



{kind=link}
This article was published as a part of the Data Science Blogathon
Introduction
We all want to dive deep into deep learning and explore the various tasks we can perform like building a robot or translating Spanish to English to enjoy your favorite Netflix series. To go deep we must start from the basics. The basic building block of a neural network will help us understand how we are processing the data as we do in our brain. This article will understand neural networks from scratch and how we can build one using Pytorch.
Biological Neural Networks(BNN):
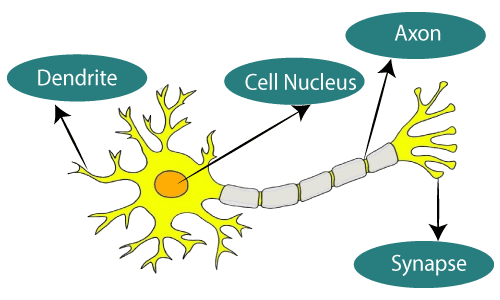
Biological neural networks were the main inspiration for building Artificial neural networks to mimic them so that machines can perform complex tasks and think as humans do. The neuron is the main unit of the neural network. It consists of the cell body known as soma, dendrites, and the axon. The connections are by fibers and branched together by dendrites in multiple directions in a complex way. They receive signals from nearby neurons and we have the axons to transfer the signals to other neurons. The contact with dendrite at the end is made using a synapse. Like a domino effect, impulses are passed from one neuron to another.
Artificial Neural Networks(ANN):
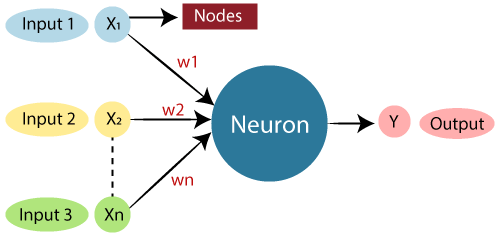
An artificial neural network is build based on the idea to mimic how the human brain works. We could say it is a mathematically modeled human brain with lesser complexity. Like our BNN, the ANN has different features coming into a neuron with specific weights associated with their learning pattern and then output is fired from the neuron. These features are the inputs to neurons like the dendrites in BNN. These nodes are like the cell nucleus and weights are represented by the synapses with Axon for output. The artificial neural networks consist of an input layer, hidden layers, and an output layer. The input layer accepts all the inputs provided to it. These could be attribute features for classifying your favorite pokemon or images to find if it is a cat or a dog. Hidden layers are between input and output and are used to find the patterns associated with the problem. This is the layer that learns by updating its weights. Output layer could be a single neuron, like in the case of predicting the next word in a sentence, two neurons to get the probability of an image being cat or dog, or many neurons for classification using a softmax like in CIFAR-10.
An artificial neural network basically takes up inputs and calculates the weighted sum of these inputs. In addition, a bias term is added to this.
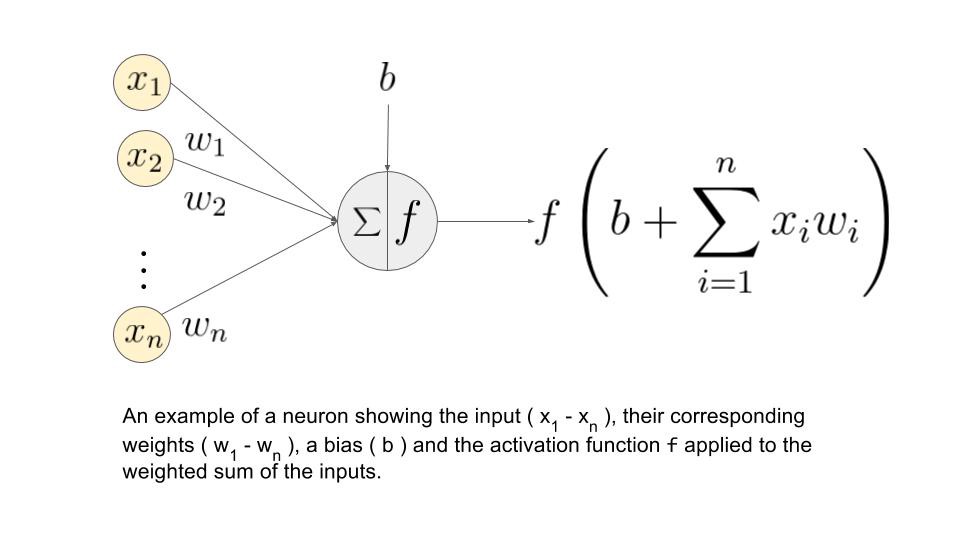
This weighted sum with bias is passed to an activation function like sigmoid, RElu, tanH, etc… And the output from one neuron act as input to the next layer in neural networks. A neural network when having more than one hidden layer is called a Deep neural network. We can go deep as we increase the hidden layers in the network. We should know going very deep is also not good as the network can suffer a problem called degradation. There are many methods to build deep networks without suffering this issue like using residue blocks. In case you want to know more about it you can refer here.
