



{kind=link}

Introduction
The world of Natural language processing is recently overtaken by the invention of Transformers. Transformers are entirely indifferent to the conventional sequence-based networks. RNNs are the initial weapon used for sequence-based tasks like text generation, text classification, etc. But with the arrival of LSTM and GRU cells, the issue with capturing long-term dependency in the text got resolved. But learning the model with LSTM cells is a hard task as we cannot make it learn parallelly.
Transformers are alike to encoder-decoder based network with Attention layers at the end to make the model learn efficiently with the relevant context of the text. Let’s look at how to implement them the easy way using this awesome python wrapper Simple transformers
You need to create a Twitter developer account so that you can access its API and make use of a lot of incredible features. Please go through this to learn more about it.
Prerequisites
Simple Transformer models are built with a particular Natural Language Processing (NLP) task in mind. Each such model comes equipped with features and functionality designed to best fit the task that they are intended to perform. The high-level process of using Simple Transformers models follows the same pattern. We will be using the text classification module from the library for building the emotion classifier model. Install the simple transformers library by the following code.
pip install simpletransfomers
It’s better to create a virtual environment and install it. Post-installation of the package, organize your Twitter developer account by following the steps mentioned in the following link. After setting up the account get the bearer token of your account and save it in a YAML file as shown below:
search_tweets_api:
bearer_token: xxxxxxxxxxxxxxxxxxxxxxx
Modelling
For the task, we will use the following dataset from Kaggle: Emotions in Text. The dataset has two columns with one having text and the other with the corresponding emotion. Let us visualize the dataset and its class distribution.
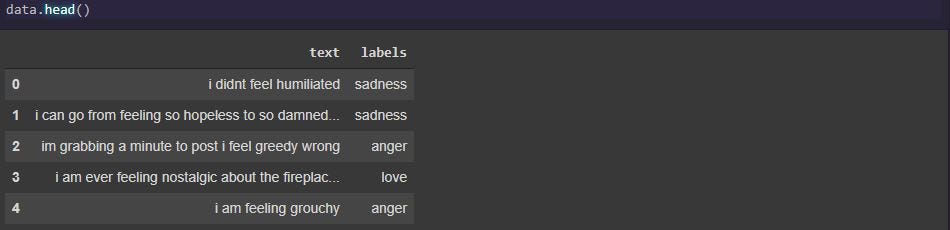
Data frame
The dataset has the following emotion classes in them: sadness, anger, love, surprise, fear, happy, and you see its distribution in the image below
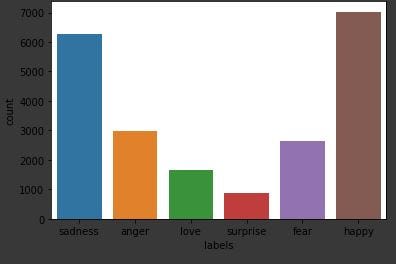
Class distribution
Before modeling the dataset, we can do some basic preprocessing steps like cleaning the text, encoding the classes with numbers, etc, so that the final dataframe looks like the following image.
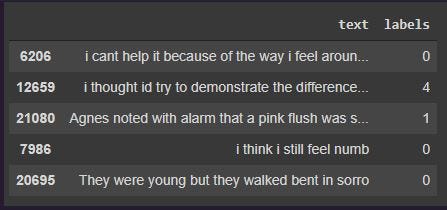
Preprocessed dataframe
I have defined the following as input configuration for the training of the model. I have used XL-Net for modeling the dataset, as it is an advanced version of transformers by able to capture context for longer sequences. The max_seq_length is kept as 64 because the maximum number of tokens found in the dataset was 66, you can increase it to a further larger value as you wish if you want to train the model for larger input of texts.
from simpletransformers.classification import ClassificationModel, ClassificationArgs
model_args = ClassificationArgs()
model_args.num_train_epochs = 4
model_args.reprocess_input_data = True
model_args.save_best_model = True
model_args.save_optimizer_and_scheduler = False
model_args.overwrite_output_dir = True
model_args.manual_seed = 4
model_args.use_multiprocessing = True
model_args.train_batch_size = 16
model_args.eval_batch_size = 8
model_args.max_seq_length = 64
model = ClassificationModel("xlnet",
"xlnet-base-cased",
num_labels=6,
args=model_args,
use_cuda=True)
Once the model is trained, you can get the metrics for the validation dataset and evaluates its performance. The model weights will be saved in the output/ directory if you haven’t configured anything before. Next comes the part where we get the tweets using Twitter API. The maximum tweets that you can use the API for are 100, which can be further increased by using a premium account. You can use the following code snippet to get tweets for a specific handle.
def create_twitter_url(handle, max_results):
mrf = "max_results={}".format(max_results)
q = "query=from:{}".format(handle)
url = "https://api.twitter.com/2/tweets/search/recent?{}&{}".format(
mrf, q
)
return url
def process_yaml():
with open("keys.yaml") as file:
return yaml.safe_load(file)
def create_bearer_token(data):
return data["search_tweets_api"]["bearer_token"]
def twitter_auth_and_connect(bearer_token, url):
headers = {"Authorization": "Bearer {}".format(bearer_token)}
response = requests.request("GET", url, headers=headers)
return response.json()
url = create_twitter_url('user',10)
data = process_yaml()
bearer_token = create_bearer_token(data)
response = twitter_auth_and_connect(bearer_token, url)
text_list = [x['text'] for x in response['data']]
cleaned_text = [re.findall(regex, x)[0] for x in text_list]
The above code gets the Twitter responses for a handle “user” and it will get the latest 10 tweets made by the corresponding handle. The tweets are cleaned to remove any emoticons, links, etc. For e.g. let us look at the emotion of the latest 20 tweets made by some famous social media chains and how is their sentiment over the same.
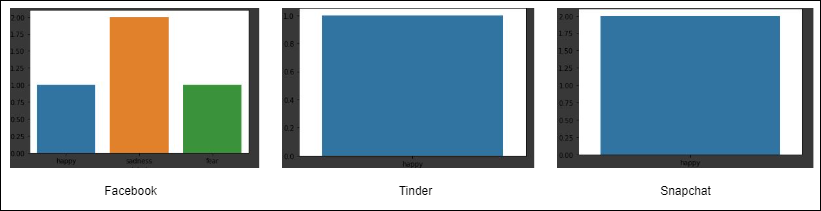
Emotion counts of those famous social media chains
Seems like Facebook didn’t have a great week as compared to the others.
So yeah we have built a simple emotion classification application using Twitter API and transformers, you can also do it in real-time and further expand this use case to analyze any violent or sad tweets from anyone you want. Thank you for spending your valuable time on this and suggestions are welcome for the same.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
About the Author

Vishnu Nkumar
Machine learning engineer with competent knowledge in innovating solutions capable of improving the business decisions in various domains. Substantial hands-on knowledge in Python, Docker, API frameworks, etc, and have deployed a lot of reusable solutions in the cloud. Ample knowledge in orchestrating the architecture of deploying solutions using either open sourced service or platform services in the cloud