



{kind=link}
This article was published as a part of the Data Science Blogathon
Objective
The main aim of this article is to detect age and gender through the given data set. We will use simple python and Keras methods for detecting age and gender. The data set can be downloaded from AGE, GENDER AND ETHNICITY (FACE DATA) CSV | Kaggle.
Introduction
The upgrading of image pictures taken from the camera sources, from satellites, aeroplanes, and the images caught in everyday lives is called picture processing. Processing of the image based on analysis undergoes many different techniques and calculations. Digital formed pictures need to be carefully imagined and studies.
Image processing has two main steps followed by simple steps. The improvement of an image with the end goal of more good quality pictures; that can be adopted by other programs are called picture upgrades. The other procedure is the most pursued strategy utilized for the extraction of data from a picture. The division of images into certain parts is called segmentation.
The location of the information accessible in the pictures is much-needed information. The information that the image contains is to be changed and adjusted for discovery purposes.
There are different sorts of procedures required for, just as the expulsion of the issue. In a Facial identification strategy: The articulations that the faces contain hold a great deal of data. At whatever point the individual associates with the other individual, there is an association of a ton of ideas.
The evolving of ideas helps in figuring certain boundaries. Age assessment is a multi-class issue in which the years; are categorized into classes. Individuals of various ages have various facials, so it is hard to assemble the pictures.
To identify the age and gender of several faces’ procedures, are followed by several methods. From the neural network, features are taken by the convolution network. In light of the prepared models, the image is processed into one of the age classes. The highlights are handled further and shipped off the preparation frameworks.
The Dataset
UTK Dataset comprises age, gender, images, and pixels in .csv format. Age and gender detection according to the images have been researched for a long time. Different methodologies have been assumed control over the years to handle this issue. Presently we start with the assignment of recognizing age and gender utilizing the Python programming language.
Keras is the interface for the TensorFlow library. Use Keras on the off chance that you need a profound learning library that allows simple and quick prototyping (through ease of use, seclusion, and extensibility). Support both convolutional networks and repetitive organizations, just as blends of the two. Run flawlessly on CPU and GPU.
Code-
#Import libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def plot_data(rows, cols, lower_value, upper_value):
fig = plt.figure(figsize=(cols*3,rows*4))
for i in range(1, cols*rows + 1):
k = np.random.randint(lower_value,upper_value)
fig.add_subplot(rows, cols, i) # adding sub plot
gender = gender_values_to_labels[df.gender[k]]
ethnicity = eth_values_to_labels[df.ethnicity[k]]
age = df.age[k]
im = df.pixels[k]
plt.imshow(im, cmap='gray')
plt.axis('off')
plt.title(f'Gender:{gender}nAge:{age}nEthnicity:{ethnicity}')
plt.tight_layout()
plt.show()
plot_data(rows=1, cols=7, lower_value=0, upper_value=len(df))

Fig 1 Age and gender detection by a simple python
Keras
Keras is an open-source Neural Network library. It is written in Python and is sufficiently fit to run on Theano, TensorFlow, or CNTK, developed by one of the Google engineers, Francois Chollet. It is made easy to understand, extensible, and particular for quicker experimentation with profound neural organizations.
First of all, we will upload all libraries required for the data set. We will convert all the columns into an array by using the np.array and into dtype float. We will then split the data set into xTrain, yTrain, yTest, and xtest. In the end, we will apply the model sequential and test the predictions.
In detail, first, we read the CSV file containing five columns age, ethnicity, gender, img_name, and pixels by using pandas, read_csv function. The first five rows got by using DataFrame.head() method. We converted the column-named pixels into an array by using the NumPy library and Reshaping them into dimensions 48, 48 by using the lambda function. We also converted the values in the float by the same lambda function.
We divided the values further by 255.
We assigned the variable name to get the first row of the column of the pixel. We further checked the image by using matplotlib if it is seen or not.
