



While working late in office, something very strange happened to me. I got a message from Google that I should leave office in next 5 minutes in case I wish to catch the movie, which I booked two days back. I was surprised because I never set up any kind of reminder or alarm on this. I smiled and wrapped up my work to catch the movie. Where can Google get this information from? Obviously the confirmation mail of the E-ticket, which was lying in my Gmail account. Google has the expertise to read through every mail of yours (obviously, with all the permission given by the user himself), and drive out useful information. The way to read all the content available in form of HTML format is called web scrapping. Google has bots which scrap data and analyze to bring out useful information.
We started a challenge on very similar lines a month back. The problem can be found here. In this article, we will provide an approach to solve this problem.
Problem statement
The Analogy
Let’s take this problem to a distant past. You do not have computers or laptops. You have a number of books written by Kunal and Tavish. There are a few books without the name of the author. You need to identify the author of these books. What would have been your approach?

Following is a simple approach to solve this problem :
- First thing you will do is obviously read all the books with a known author.
- Second thing is to identify the writing style and the commonly used words by the authors.
- Third thing will be to build rules using these key words and writing style to judge the anonymous author books.
This approach obviously will take you days. Given that you do have the facility to use the super power of computers, this task becomes a cake walk. However, the approach remain same with a single difference. The work will be done by bots under your instruction instead of you doing the entire task.
A Teaser
Imagine that you have made the bots and have the most frequent words used by Tavish and Kunal. Following is the word cloud of the two authors (length of the word is proportional to the frequency of words in the documents). Identify which word cloud belongs to Tavish and which one belongs to Kunal.
 Who mentions Business and Data Analytics more in their articles?
Who mentions Business and Data Analytics more in their articles?
Whose articles are more related towards Customer analysis with Use Case studies?
The entire code has been shared on github. We will just keep bits and pieces of this code as a reference in this article.
The Framework
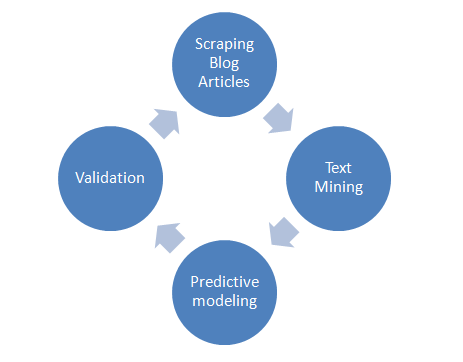
Step 1:- Scraping Blog Articles and Loading in R:
An Open Source Import.Io has been used to scrape all the desired Data from the Blog. The tool meticulously crawled the entire website and extracted the relevant information related to Author Posts, Titles, Names, Tags, Date of Publish, Comments, Number of Comments, Blog Categories etc.
Step 2:- Text Mining:
Once we have done all the necessary preparation on the generated Data set, we now need to mine the information desired and suitable to be used for prediction analysis. Following is the code used to generate a complete Data Frame with information pertaining to all the texts.
- Create a Corpus as required by TM Package
[stextbox id=”grey”]
##Corpus requires a vector source
pos.corpus.title<-Corpus(VectorSource(pos.title))
pos.corpus.text<-Corpus(VectorSource(pos.text))
pos.corpus.tags<-Corpus(VectorSource(pos.tags))
pos.corpus.comments<-Corpus(VectorSource(pos.comments))
pos.corpus.categories<-Corpus(VectorSource(pos.categories))
inspect(pos.corpus.title) ##Similarly other corpuses can be inspected
[/stextbox]
- Pre Process the Corpus as desired for further analysis
[stextbox id=”grey”]
