



{kind=link}
Average is one of the biggest enemy of analysts!
Why do I say so?
The amount of reporting which happens on averages is astonishingly high. Sadly, working with averages never reveals actionable insights until broken down in segments. Let’s go through a typical example to demonstrate what I am saying:
Let us assume that you head Customer Management division of Credit cards for a bank. Two metric of immense importance to you are:
- Monthly spend people do on their credit cards – Indicates usage of credit card for customers
- How much of their credit limit are customers utilizing? – Increasing trend might mean increasing risk or higher satisfaction. Decreasing trend might mean the other way.
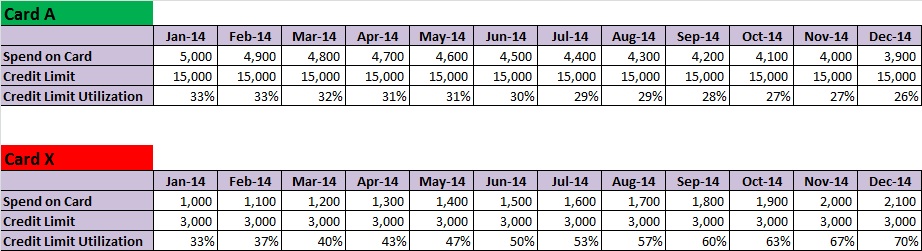
You look at the following report and feel that everything is under control. You reach a quick conclusion that there is no problem in continuing your engagement as they run today:

In a practical scenario, these metrics would be an aggregate across various cards, but for simplicity, lets say that there are 2 kinds of cards:
- Card A: Aimed towards people with good credit history. They will tend to have higher credit limits, lower risk and hence lower lending interest rates.
- Card X: Aimed towards people new to Credit or people with bad Credit history. These will have lower Credit limits, higher risk and hence higher lending interest rates.
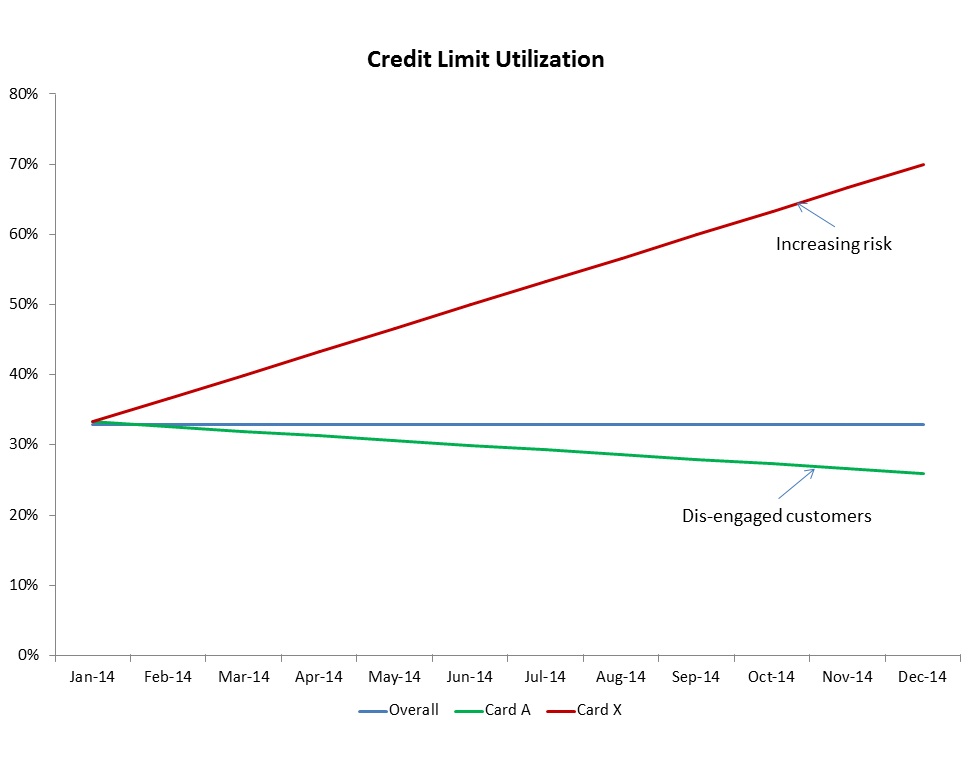
Again, just to simplify, lets assume that you have an even mix. The minute you split the metrics by segments, a different story emerges:
As you can see, what is actually happening is very different from what you would interpret from Average metrics. Actually, usage of cards with your low risk customers is on decline where as on the high risk customers is on increase – might be a scary situation!