Refer to this video by Andre NG for understanding more about Biological and Artificial networks and how they are similar or different:
Working of ANN:
The input layers are connected with each of the hidden layers and from hidden to output by weighted directed graphs. These edges make connections from one neuron in a hidden layer to every other neuron in the next hidden layer. After that, each input is multiplied by the corresponding weights (these weights associated are the data used by artificial neural networks to solve a specific problem). These neurons usually represent the ability to connect within a neural artificial network. All weighted inputs are summarized within the computing unit. If the weighted sum equals zero, then we use the bias term and add it to make the output non-zero. Bias takes the same input, and the weight equals 1. Here the total input weight can be from 0 to any positive number. In neural networks, weights are updated in a process called backpropagation.
In a feed-forward neural network, there is only a flow of values from input to output and in one direction. Here there is no weight updation and is just used to provide output in one pass. In the case of backpropagation, we have a loss function in the output end. The result we got in output is compared in the loss function and based on this, the flow goes in the backward direction where updation of weights takes place. In this way, the model learns to solve that specific task by updating the weights.
Implementation of Artificial Neural Networks using PyTorch:
For implementation, we will use a python library called PyTorch. PyTorch is widely used and has almost all the state-of-the-art models implemented within it.
We need to import all the packages first.
import os import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets, transforms
torch is the package for importing PyTorch. We have a package called nn which is a neural network in the torch that we will be using to build our model.
Even though it’s not necessary for us but sometimes we may have to train large datasets like images, audio, etc… and with CPU it wouldn’t be sufficient. In such a case, we want to make use of GPU. For this we use Cuda.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('Using {} device'.format(device))
The next step is building our Neural networks model. Here, we intend to build a simple model using the nn package we imported earlier. To do so we need to define a class and pass nn.Module as the parameter.
class NeuralNetwork(nn.Module): def __init__(self): super(NeuralNetwork, self).__init__() self.flatten = nn.Flatten() self.linear_relu_stack = nn.Sequential( nn.Linear(28*28, 512), nn.ReLU(), nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 10), nn.ReLU() )
def forward(self, x): x = self.flatten(x) logits = self.linear_relu_stack(x) return logits
The init is a standard function in python and we can use it to initialize our model. We must create two functions to get our model ready. One is the init and the other is the forward. The super call has used that delegates the function call to its parent class, which is nn.Module in our case. This is needed to initialize the nn.Module in a proper manner. Now when we use images they are represented in multidimensional matrix format. So in our case when we pass into neural networks we can only pass features and the input layer. So for this purpose, we use flatten function. We have to build a very basic neural network with inputs passed into the ReLU activation function and then to another linear layer to ReLU function and the last layer has 10 features that are used to get the probability of each class so that we can use the output with highest probability value as our desired class. The forward is used to run this initialized function.
We can print the model we build,
model = NeuralNetwork().to(device) print(model)
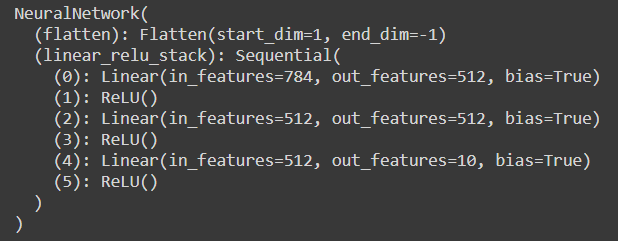
The in_features here tell us about how many input neurons were used in the input layer. We have used two hidden layers in our neural network and one output layer with 10 neurons. In this manner, we can build our neural network using PyTorch.
References:
https://www.javatpoint.com/artificial-neural-network
https://pytorch.org/tutorials/beginner/basics/buildmodel_tutorial.html
Conclusion:
Preview Image Source: https://www.codeproject.com/KB/AI/1200392/machine_learning.jpg
About Me: I am a Research Student interested in the field of Deep Learning and Natural Language Processing and currently pursuing post-graduation in Artificial Intelligence.
Feel free to connect with me on:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698