



{kind=link}
This article was published as a part of the Data Science Blogathon
Introduction
If you are a beginner in the field of neural networks, then mostly you might have trained your models using CPU. Well, it is ok even if your model is having 100000 parameters, it may take some hours to train the model. But what if your model is having 10 billion or 20 billion parameters? The common CNN model like VGG16 has 138 million parameters, so training models like these using CPU will be a problem as it would take a lot of your precious time. In this article, we will be discussing how GPU will be solving this problem for us and have hands-on experience training a simple model using GPU.
Why GPU is better than CPU in certain tasks?
Rather than me introducing its benefits, trust me this amazing video will give you a better idea.
source: The mythbusters, Adam Savage and Jamie Hyneman demonstrate the power of GPU computing.
Now you might have got an idea right? Yes, this massive parallel computing power of the GPU tremendously helps us to boost the performance and decrease the training time of a complex neural network model. GPU contains a large number of inbuilt smaller cores which helps in this task.
The most fundamental operation in neural networks is the matrix multiplication, GPUs are very good at this tasks and it solves these computations like a professional mathematician who is specialized in matrix multiplication. Some other advantages of GPU over CPU are :
- It has larger memory bandwidth.
- The smaller size of L1 and L2 caches help in accessing cache memory faster.
For the efficient usage of the multiple cores of the GPU, we use the CUDA programming model. In Pytorch it is much easier to run the CUDA operations. But always keep in mind that GPU won’t be a replacement for CPU for all purposes because a GPU will only work as an extra contributor to the CPU by helping in running parallel repetitive computations of a given application while the main program will be still running on the CPU. Some other application where GPU is better than CPU are :
- Rendering Videos – Due to high computational power and memory bandwidth it can efficiently render the videos.
- Cryptocurrency mining – Initially Cryptocurrency mining was done using CPUs.But due to their high power consumption and limited processing power resulted in unsatisfactory results. Currently, there are dedicated GPUs available for mining such as Nvidia GeForce RTX 2080 Ti.
Rather than sticking more to the theoretical aspects, let’s get our hands dirty by training a model using GPU on Google Colab notebook.
Training a neural network model on GPU in google Colab
Using google Colab environment, we have free access to the “NVIDIA Tesla K80” GPU. But keep in mind that you are limited to use it for 12 hours continuously, after that you may not be able to access it for a particular duration of time unless you purchase Colab pro.
We will take MNIST handwritten digit classification dataset as our problem. Our task is to train a model that can correctly classify a given image of a handwritten digit to a respective label. So some of the main steps that you have to emphasize while training the model on GPU are:
- Setting up the Runtime type.
- Defining a function to switch between GPU and CPU.
- Loading the dataset and model into your GPU.
So let’s start!
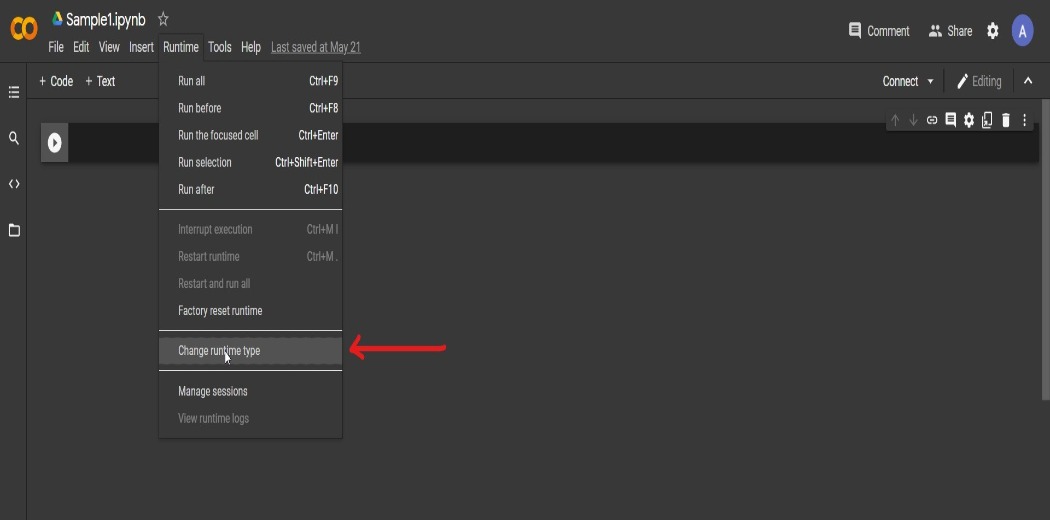
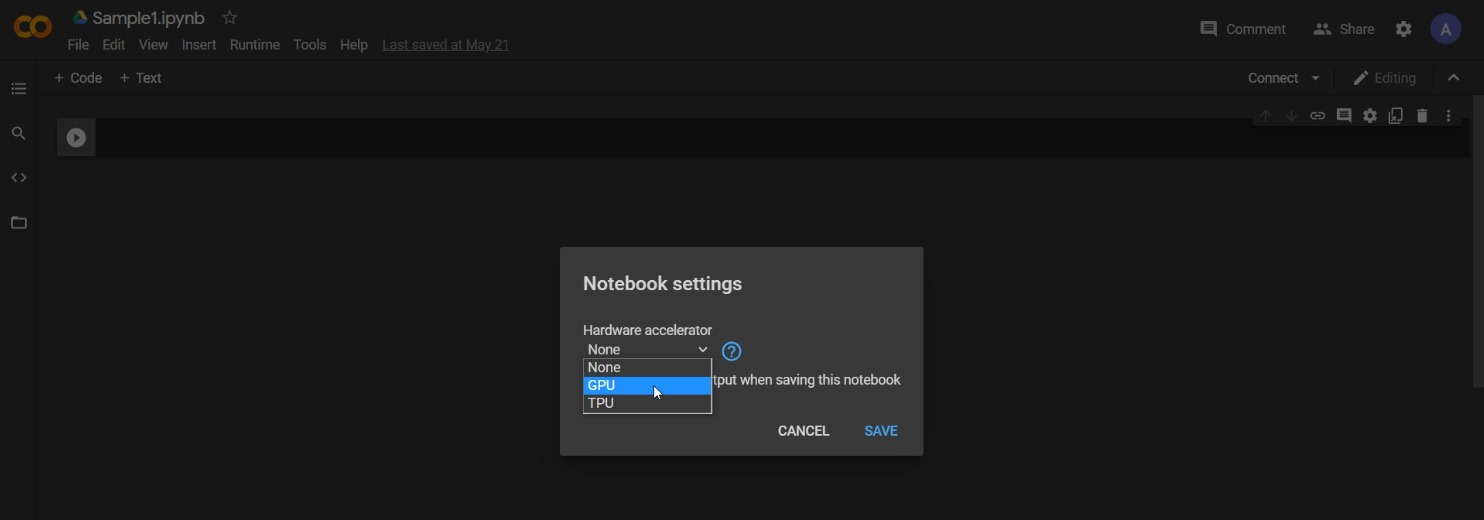
Step-1: Setting up the Google Colab notebook
After creating a new notebook first step is to set the runtime type to GPU.
Step-2: Loading the necessary libraries
import torch import torchvision import numpy as np import matplotlib import matplotlib.pyplot as plt import torch.nn as nn import torch.nn.functional as F from torchvision.datasets import MNIST from torchvision.transforms import ToTensor from torchvision.utils import make_grid from torch.utils.data.dataloader import DataLoader from torch.utils.data import random_split %matplotlib inline # Use a white background for matplotlib figures matplotlib.rcParams['figure.facecolor'] = '#ffffff'
Step-3: Creating train and validation datasets
dataset = MNIST(root='data/',download =True,transform = ToTensor())
#Splitting dataset to train and validaion val_size = 10000 train_size = len(dataset) - val_size train_set,val_set = random_split(dataset,[train_size,val_size]
Step-4: Loading train and validation datasets as batches
batch_size = 128 train_loader = DataLoader(train_set,batch_size=128,shuffle=True,num_workers=2,pin_memory =True) val_loader = DataLoader(val_set,batch_size=256,shuffle=True,num_workers=2,pin_memory=True)
When you want to push the dataset that has been loaded on the CPU to the GPU, setting pin_memory = True results in faster data transfer between the two.
Step-5:Creating the class Mnistmodel
class Mnistmodel(nn.Module):
def __init__(self,input_size,hidden_size,out_size):
super().__init__()
##hidden layer
self.linear1 = nn.Linear(input_size,hidden_size)
## Output layer
self.linear2 = nn.Linear(hidden_size,out_size)
def forward(self,xb):
xb = xb.view(xb.size(0),-1)
# Output of hidden layer
out = self.linear1(xb)
#Applying Relu activation on output of hidden layer
rel = F.relu(out)
# Final output
out = self.linear2(rel)
return out
def training_step(self,batch):
""" Returns loss for a training data"""
images,labels = batch
out = self(images)
loss = F.cross_entropy(out,labels)
return loss
def validation_step(self,batch):
"""Finding loss and accuracy for a batch of validation data"""
images,labels = batch
out = self(images)
loss = F.cross_entropy(out,labels)
acc = accuracy(out,labels)
return {'val_loss':loss,'val_acc':acc}
def validation_epoch_end(self,outputs):
batch_losses = [x['val_loss'] for x in outputs]
epoch_loss = torch.stack(batch_losses).mean()
batch_accuracy = [x['val_acc'] for x in outputs]
epoch_accuracy = torch.stack(batch_accuracy).mean()
return {'val_loss':epoch_loss,'val_acc':epoch_accuracy}
def epoch_end(self,epoch,result):
print("Epoch [{}], val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['val_loss'], result['val_acc']))
Using this class we can create the required model to be trained.
