters in the word. For example, the word ohhh is replaced with ohh.
After applying the initial preprocessing steps we are using spacy to preprocess the data. The steps followed by the preprocess method are,
- Removing spaces in the data.
- Removing emails in the data.
- Removing stopwords in the data.
- Removing URLs in the data.
- Removing punctuations in the data.
- Removing numbers in the data.
- Lemmatization.
The function nlp.pipe will produce series of doc objects in spaCy. A doc in spaCy is a sequence of token objects. We used disable pipelines to speed up the preprocessing time.
Lemmatization is the process of finding the root of the word. For example, the lemma of the word running would be run, which is the root of the word running. The purpose of doing lemmatization is to decrease the size of the vocabulary. To lemmatize the words we have used WordNetLemmatizer from the nltk package.
tokenizer = Tokenizer(
filters=FILTERS,
lower=True
)
padding = 'post'
tokenizer.fit_on_texts(texts)
vocab_size = len(tokenizer.word_index) + 1
sequences = []
max_sequence_len = 0
for text in texts:
# convert texts to sequence
txt_to_seq = tokenizer.texts_to_sequences([text])[0]
sequences.append(txt_to_seq)
# find max_sequence_len for padding
txt_to_seq_len = len(txt_to_seq)
if txt_to_seq_len > max_sequence_len:
max_sequence_len = txt_to_seq_len
# post padding
padded_sequences = pad_sequences(
sequences,
maxlen=max_sequence_len,
padding=padding
)
After performing the preprocessing we are going to tokenize the data, convert the tokenized words to sequences, and pad the tokenized sentences. Tokenization is the process of breaking down a sentence into a sequence of words. For example, “I like apples” can be tokenized to [“I”, “like”, “apples”]. Converting the tokenized sentences into sequences would look like [1, 2, 3]. The words “i”, “like”, and “apples” are mapped to the numbers 1, 2, and 3. Then padding the sequences would look like [1, 2, 3, 0, 0, 0]. The three zeros after the number 3 are the padded sequences. This is also called post padding.
model = Sequential()
model.add(Embedding(vocab_size, 64, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(64, return_sequences=True, input_shape=(None, 1))))
model.add(Dropout(0.2))
model.add(Bidirectional(LSTM(32)))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(1, activation='sigmoid'))
adam = Adam(learning_rate=0.01)
model.compile(
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=adam,
metrics=['accuracy']
)
model.summary()
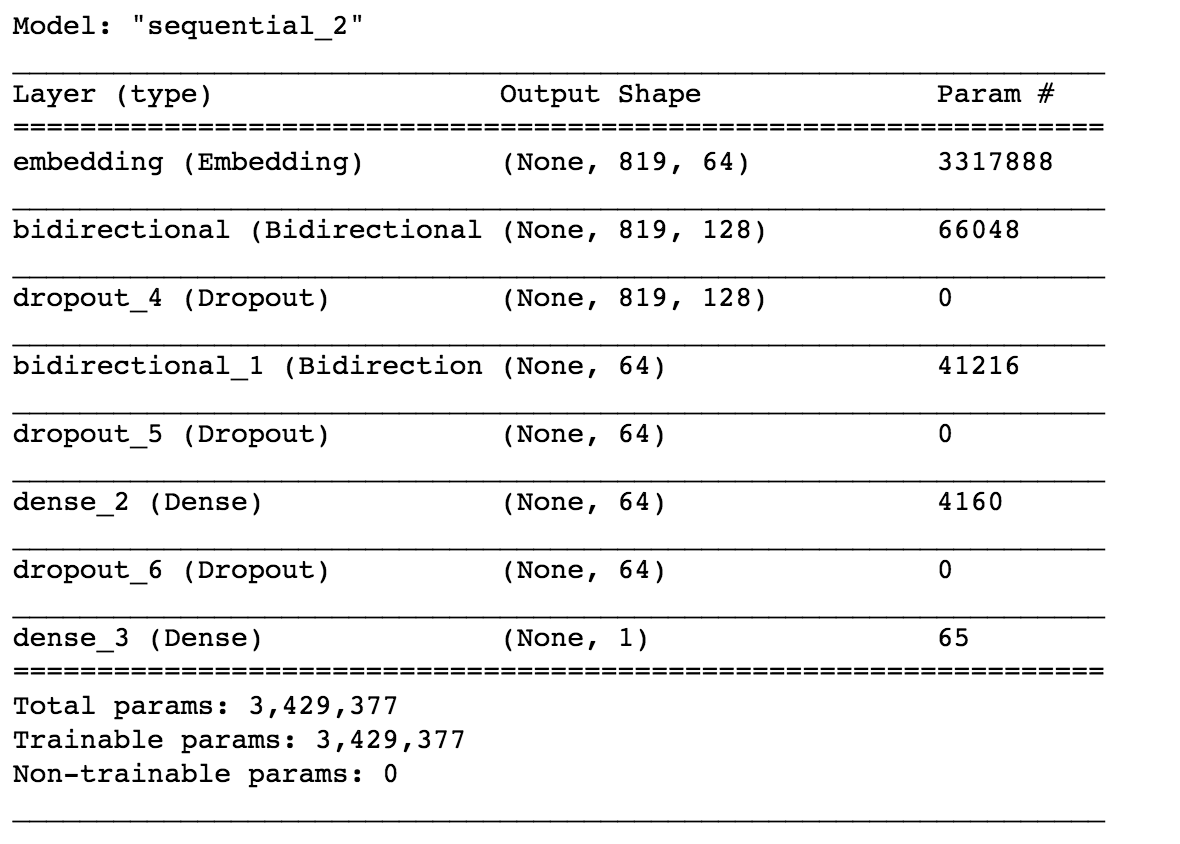
Here we have used the Bidirectional LSTM model using TensorFlow. Let’s dive into the working of the model.
