



{kind=link}
Introduction
I love reading and decoding machine learning research papers. There is so much incredible information to parse through – a goldmine for us data scientists! I was thrilled when the best papers from the peerless ICLR 2019 (International Conference on Learning Representations) conference were announced.
I couldn’t wait to get my hands on them.
However, the majority of research papers are quite difficult to understand. They are written with a specific audience in mind (fellow researchers) and hence they assume a certain level of knowledge.

I faced the same issue when I first dabbled into these research papers. I struggled mightily to parse through them and grasp what the underlying technique was. That’s why I decided to help my fellow data scientists in understanding these research papers.
There are so many incredible academic conferences happening these days and we need to keep ourselves updated with the latest machine learning developments. This article is my way of giving back to the community that has given me so much!
In this article, we’ll look at the two best papers from the ICLR 2019 conference. There is a heavy emphasis on neural networks here so in case you need a refresher or an introduction, check out the below resources:
- An Introductory Guide to Deep Learning and Neural Network
- Fundamentals of Deep Learning – Introduction to Recurrent Neural Networks (RNNs)
- Computer Vision using Deep Learning 2.0
And the Best Paper Award at ICLR 2019 Goes To:
- Ordered Neurons: Integrating Tree Structures Into Recurrent Neural Networks (RNNs)
- The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Let’s break down these two incredible papers and understand their approaches.
Ordered Neurons: Integrating Tree Structures Into Recurrent Neural Networks
The structure of a natural language is hierarchical. This means that larger units or constituents comprise of smaller units or constituents (phrases). This structure is usually tree-like.
While the standard LSTM architecture allows different neurons to track information at different time scales, it does not have an explicit bias towards modeling a hierarchy of units. This paper proposes to add such an inductive bias by ordering the neurons.
Objective of this Paper
The researchers aim to integrate a tree structure into a neural network language model. The reason behind doing this is to improve generalization via better inductive bias and at the same time, potentially reduce the need for a large amount of training data.
What’s the Previous State-of-the-Art?
- One way of predicting the corresponding latent tree structure is through a supervised syntactic parser. Trees produced by these parsers have been used to guide the composition of word semantics into sentence semantics. This also helps in the next word prediction given previous words.
- However, supervised parsers are limiting for several reasons:
- Few languages have comprehensive annotated data for supervised parser training
- Syntax rules tend to be broken in some domains (e.g. in tweets), and
- Languages change over time with use, so syntax rules may evolve
- Recurrent neural networks (RNNs) have proven highly effective at the task of language modeling. RNNs explicitly impose a chain structure on the data. This assumption may seem at odds with the latent non-sequential structure of language.
- It may pose several difficulties for the processing of natural language data with deep learning methods, giving rise to problems such as capturing long-term dependencies, achieving good generalization, handling negation, etc. Meanwhile, some evidence exists that LSTMs with sufficient capacity potentially implement syntactic processing mechanisms by encoding the tree structure implicitly
If you want to know more about LSTM applications, you can read our guides:
- Essentials of Deep Learning: Introduction to Long Short Term Memory (LSTM)
- Automatic Image Captioning using Deep Learning (CNN and LSTM) in PyTorch
And if you prefer learning via video, you can take the below course which has a healthy dose of LSTM:
New Method Proposed in this Paper
This is where things become really interesting (and really cool for all you nerds out there!).
This paper proposes Ordered Neurons. It is a new inductive bias for RNN that forces neurons to represent information at different time-scales.
This inductive bias helps to store long-term information in high-term neurons. The short-term information (that can be rapidly forgotten) is kept in low ranking neurons.
A new RNN unit – ON-LSTM – is proposed. The new model uses an architecture similar to the standard LSTM:

The difference is that the update function for the cell state ct is replaced with a new function cumax().
It might be difficult to discern a hierarchy of information between the neurons since the gates in an LSTM act independently on each neuron. So, the researchers have proposed to make the gate for each neuron dependent on the others by enforcing the order in which neurons should be updated.
Pretty fascinating, right?
ON-LSTM includes a new gating mechanism and a new activation function cumax(). The cumax() function and LSTM are combined together to create a new model ON-LSTM. That explains why this model is biased towards performing tree-like composition operations.
Activation Function: cumax()
I wanted to spend a few moments talking about the cumax() function. It is the key to unlocking the approach presented in this awesome paper.
This cumax() activation function is introduced to enforce an order to the update frequency:
g^= cumax(…) = cumsum(softmax(…)),
Here, cumsum denotes the cumulative sum. “g^” can be seen as an expectation of a binary gate, “g”, which splits the cell state into two segments:
- 0-segment
- 1-segment
Thus, the model can apply different update rules on each segment to differentiate long/short information.
Structured Gating Mechanism
The paper also introduces a new master forget gate ft and a new master input gate it. These entities are also based on the cumax() function.
The values in the master forget gate monotonically increase from 0 to 1 by following the properties of the cumax() function. A similar thing happens in the master input gate where the values monotonically decrease from 1 to 0.
These gates serve as high-level control for the update operations of cell states. We can define a new update rule using the master gates:

Experiment and Results
The researchers evaluated their model on four tasks:
- Language modeling
- Unsupervised constituency parsing
- Targeted syntactic evaluation
- Logical inference
Here are the final results:
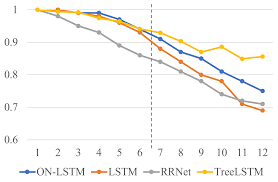
The horizontal axis indicates the length of the sequence, and the vertical axis indicates the accuracy of models performance on the corresponding test set. The ON-LSTM model gives an impressive performance on sequences longer than 3.
The ON-LSTM model shows better generalization while facing structured data with various lengths. A tree-structured model can achieve quite a strong performance on this dataset.
Summarizing the Paper
- A new inductive bias Ordered Neurons for RNN is introduced
- Based on this idea, a new recurrent unit, the ON-LSTM is proposed which includes a new gating mechanism and a new activation function cumax()
- This helps RNN to perform tree-like composition operation, by separately allocating hidden state neurons with long and short term information.
- The model performance shows that ON-LSTM induces the latent structure of natural language in a way that is coherent with human expert annotation
- The inductive bias also enables ON-LSTM to achieve good performance on language modeling, long-term dependency, and logical inference tasks
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
This is one of my favorite papers of 2019. Let’s break it down into easy-to-digest sections!
Pruning is the process of removing unnecessary weights from neural networks. This process potentially reduces the parameter-counts by more than 90% without affecting the accuracy. It also decreases the size and energy consumption of a trained network, making our inference more efficient.
However, if a network can be reduced in size, why don’t we train this smaller architecture instead to make training more efficient?
This is because the architectures uncovered by pruning are harder to train from the beginning and bring down the accuracy significantly.
Objective of this Paper
This paper aims to show that there exist smaller sub-networks that train from the start. These networks learn at least as fast as their larger counterpart while achieving similar test accuracy.
For instance, we randomly sample and train sub-networks from a fully connected network for MNIST and convolutional networks for CIFAR10:

The dashed lines trace the iteration of minimum validation loss and the test accuracy at that iteration across various levels of sparsity. The sparser the network, the slower the learning and the lower the eventual test accuracy.
This is where the researchers have stated their lottery ticket hypothesis.
Lottery Ticket Hypothesis
A randomly-initialized, dense neural network contains a sub-network, labeled as winning tickets. This is initialized such that, when trained in isolation, it can match the test accuracy of the original network after training for at most the same number of iterations.
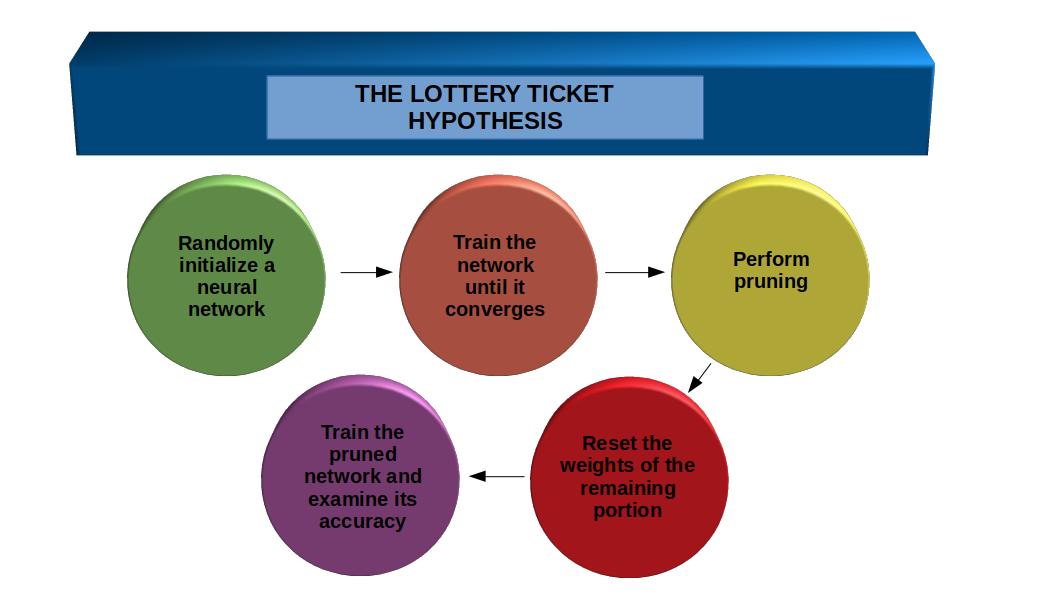
Here is a superb illustration of the lottery ticket hypothesis concept:
Identifying Winning Tickets
We identify a ticket by training its network and pruning its smallest-magnitude weight. The remaining, unpruned connections constitute the architecture of the winning ticket.
Each unpruned connection’s value is then reset to its initialization from the original network before it was trained.
The process for doing this involves an iterative process of smart training and pruning. I have summarized it in five steps:
- Randomly initialize a neural network
- Train the network until it converges
- Perform pruning
- To extract the winning ticket, reset the weights of the remaining portion of the network to their values from step 1
The pruning is one shot, which means it is done only once.
But in this paper, the researchers focus on iterative pruning, which repeatedly trains, prunes, and resets the network overground. Each round prunes p^(1/n) % of the weights that survive the previous round.
As a result, this iterative pruning finds winning tickets that match the accuracy of the original network at smaller sizes as compared to one-shot pruning.
Applications
A question that comes to everyone’s mind when reading these research papers – where in the world can we apply this? It’s all well and good experimenting and coming up trumps with a new approach. But the jackpot is in converting it into a real-world application.
This paper can be super useful for figuring out the winning tickets. Lottery Ticket Hypothesis could be applied on fully-connected networks trained on MNIST and on convolutional networks on CIFAR10, increasing both the complexity of the learning problem and the size of the network.
Existing work on neural network pruning demonstrates that the functions learned by a neural network can often be represented with fewer parameters. Pruning typically proceeds by training the original network, removing connections, and further fine-tuning.
In effect, the initial training initializes the weights of the pruned network so that it can learn in isolation during fine-tuning.
The Importance of Winning Ticket Initialization
A winning ticket learns more slowly and achieves lower test accuracy when it is randomly reinitialized. This suggests that initialization is important to its success.
The Importance of Winning Ticket Structure
The initialization that gives rise to a winning ticket is arranged in a particular sparse architecture. Since we uncover winning tickets through heavy use of training data, we hypothesize that the structure of our winning tickets encodes an inductive bias customized to the learning task at hand.
Limitation and Future Work
The researchers are aware that this isn’t the finished product yet. The current approach has a few limitations which could be addressed in the future:
- Larger datasets are not investigated. Only vision-centric classification tasks on smaller datasets are considered.
- These researchers intend to explore more efficient methods for finding winning tickets that will make it possible to study the lottery ticket hypothesis in more resource-intensive settings
- Sparse pruning is our only method for finding winning tickets.
- The researchers intend to study other pruning methods from the extensive contemporary literature, such as structured pruning (which would produce networks optimized for contemporary hardware) and non-magnitude pruning methods (which could produce smaller winning tickets or find them earlier)
- The winning tickets found have initializations that allow them to match the performance of the unpruned networks at sizes too small for randomly-initialized networks to do the same.
- The researchers intend to study the properties of these initializations that, in concert with the inductive biases of the pruned network architectures, make these networks particularly adept at learning
End Notes
In this article, we thoroughly discussed the two best research papers published in ICLR. I learned so much while going through these papers and understanding the thought process of these research experts. I encourage you to go through these papers yourself once you finish this article.
There are a couple of more research focused conferences coming up soon. The International Conference on Machine Learning (ICML) and the Computer Vision and Pattern Recognition (CVPR) conferences are lined up in the coming months. Stay tuned!