



{kind=link}
Introduction
Every once in a while, a machine learning framework or library changes the landscape of the field. Today, Facebook open sourced one such framework – DETR, or DEtection TRansformer.

In this article, we’ll quickly understand the concept of object detection and then dive straight into DETR and what it brings to the table.
Table of contents
Object Detection at a Glance
In Computer Vision, object detection is a task where we want our model to distinguish the foreground objects from the background and predict the locations and the categories for the objects present in the image. Current deep learning approaches attempt to solve the task of object detection either as a classification problem or as a regression problem or both.
For example, in the RCNN algorithm, several regions of interest are identified from the input image. Then these regions are classified as either objects or background and finally, a regression model is used to generate the bounding boxes for the identified objects.
The YOLO framework (You Only Look Once) on the other hand, deals with object detection in a different way. It takes the entire image in a single instance and predicts the bounding box coordinates and class probabilities for these boxes.
To learn more about object detection refer to these articles:
- A Step-by-Step Introduction to the Basic Object Detection Algorithms
- A Practical Guide to Object Detection using the Popular YOLO Framework
Introducing DEtection TRansformer (DETR) by Facebook AI
As you saw in the previous section, the current deep learning algorithms perform object detection in a multi-step manner. They also suffer from the problem of near-duplicates, i.e., false positives. To simplify, the researchers at Facebook AI has come up with DETR, an innovative and efficient approach to solve the object detection problem.
The original paper is here, the open source code is here, and you can check out the Colab notebook here.
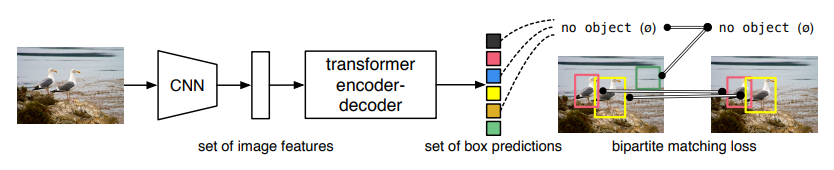
Source: https://arxiv.org/pdf/2005.12872.pdf
This new model is quite simple and you don’t have to install any library to use it. DETR treats an object detection problem as a direct set prediction problem with the help of an encoder-decoder architecture based on transformers. By set, I mean the set of bounding boxes. Transformers are the new breed of deep learning models that have performed outstandingly in the NLP domain.
The authors of this paper have evaluated DETR on one of the most popular object detection datasets, COCO, against a very competitive Faster R-CNN baseline.
In the results, the DETR achieved comparable performances. More precisely, DETR demonstrates significantly better performance on large objects. However, it didn’t perform that well on small objects. I am sure the researchers will work that out pretty soon.
Architecture of DETR
The overall DETR architecture is actually pretty easy to understand. It contains three main components:
- a CNN backbone
- an Encoder-Decoder transformer
- a simple feed-forward network
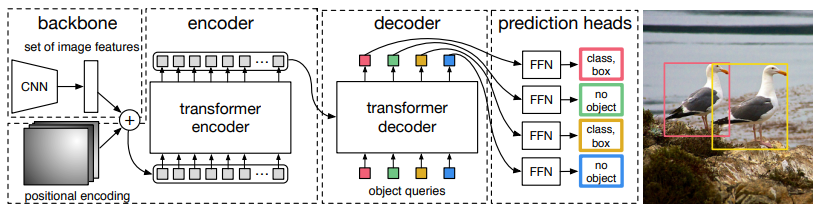
Source: https://arxiv.org/pdf/2005.12872.pdf
Here, the CNN backbone generates a feature map from the input image. Then the output of the CNN backbone is converted into a one-dimensional feature map that is passed to the Transformer encoder as input. The output of this encoder are N number of fixed length embeddings (vectors), where N is the number of objects in the image assumed by the model.
The Transformer decoder decodes these embeddings into bounding box coordinates with the help of self and encoder-decoder attention mechanism.
Finally, the feed-forward neural networks predict the normalized center coordinates, height, and width of the bounding boxes and the linear layer predicts the class label using a softmax function.
Conclusion
In summary, Facebook AI’s Detection Transformer (DETR) is a game-changer in object detection. Its unique architecture revolutionizes how computers see and understand images. Explored in “Object Detection at a Glance” and “Introducing Detection Transformer (DETR),” DETR promises better accuracy and efficiency, paving the way for exciting advancements in computer vision.
This is a really exciting framework for all deep learning and computer vision enthusiasts. A huge thanks to Facebook for sharing its approach with the community.
Time to buckle up and use this for our next deep learning project!
Frequently Asked Questions
Transformer-based object detection refers to using the Transformer architecture, initially developed for natural language processing, to enhance the accuracy and efficiency of object detection in computer vision tasks.
Depending on the application, object detection can use various sensors, such as cameras and lidar. Cameras are standard for visual-based detection, while lidar is effective for 3D mapping.
The fastest object detector can vary based on specific requirements, but models like YOLO (You Only Look Once) and Efficient are known for their speed and accuracy in real-time object detection tasks.
DETR (Detection TRansformer) is a versatile model developed by Facebook AI primarily for general object detection. While it can be adapted for face detection, specialized models, like MTCNN (Multi-task Cascaded Convolutional Networks), are commonly used for this specific task.