First of all, we have defined an embedding layer. The embedding layer converts the words into word vectors. For example, the word “apple” can be embedded as [0.2, 0.12, 0.45]. The number of dimensions is a hyper-parameter. The purpose of using word embeddings is to find better similarities between the words, this is where the one-hot encodings fail. Here we have chosen a dimension of 64.
The model that we have used here is the stacked Bidirectional LSTM. The first Bidirectional layer is defined with 64 cells and the second layer is defined with 32 Bidirectional LSTM units. After that, we have used a Dense layer with 64 units with the activation function ReLU. The final layer is the output layer with sigmoid activation function since our problem is a binary classification problem we have used the sigmoid function. We have also used Dropout layers to prevent the phenomenon called overfitting.
We have used the Adam optimization function for backpropagation and we have used the binary cross-entropy loss function for loss and accuracy for metric. The loss function is used to optimize the model whereas the metric is used for our comparison. To know more about the working of LSTM refer to this blog.
history = model.fit(
padded_sequences,
labels.values,
epochs=10,
verbose=1,
batch_size=64
)
Now it’s time to train the model. We used 10 epochs and a batch size of 64 to train. We use the padded sequences of the reviews as the features and the sentiment as a target.

import matplotlib.pyplot as plt
fig = plt.plot(history.history['accuracy'])
title = plt.title("History")
xlabel = plt.xlabel("Epochs")
ylabel = plt.ylabel("Accuracy")
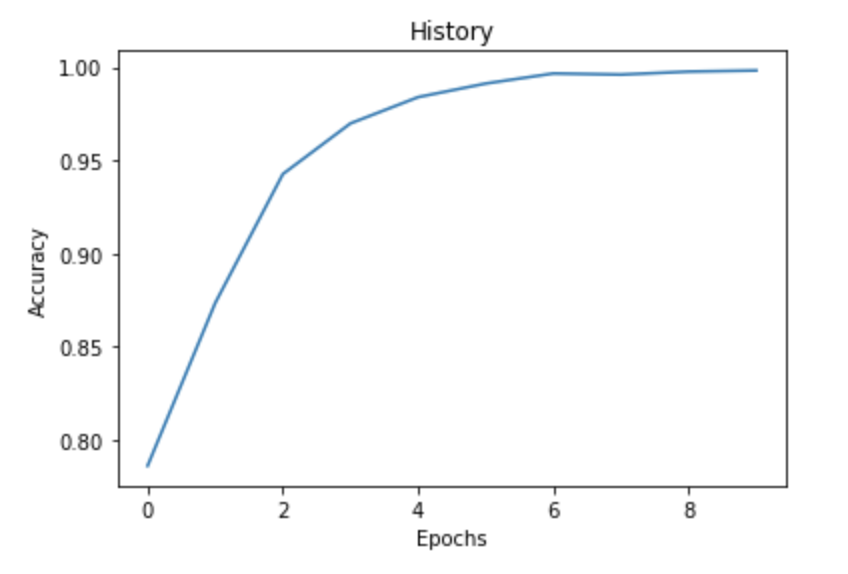
If we plot the history we can clearly see that with an increase in epochs our accuracy increases as well. We have obtained an accuracy of 99.82%.
Now that we have trained our model, we can use it to make predictions.
predictions = model.predict(padded_sequences[:4])
for pred in predictions:
print(pred[0])
We have used the first four reviews that are preprocessed and predict. We are obtaining the following result.
Output 0.99986255 0.9999008 0.99985176 0.00030466914
The output denotes the probability of positive sentiment. Let’s check whether this is right or not.

The predictions are pretty impressive. In this way, you can utilize TensorFlow to perform sentiment analysis.
Summary
In this post, we have learned the difference between rule-based sentiment analysis and automated sentiment analysis. Also, we have utilized automated sentiment analysis using deep learning to analyze the sentiments.
- Preprocess the data using spaCy. Use tokenizer to convert text to sequences.
- Use stacked Bidirectional LSTM to train the data
- Plot the history after training
- Use the trained model to make predictions
Feel free to tune the hyperparameters of the model like changing the optimizer functions, adding extra layers, changing activation functions, and also try increasing the dimensions in the Embedding vector. In this way, you will be able to achieve more refined and fine results.
Happy Deep Learning!
Connect with me on LinkedIn.