#importing libraries
import keras import json import sys import tensorflow as tf from keras.layers import Input import numpy as np import argparse from keras_applications.resnext import ResNeXt50 from keras.utils.data_utils import get_file import face_recognition
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import cv2
from PIL import Image
df=pd.read_csv("age_gender.csv")df.head()df1= pd.DataFrame(df)
df1['pixels'] = df1.pixels.apply(lambda x: np.reshape(np.array(x.split(' '),dtype='float32'),(48,48)))
df1['pixels']= df1['pixels']/255
im = df1['pixels'][0]
im
plt.imshow(im, cmap='gray')
plt.axis('off')
Fig 2 Image after reshaping
To convert all the values into float and reshape it, we used function for and NumPy. To have the age and gender stored in the list, we will use the other variable labels_f. A later model will be used to fit the data and validate it.
#To collect all the images and reshape them and check the dtype.
X = np.zeros(shape=(23705,48,48))
for i in range(len(df1["pixels"])):
X[i] = df1["pixels"][i]
X.dtype
Output - dtype('float64')
#Age
ag = df1['age']
ag=ag.astype(float)
ag= np.array(ag)
ag.shape
output- (23705,)
#Gender
g= df1['gender']
g=np.array(g)
g.shape
(23705,)
labels_f =[] i=0 while i <len(a): label=[] label.append([a[i]]) label.append([g[i]]) labels_f.append(label) i+=1 Both age and gender are combined and stored in labels_f, we will further convert the list into array. labels_f =np.array(labels_f) labels_f.shape
(23705, 2, 1) Using the most used machine learning library, sklearn, the data is split into train and test.
#Splitting the data taking data set
import tensorflow as tf from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test= train_test_split(X,a,test_size=0.25) print(X_test.shape) print(X_train.shape) print(Y_test.shape) print(Y_train.shape)
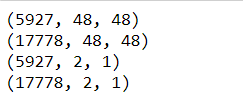
Fig 3 Shape output of X_train, X_test, Y_train, and Y_test
Y_train_2=[Y_train[:,1],Y_train[:,0]] Y_test_2=[Y_test[:,1],Y_test[:,0]]
#Model
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten,BatchNormalization
from tensorflow.keras.layers import Dense, MaxPooling2D,Conv2D
from tensorflow.keras.layers import Input,Activation,Add
from tensorflow.keras.models import Model
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
def Convolution(input_tensor,filters):
x = Conv2D(filters=filters,kernel_size=(3, 3),padding = 'same',strides=(1, 1),kernel_regularizer=l2(0.001))(input_tensor)
x = Dropout(0.1)(x)
x= Activation('relu')(x)
return x
def model(input_shape):
inputs = Input((input_shape))
conv_1= Convolution(inputs,32)
maxp_1 = MaxPooling2D(pool_size = (2,2)) (conv_1)
conv_2 = Convolution(maxp_1,64)
maxp_2 = MaxPooling2D(pool_size = (2, 2)) (conv_2)
conv_3 = Convolution(maxp_2,128)
maxp_3 = MaxPooling2D(pool_size = (2, 2)) (conv_3)
conv_4 = Convolution(maxp_3,256)
maxp_4 = MaxPooling2D(pool_size = (2, 2)) (conv_4)
flatten= Flatten() (maxp_4)
dense_1= Dense(64,activation='relu')(flatten)
dense_2= Dense(64,activation='relu')(flatten)
drop_1=Dropout(0.2)(dense_1)
drop_2=Dropout(0.2)(dense_2)
output_1= Dense(1,activation="sigmoid",name='sex_out')(drop_1)