##Removing words from Comments which have higher correlation to Output Classification
ExtraStopWords<-c(stopwords(“english”),”Kunal”,”Jain”,”Tavish”,”Srivastava”,”Tags”)
Pos.corpus.Preprocess=function(corpus)
{
corpus<-tm_map(corpus,stripWhitespace) ##Remove extra white spaces
corpus<-tm_map(corpus,removePunctuation) ## Remove Punctuations
corpus<-tm_map(corpus,removeNumbers) ## Remove Numbers
corpus<-tm_map(corpus,removeWords,ExtraStopWords) ## Remove Stop Words
corpus<-tm_map(corpus,tolower) ## Converts to Lower case
corpus<-tm_map(corpus, stemDocument, language = “english”)
return(corpus)
}
[/stextbox]
- Then, Generate a Document Term Matrix
[stextbox id=”grey”]
Pos.DTM<-function(sparseTitle,sparseText,sparseTags,sparseComments,sparseCategories)
{
pos.DTM.title<-removeSparseTerms(DocumentTermMatrix(pos.corpus.title),sparseTitle)
(pos.DTM.title)
pos.DTM.text<-removeSparseTerms(DocumentTermMatrix(pos.corpus.text),sparseText)
(pos.DTM.text)
pos.DTM.tags<-removeSparseTerms(DocumentTermMatrix(pos.corpus.tags),sparseTags)
(pos.DTM.tags)
pos.DTM.comments<-removeSparseTerms(DocumentTermMatrix(pos.corpus.comments),sparseComments)
(pos.DTM.comments)
pos.DTM.categories<-removeSparseTerms(DocumentTermMatrix(pos.corpus.categories),sparseCategories)
(pos.DTM.categories)
}
Final_DTM<-cbind(inspect(pos.DTM.title),
inspect(pos.DTM.text),
inspect(pos.DTM.tags),
inspect(pos.DTM.categories),
inspect(pos.DTM.comments))
[/stextbox]
Step 3:- Predictive modelling:
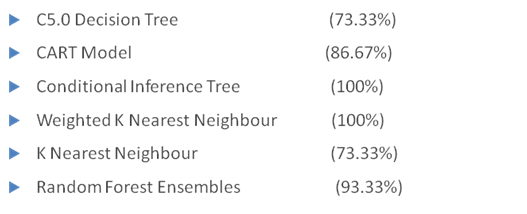
The DTM obtained is portioned into Training and Testing Datasets and are analysed using various Predictive classification models such as C5.0 (Decision Tree), CART Model, Conditional Inference Trees, Weighted K Nearest Neighbour, KNN and Random Forest Ensemble. The accuracy was measured based on the acceptance criteria mentioned in the Challenge.
The entire model code can be found in the following link.
Step 4:-Validation:
The models were validated for a higher accuracy. Suitable Document Term matrices were selected thereby improving its Sparseness and making the models more robust and generalized.
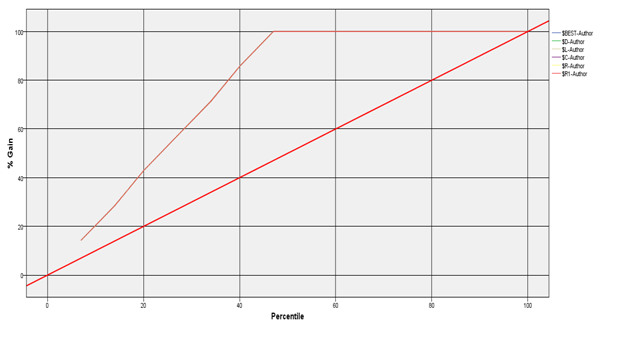
Following are the Gain Plots for the above mentioned models.
- Gain Plots considering all input Variables (100% Gain achieved for all models):-
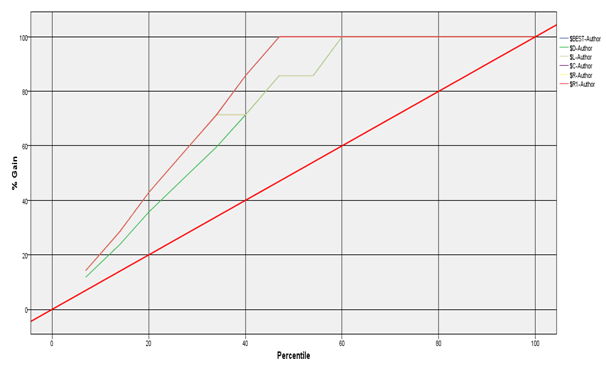
- Gains plot without considering top 2 important Influential concepts (or terms). They are Will, Can, Analytics and Data. Following is the accuracy on the Test Data set (i.e. on and after 7th July 2014)

{kind=link}
End Notes
When Kunal and I saw the word cloud for the first time, we were surprised to notice such distinct words coming out to be significant differentiators. Such insights can be leveraged to build web marketing strategy. For instance, such words which are being repeated in popular articles on Google are gold mines. These words should be repeated more often. Google has infinite number of such algorithm embedded in the search engines and mail boxes. It tries to aggregate all knowledge for each customer to bring out customer specific information.
Were you able to solve the challenge before looking at the solution? Did you figure out which word cloud corresponds to Tavish & Kunal? Did you find this exercise useful?
A significant portion of this article has been contributed by Krishna and Chandani. Krishna and Chandani are part of Analytics Vidhya Apprentice programme. Krishna is undergoing his Masters at the NUS, while Chandani works for an analytics startup in Health sector. They completed this challenge not only before the expected timelines but also took the lead to take the whole group through the learning.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.