[stextbox id=”section”]What is segmentation?[/stextbox]
Segmentation is a process of breaking a group of entities (Parent group) into multiple groups of entities (Child group) so that entities in child group have higher homogeneity with in its entities.
Following is a simple example of customer segmentation for a bank basis their age:
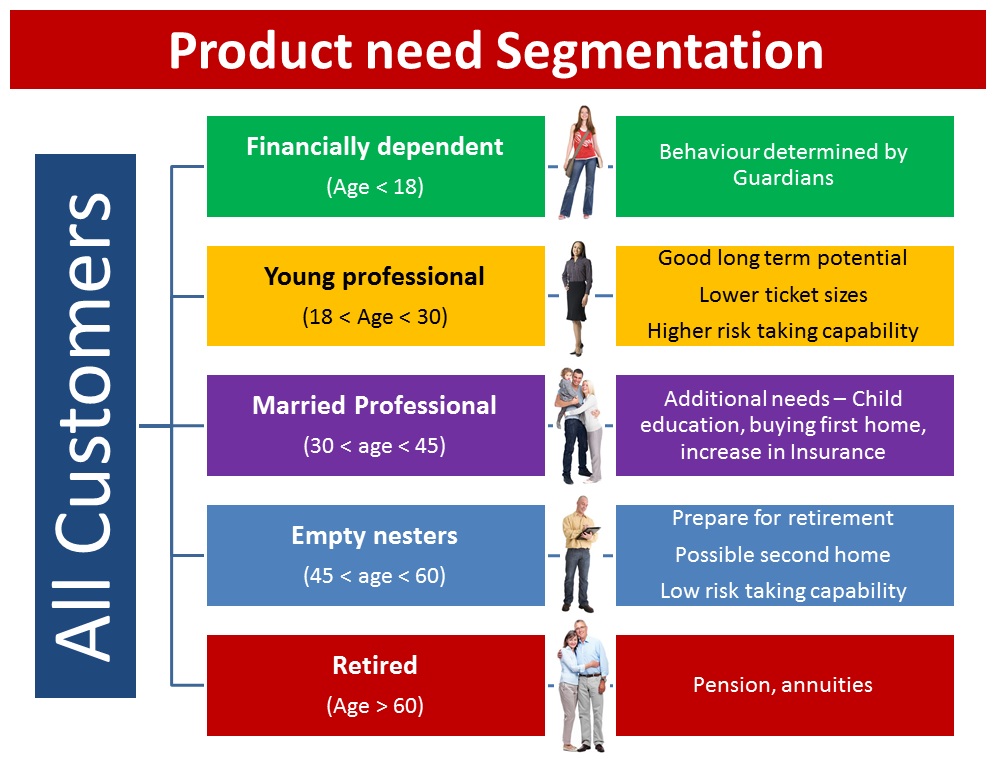
In this case you take a single group (customers of bank) and segment them in 5 child groups (basis their age). Incorporating this segmentation in your analysis can then drive various insights and ultimately actions in interest of your business like:
- Are customers buying right kind of products?
- What are the opportunities to sell an additional product to the customer? If the person became a customer as “Young Professional“, has the need changed as he is now a “Married Professional“
- What kind of marketing channels would appeal to which kind of customers? How much to spend in each channel?
General guideline to create the child groups is that they should be “Heterogeneous with other groups, but homogeneous with in group“.
