



{kind=link}
This article was published as a part of the Data Science Blogathon.
Objective
This blog post will learn how to use the Hugging face transformers functions to perform prolonged Natural Language Processing tasks.
Prerequisites
Knowledge of Deep Learning and Natural Language Processing (NLP)
Introduction
Transformers was introduced in the paper Attention is all you need; it is an encoder-decoder architecture which means input processed (encoded) by one stack is used by (decoded) by another stack to generate the output.
There are modifications around the Transforms architecture, using just the encoder stack as in BERT (Bidirectional encoder representation of transformer) or using decoder stack as in GPT (Generative Pre-trained Transformer) Architecture. T5 (Text to text transfer transformer), created by Google, uses both encoder and decoder stack.
Hugging Face Transformers functions provides a pool of pre-trained models to perform various tasks such as vision, text, and audio. Transformers provides APIs to download and experiment with the pre-trained models, and we can even fine-tune them on our datasets.
Why Use Transformers Library?
- Easy-to-use state-of-the-art models: High performance on Natural Language Understanding(NLU) & Generation(NLG), Computer Vision, and audio tasks
- Lower compute costs, smaller carbon footprint: Researchers can share trained models instead of retraining.
- Choose the proper framework for every part of a model’s lifetime: Train state-of-the-art models in 3 lines of code, pick the appropriate framework for training, evaluation, and production.
- Easily customize a model or an example to our needs: It provides examples for each architecture to reproduce the results published by its original authors.

Transformers Pipeline
Pipelines are the abstraction for the complex code behind the transformers library; It is easiest to use the pre-trained models for inference. It provides easy-to-use pipeline functions for a variety of tasks, including but not limited to, Named Entity Recognition, Masked Language Modeling, Sentiment Analysis, Feature Extraction, and Question Answering.
For the machine learning/deep learning experiment, we need to preprocess the data, train the model and write an inference script; in contrast with Pipeline functions, we need to import it and pass our raw data. The Pipeline will preprocess our data in the backend, including tokenization and padding and all the relevant processing steps for the algorithm’s input, and return the output with just a call to it.
We need to install the Transformers library to use these fantastic pipeline functions. Head over to your Jupyter notebook, local or in Google Colab(Preferred).
Install the library using pip
!pip install transformers
Now, Let’s unwrap the magic box and see how it surprise us.
First import the Pipeline from transformers library
from transformers import pipeline
Let’s begin with Sentiment Analysis.
Sentiment Analysis
Sentiment analysis is used to predict the sentiment of the text, whether the text is positive or negative. To perform sentiment analysis using Pipeline, we need to initialize the Pipeline with the ‘sentiment-analysis’ task as follows.
sentimentAnalysis_pipeline = pipeline("sentiment-analysis")

Source: Author
We can even pass a list of sentences, and the Pipeline will return inference for each of the examples in the list.
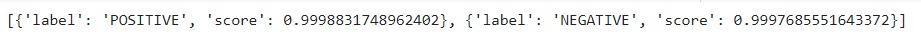
Source: Author
For the first time, the Pipeline will download the underlying model; We can even choose what model we want to use with the model parameter; by default, it uses the ‘distillery-base-uncased-finetuned-sst-2-English model.
See how easy it was; we can even train our model on custom datasets. Check out my blog to know how to fine-tune the BERT model for sentiment analysis tasks.
Have you ever imagined being a writer or poet? Well, if not, the following Pipeline can help you trigger that side.
Let’s build a text generation pipeline.
Text Generation
The model will generate the following N characters given a few words or a sentence.
We need to initialize the Pipeline with the ‘text-generation’ task.
text_gen_pipeline = pipeline('text-generation', model='gpt2')
prompt = 'Before we proceed any further, hear me speak'
text_gen_pipeline(prompt, max_length=60)

Source: Author
By default, it will return a single output of max_length provided. However, we can set the num_return_sequences parameter to output as many sequences as we want.
To learn how to build a Text generation model using LSTM, check out the Github repository.
Now let’s build our last Pipeline for the question-answering task.
Question Answering
Given a text(context) and the question, extract the answer.
For QnA, we need to initialize the Pipeline with the “question-answering” task.
context = ''' Total fees for all services paid by the Company and its subsidiaries, on a consolidated basis, to statutory auditors of the Company and other firms in the network entity of which the statutory auditors are a part, during the year ended March 31, 2021, is 59.73 crore. During the financial year 2020-21, the company issued on private placement basis and allotted, Unsecured Redeemable Non-Convertible Debentures (NCDs) of the face value of 10,00,000/- (Rupees Ten lakh) each, aggregating 24,955 crores in seven tranches as per the terms of issue of the respective tranches. Further, the third tranche of 500 crores was received from the holders of partly paid NCDs (Series IA). The funds raised through NCDs have been utilized for repayment of existing borrowings and other purposes in the ordinary course of business. '''
ans = ques_ans_pipeline({'question': 'What is the total fees paid by the company to auditors?',
'context': f'{context}'})
print(ans)

Source: Author
Excellent, the model has accurately extracted the answer for the provided question. Also, it has returned the offsets, start & end, where the answer appears in the context, and the confidence score indicates how confident the model is in the extracted solution.
The above context is taken from the 2020-2021 Annual Report of Reliance company, link in the reference section. This is just an example; however, it can be used in the financial industry to analyze the long, eye troublings reports by just asking the right questions to the model.
End Notes
We can easily use other pipelines, including text summarization, named entity recognition, language translation, and many more. With this powerful transformers functionality, we can create excellent applications without even going into the coding ground. One of the advantages of using these pre-trained models is that we don’t have to train our models from scratch, which sometimes takes days to prepare on a large volume of data, reducing our resource consumption and ultimately reducing our running cost.
References
🤗 Transformers (huggingface.co)
AnnualReport_2020-21.aspx (ril.com)
About Me
I am a Machine Learning Engineer, Solving challenging business problems through data and machine learning. Feel free to connect with me on Linkedin.
Read more blogs on Hugging Face Transformers Functions.