output_2= Dense(1,activation="relu",name='age_out')(drop_2)
model = Model(inputs=[inputs], outputs=[output_1,output_2])
model.compile(loss=["binary_crossentropy","mae"], optimizer="Adam",
metrics=["accuracy"])
return model
Model=model((48,48,1)) Model.summary()
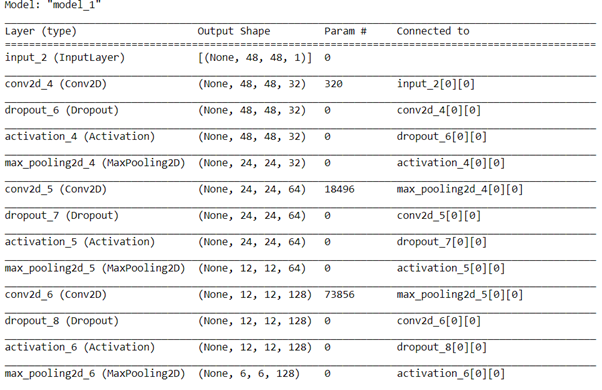
Fig 4 Model summary in details
History=Model.fit(X_train,Y_train_2,batch_size=64,validation_data=(X_test,Y_test_2),epochs=5,callbacks=[callback_list])
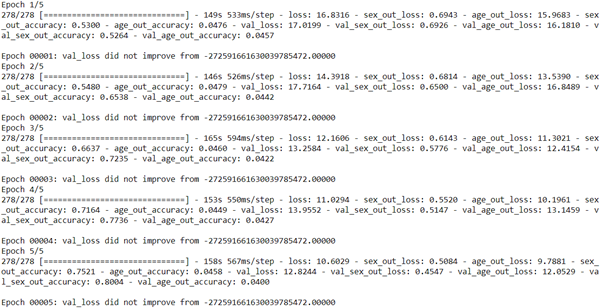
Model.evaluate(X_test,Y_test_2)

pred=Model.predict(X_test) pred[1]
#Plot the image
def test_image(ind,X,Model):
plt.imshow(X[ind])
image_test=X[ind]
pred_1=Model.predict(np.array([image_test]))
sex_f=['Female','Male']
age=int(np.round(pred_1[1][0]))
sex=int(np.round(pred_1[0][0]))
print("Predicted Age: "+ str(age))
print("Predicted Sex: "+ sex_f[sex])
test_image(1980,X, Model)
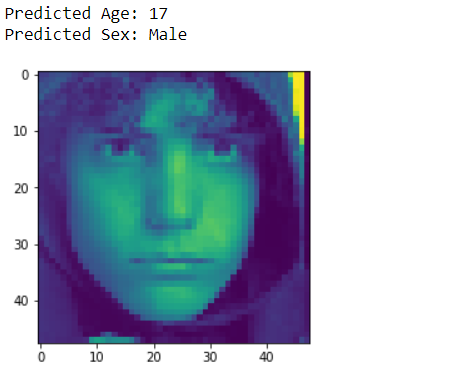
Fig 5 Age and gender detection by model.
Frequently Asked Questions
A. Age and gender prediction finds applications in various fields, including targeted advertising, market research, customer segmentation, and personalized user experiences. It helps businesses tailor their products and services to specific demographics and analyze consumer behavior. Additionally, it aids in age and gender-based content recommendations, social media marketing strategies, and public health initiatives, allowing for more effective and targeted campaigns.
A. Age and gender prediction algorithms can be reasonably accurate, but their performance can vary depending on the dataset used for training and the specific model employed. While they often achieve high accuracy rates, there may be occasional mis-classifications due to factors like diverse appearances, age-related changes, and cultural variations. Continuous improvement in technology and data quality can enhance their precision further.
Conclusion
The task of recognizing age and gender, nonetheless, is an innately troublesome issue, more so than numerous other PC vision undertakings. The fundamental justification for this trouble hole lies in the information needed to prepare these kinds of frameworks. While general article discovery errands can regularly approach many thousands or even large numbers of pictures for preparing, datasets with age and gender names are extensively more modest, as a rule in the large numbers or, best case scenario, several thousand. Python obtained images and the Model did not do well much in the accuracy rate, further, improvement is required in the model algorithm.
A small introduction about myself-
I, Sonia Singla have done MSc in Biotechnology from Bangalore University, India and an MSc in Bioinformatics from University of Leicester, U.K. I have also done a few projects on data science from CSIR-CDRI. Currently is an advisory editorial board member at IJPBS. Have reviewed and published few research papers in Springer, IJITEE and various other Publications. You can contact me or reach to me on Linkedin. Thanks
Linkedin – https://www.linkedin.com/in/soniasinglabio/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.