



{kind=link}
Introduction
Fashion has not received much attention in AI, including Machine Learning, Deep Learning, in different sectors like Healthcare, Education, and Agriculture. This is because fashion is not considered a critical field; consider this a fun project! This is an original project meaning it has not been posted online before and can be considered an excellent creative portfolio project for attire detection!
Fashion and the local culture have not been done justice in AI. This is an exciting project where we will be building a model to classifier between 8 local African attire! This is not a regular project since the dataset is new and launched with this project. Consider this an original project and add more beauty to your data science CV.

Detecting African attires can be considered a fun project while sharpening deep learning and TensorFlow skills. Identifying these African attires according to tribes can be used in fashion apps as an added feature. Another application is when you find a local attire online and wonder what it is. No worry. This model can help you know what it is. This model could help with this uncertainty.
In a time when technology is replacing cultural heritages, the safest way is to teach AI our culture, and it will help us to preserve it.
We will develop a Machine Learning African attire detection model with the ability to detect 8 types of cultural attires.
In this project and article, we will cover the practical development of a real-world prototype of how deep learning techniques can be employed by fashionistas. Various evaluation metrics will be applied to ensure the performance of the deep learning model.
Table of Contents
Problem Statement
Most cultures are being lost to civilization and technology. In Africa, cultural heritages are being lost and forgotten. This has brought up this project idea to try to preserve these cultures and what other way than to have AI do the job. Smart systems can be developed, including Chatbots, image identifiers, and text-to-speech, to help combat culture loss and help preserve our heritages.
As discussed earlier, we will build a model to help classify eight local African attires in countries including Nigeria and South Africa. This is due to the availability of data on these tribes online. Preserving this model will help foreigners and the next generation quickly identify their cultural artifacts.

This challenge will cover deep learning, TensorFlow, and data sourcing. Prerequisites for this project are an understanding of machine learning model pipelines and experience with jupyter notebooks.
Dataset Description
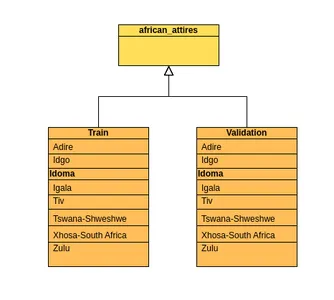
The dataset of images of African attires was gathered from the internet using the Google Chrome extension to scrape the web. The dataset is original and new; the link is found at the end of this article. It contains images belonging to 8 classes. The directory has 9784 images belonging to 8 classes for training and 2579 files belonging to 8 classes for validation of the model.
DataSet highlight:
- The dataset consists of a total of 12,363 images containing eight classes. The classes are tribes in Africa. The classes are:
- Adire (from Nigeria)
- Idgo (from Nigeria)
- Idoma (from Nigeria)
- Igala (from Nigeria)
- Tiv (from Nigeria)
- Tswana-Shweshwe (from South Africa)
- Xhosa-South Africa (from South Africa)
- Zulu (from South Africa)
- The dataset contains different views of the images organized in 1 folder with 2 subfolders representing the train and validation sets. The subfolders then contain the images accordingly.
- Some of the classes are slightly imbalanced in the number of images.
Project Pipeline
The project pipeline guides how the project will tend to go. Instead of building blindly, with the pipeline overview, anyone can get an idea of how the project was or will be done. Below are the steps involved in building the model:
- Setting up the environment
- Importing dependencies
- Loading the Dataset
- Data Cleaning
- Image Data Preprocessing
- Data Visualization
- Model Training
- Training and Evaluation
- Saving the trained model artifact
Google colab provides a hands-on environment for carrying out deep learning tasks like this. If you do not have a GPU locally installed for deep learning, you can use Google colab online. It has accessible GPUs, which makes the training time small on large datasets.
Step 1: Setting up the Environment
The recommended environment for this project is Google colab. However, you can use whichever environment so long you are confident of your actions. Colab is friendly and effective. To find the environment, you can google online for “Google Colaboratory” or visit: https://colab.research.google.com/. It is an online platform, so you do not have to install anything. It is similar to jupyter. Consequently, knowledge of Jupiter is enough to use Colab in this project. The home page looks like the one below:
Select “File” as shown above and “New notebook.” This should give you a new untitled notebook shown below.

Using Colab GPU
The benefit of using Colab is the availability of free GPU. We will have to add it to the current run-time to engage it. You can click on the “Runtime” menu in the tab at the top of the screen and select “Change runtime type,” as shown in the snapshot below:

Clicking on “Change runtime type” will provide a menu where you can find “Hardware accelerator,” click the dropdown button and select “GPU” as the hardware accelerator. This is shown below:

This engages the GPU for this notebook. Once this is done, a session is started. Since GPUs are an expensive resource, you are expected to not only engage this GPU but use it. This is why if you leave this session idle for too long, the session will die, and you will have to start again by starting the session. You are expected to manage this by not opening too many sessions simultaneously with the same user account.
You can opt for Google Colab Pro to remove all the limitations. The next step after the environment set-up is importing dependencies.
Step 2: Importing Dependencies
Importing all libraries is a good practice at the beginning of the coding. This will help people read and understand the codes easily without stress regarding the libraries used. Sometimes some of the libraries may not be known at the beginning of the project until the need arises. In such cases, we can always come back to add them here.
#Importing Required Libraries
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf #major backend
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import SequentialIn the above code, we import TensorFlow, which will be our project’s significant backend. An alternative would be PyTorch or OpenCV, but we selected TensorFlow for its performance and scalability. It has a very clean, readable code base.
Step 3: Loading of Dataset
As mentioned earlier, I have made the data set available for use, which is provided at the end of the article. A GitHub repo will be created and made available below. The link to the dataset will be available there for use. You can download the dataset to your device and then upload it to your personal google drive directly before following the next steps practically.
#Mounting Google Drive for dataset
from google.colab import drive
drive.mount('/content/drive')#Dataset directory loading
import pathlib
data_dir = "/content/drive/MyDrive/MLProjects/dataset/african_attires"
data_dir_train = "/content/drive/MyDrive/MLProjects/dataset/african_attires/Train"
data_dir_validation = "/content/drive/MyDrive/MLProjects/dataset/african_attires/Validation"Note: The above snippet must be modified to fit the location in your Google Drive.
Step 4: Data Cleaning
The dataset used was scrapped, and some of the images were corrupted in the process. Although some images are viewable, their binary is bad. These images will throw an unknown type error if used.
TensorFlow has some intolerance for image types that are not consistent. Frameworks like PyTorch may accept such images, it can still affect its performance since the images are processed internally.
Image types accepted by TensorFlow are bitmap, gif, jpeg, and png.
import cv2 #major backend for data cleaning
# Helper function for data cleaning
def check_images(s_dir, ext_list):
bad_images=[] # empty array for storing bad images
bad_ext=[] # empty array for storing bad image extensions
s_list= os.listdir(s_dir) # read the location where the images are stored
for klass in s_list: # go through the image locations in the folders/classes
klass_path=os.path.join (s_dir, klass)
print ('processing class directory ', klass)
if os.path.isdir(klass_path):
file_list=os.listdir(klass_path)
for f in file_list:
f_path=os.path.join (klass_path,f)
index=f.rfind('.')
ext=f[index+1:].lower()
if ext not in ext_list: # looping for bad images
print('file ', f_path, ' has an invalid extension ', ext)
bad_ext.append(f_path)
if os.path.isfile(f_path):
try:
img = cv2.imread(f_path)
shape = img.shape
image_contents = tf.io.read_file(f_path)
image = tf.image.decode_jpeg(image_contents, channels=3) # Checking the image internal structures to detect bad images
except Exception as e:
print('file ', f_path, ' is not a valid image file')
print(e)
bad_images.append(f_path)
else:
print('*** fatal error, you a sub directory ', f, ' in class directory ', klass)
else:
print ('*** WARNING*** you have files in ', s_dir, ' it should only contain sub directories')
return bad_images, bad_ext#Calling the helper function
source_dir = data_dir_train
good_exts=["bmp", "gif", "jpeg", "png","jpg"] # list of acceptable extensions
bad_file_list, bad_ext_list=check_images(source_dir, good_exts)
if len(bad_file_list) !=0:
print('improper image files are listed below')
print(bad_file_list)
print(bad_ext_list)The above code loops through the dataset and prints out data type that is not consistent. OpenCV is used here to look critically at the image binary.
Step 5: Image Data Preprocessing
We can reserve preprocessing until after visualization. But since our images were gotten online and are likely irregular, it is better to try to preprocess it as we would want before visualizing it. If there is a problem like blurriness, we can see it during visualization.
img_height,img_width=180,180 #setting image dimention
batch_size=32#for train datset
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir_train,
#validation_split=0.2,
#subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)The output should print the number of files found in the training set: Found 9784 files belonging to 8 classes.
#for validation datset
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir_validation,
#validation_split=0.2,
#subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)The output should print the number of files found in the training set: Found 2579 files belonging to 8 classes.
Step 6: Data Visualization
We can have a glimpse of what our images look like before training. Also, someone viewing the notebook without first seeing the dataset can know what these images look like. It is a graphical representation of the data. Particularly efficient for communicating without going through the entire dataset.
class_names = train_ds.class_names
print(class_names)The above code snippet first prints an array of the classes of the dataset in the order the model is using it. This gives:
[‘Adire’, ‘Idgo’, ‘Idoma’, ‘Igala’, ‘Tiv’, ‘Tswana-Shweshwe’, ‘Xhosa-South Africa’, ‘Zulu’]
import matplotlib.pyplot as plt