Before loading the model and data to the GPU let us check whether GPU is available or not?
torch.cuda.is_available()
If everything goes well you might be getting the output as True. But as you are not using Colab pro, sometimes GPU won’t be available to you if you had used it continuously for a certain time. So in the next step, we are creating a function to switch between GPU and CPU so that we will be automatically switched to CPU when GPU is not available.
Step-6:- Creating a helper function to switch between CPU and GPU
def get_default_device():
"""Picking GPU if available or else CPU"""
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
device = get_default_device()
Now there won’t be a problem even when GPU isn’t available as you will be automatically switched to CPU for training, but the time taken for training will be high.
Step-7:- Defining a function to move data/model to the GPU
def to_device(data, device):
"""Move tensor(s) to chosen device"""
if isinstance(data, (list,tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
Step-8:- Creating the class Devicedataloader
class DevicedataLoader():
def __init__(self,dl,device):
self.dl = dl
self.device = device
def __iter__(self):
for b in self.dl:
yield to_device(b, self.device)
def __len__(self):
return len(self.dl)
train_loader = DeviceDataLoader(train_loader,device) val_loader = DeviceDataLoader(val_loader,device)
Using the class Devicedataloader we will create objects that will help us to move the data present in the train_loader and val_loader (defined in Step 4) to the GPU.
Step-9:-Defining function to train and validate the model
def fit(epochs,lr,model,train_loader,val_loader,opt_func = torch.optim.SGD):
history = []
optimizer = opt_func(model.parameters(),lr)
for epoch in range(epochs):
#training phase
for batch in train_loader:
loss = model.training_step(batch)
loss.backward()
optimizer.step()
optimizer.zero_grad()
#Validation phase
result = evaluate(model,val_loader)
model.epoch_end(epoch,result)# Result after each epoch
history.append(result)
return history
def evaluate(model,val_loader):
outputs = [model.validation_step(batch) for batch in val_loader]
return model.validation_epoch_end(outputs)
Step-10:-Creating an instance of the class MNISTmodel and moving it to GPU
num_classes =10 model = Mnistmodel(input_size =784 ,hidden_size=32,out_size= num_classes) to_device(model,device)
Note that after creating the model, you have to move it to the GPU, or else our data which we have already moved will be in GPU while the model will be in CPU.
Step-11:- Training and validating the model
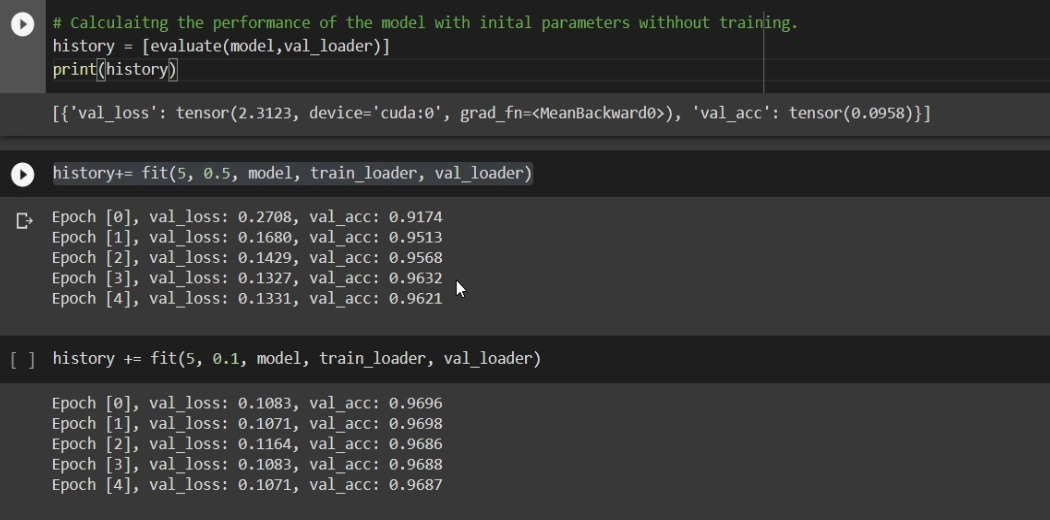
So that’s it!! You have trained your model using GPU.
Conclusion
Now I hope you might have got a better idea to train a model using GPU and the three important steps to keep in mind during the training phase while using GPU. For your extra knowledge, recently a new path-breaking algorithm called SLIDE(Sub-linear deep learning engine) was created by a group of computer scientists from Rice University. The main idea behind the algorithm is to reduce the wasteful computations done in the backpropagation. This efficient algorithm uses only the CPU to train deep learning models rather than depending upon the hardware accelerators.
End Note
For the entire code, you can refer to my GitHub repo here. You can also write your code in Kaggle notebooks and train your model using their GPUs.
References
1. Pytorch for Deep Learning Complete Tutorial.
About the Author
I am Adwait Dathan, currently pursuing my master’s in Artificial Intelligence and Data Science. Please feel free to connect with me on LinkedIn
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.