# Lopping through the trainset for sample images
plt.figure(figsize=(14, 14))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
Step 7: Model Training
At this point, the dataset is ready to be used for training. We will need to set some key parameters for training.
num_classes = 8 # number of classes is number of image directory
# Define Sequential model with 3 layers
model = Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes,activation='softmax')
])Some of these parameters and terminologies are explained briefly below:
Relu: It is an abbreviation for “rectified linear unit” (written as ReLU). It is a type of activation function that is used to introduce non-linearity to deep learning models. This solves the problem where the model may face what is called “a vanishing gradients issue”.
Padding: The number of pixels added to the edges of an image when the model kernel is processing it.
Activation: It is the parameter that decides whether a neuron should be fired. This is helpful in attaching importance to parameters during prediction.
Layers: This is used to set the nature of the layers the model will train on.
Conv2D: This parameter helps filter and determine the number of kernels to combine by forming a convolution.
#Setting the training parameters
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])epochs=10 #setting the number of passes in the model
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)The above code trains the model in 10 epochs, meaning it goes through the dataset 10 times and, each time makes a prediction as it learns. This is shown below:
Epoch 1/10
/usr/local/lib/python3.9/dist-packages/keras/backend.py:5585: UserWarning: "`sparse_categorical_crossentropy` received `from_logits=True`, but the `output` argument was produced by a Softmax activation and thus does not represent logits. Was this intended?
output, from_logits = _get_logits(
306/306 [==============================] - 498s 2s/step - loss: 1.2685 - accuracy: 0.5346 - val_loss: 3.3806 - val_accuracy: 0.2602
Epoch 2/10
306/306 [==============================] - 56s 179ms/step - loss: 0.7726 - accuracy: 0.7296 - val_loss: 3.9734 - val_accuracy: 0.3695
Epoch 3/10
306/306 [==============================] - 56s 181ms/step - loss: 0.4911 - accuracy: 0.8325 - val_loss: 4.3418 - val_accuracy: 0.3808
Epoch 4/10
306/306 [==============================] - 56s 180ms/step - loss: 0.2632 - accuracy: 0.9153 - val_loss: 5.4616 - val_accuracy: 0.4102
Epoch 5/10
306/306 [==============================] - 57s 183ms/step - loss: 0.1420 - accuracy: 0.9586 - val_loss: 6.2114 - val_accuracy: 0.4188
Epoch 6/10
306/306 [==============================] - 57s 183ms/step - loss: 0.0970 - accuracy: 0.9747 - val_loss: 7.2962 - val_accuracy: 0.4234
Epoch 7/10
306/306 [==============================] - 56s 181ms/step - loss: 0.0831 - accuracy: 0.9787 - val_loss: 6.9264 - val_accuracy: 0.4122
Epoch 8/10
306/306 [==============================] - 57s 182ms/step - loss: 0.0637 - accuracy: 0.9859 - val_loss: 7.9563 - val_accuracy: 0.4331
Epoch 9/10
306/306 [==============================] - 57s 180ms/step - loss: 0.0523 - accuracy: 0.9879 - val_loss: 7.9776 - val_accuracy: 0.4234
Epoch 10/10
306/306 [==============================] - 56s 178ms/step - loss: 0.0655 - accuracy: 0.9828 - val_loss: 8.0845 - val_accuracy: 0.4149
Step 8: Training and Evaluation
For us to evaluate our model performance, we look at the training loss, accuracy, and validation loss and accuracy.
Training loss: The training loss provides a metric for assessing how our deep learning model fits the training set. It estimates the error value of the model on the training set.
Training Accuracy: Training accuracy represents how well the model identifies the images it was trained on. Our model here shows a high training accuracy, meaning it trained well. But we must justify this by introducing a validation set to see if it has actually learned well.
Validation loss: We have merged the training loss and validation loss, a common practice. The validation loss shows how well our model fits the validation set. The error here is high compared to the training loss.
Validation Accuracy: The validation set here accesses the trueness of the training result. Our project shows an average accuracy of 43%. This means our model requires more training. Something to do could be to increase the dataset size or adjust some of the parameters accordingly.
Step 9: Deployment
Finally, to exit our model training to deployment, the model needs to be saved for further use. This is done here using the save_model function from keras. The model could be used as an artifact in a web or local app.
#saving the model
tf.keras.models.save_model(model,'my_model.hdf5')Conclusion
In this article, we have trained a deep learning model to make predictions and classify images of local African attires. We web scrapped over 12,000 images and grouped them into 8 classes of attires, including Adire, Idgo, Idoma, Igala, Tiv, Tswana-Shweshwe, Africa, and Zulu. Although the accuracy shows an average performance, we can further improve this personal project by adding more images or adjusting the parameters.
The model can be deployed using streamlit, Heroku, or any web service. Or even locally on your machine.
Key takeaways:
- This project covered the practical development of a real-world prototype of deep learning techniques utilized by fashionistas. Various suitable evaluation metrics were applied.
- The dataset of African attire detection was gathered from the internet. The dataset is original and new, and the link is available at the article’s end.
- The dataset contains images belonging to 8 classes. The directory has 9784 images belonging to 8 classes for training and 2579 files belonging to 8 classes for validation of the model.
- The recommended environment is Google colab, where the model was developed with an average accuracy of 43%.
Links:
- GitHub repository: https://github.com/inuwamobarak/african_attire_detector
- Dataset: Click here.