[stextbox id=”section”]How to create a segmentation?[/stextbox]
While there are multiple techniques to create a segmentation, the focus of this post is not on technical knowledge. I’ll layout the process used to create a segmentation and keep the technical details for a later point. This will enable you to create and implement a segmentation, even if it is not the best technically. You can obviously learn more details about the techniques and apply them in conjunction with the process mentioned here:
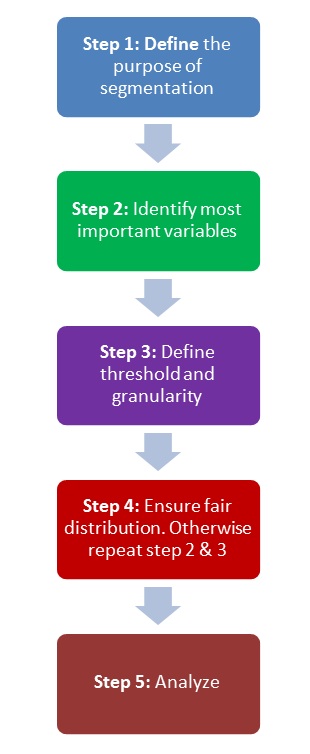
- Step 1: Define the purpose of the segmentation. How do you want to use this segmentation? Is it for new customer acquisition? Managing a portfolio of existing customers? or Reducing credit exposure to reduce charge-offs? Every segmentation is created for a purpose. Until this purpose is clear, you will not be able to create a good segmentation.
- Step 2: Identify the most critical parameters (variables) which influence the purpose of the segmentation. List them in order of their importance. Now, there are multiple statistical techniques like Clustering, Decision tree which help you do this. If you don’t know these, use your business knowledge and understanding to come out with the list. For example, if you want to create a segmentation of products and focus on products which are most profitable, most critical parameters would be Cost and Revenue. If the problem is related to identifying best talent, the variables would be skill and motivation.
- Step 3: Once these variables are identified, you need to identify the granularity and threshold for creating segments. Again, these can come from the technique developed, but business knowledge could be deployed equally well. As a general guidance, you should have 2 – 3 levels for each important variable identified. However, it depends on complexity of problem, ability of your systems and openness of your business to adapt a segmentation. Some of the simple ways to decide threshold could be:
- High / Medium / Low with numerical thresholds
- 0 / 1 for binary output
- Vintage / Age of customers
- Step 4: Assign customers to each of the cells and see if there is a fair distribution. If not, tweak the thresholds or variables. Perform step 2, 3 and 4 iteratively till you create a fair distribution.
- Step 5: Include this segmentation in your analysis and analyze at segment level (and not at macro level!)
[stextbox id=”section”]Example of creating Segmentation:[/stextbox]
Let us say that you want to create HR strategy to identify which employees should be engaged in what manner so that you are able to reduce attrition and offer what the employee actually wants.
- Define purpose – Already mentioned in the statement above
- Identify critical parameters – Some of the variables which come up in mind are skill, motivation, vintage, department, education etc. Let us say that basis past experience, we know that skill and motivation are most important parameters. Also, for sake of simplicity we just select 2 variables. Taking additional variables will increase the complexity, but can be done if it adds value.
- Granularity – Let us say we are able to classify both skill and motivation into High and Low using various techniques. This creates a simple segmentation as mentioned below:
- If the distribution is skewed highly in one of the segments, we can change the threshold to define High and Low and re-create the segmentation.
- Finally, you can now start analyzing employees to answer following questions:
- Which kind of employees are having highest attrition? Is this HL / LH / LL or HH?
- What is the average life span for each of these categories?
- How many training each of these segments get in a year?
- How many HH employees have been recognized for their work and contribution? What can be changed?
Hope this gives you a fair idea about creating and implementing a segmentation.
[stextbox id=”section”]A few additional notes:[/stextbox]
Before closing the article, would like to mention a few additional points to keep in mind:
- Try and keep a fair volume distribution in various segments. If this does not happen, then you will end up analyzing on this data, which can result in wrong inferences.
- Segmentation is always done as a means to achieve something. It can not be an objective in itself. So before starting any segmentation, always ask are you clear about the objective.
- Techniques of segmentation help, but you can achieve more than 70% of results with a good business understanding.
So next time if you see any reporting happening at an overall level, STOP. STOP and think what you might be looking over and how can you improve this to bring out more actionable insights.
If you like what you just read & want to continue your analytics learning, subscribe to our emails or like our facebook page
Kunal is a post graduate from IIT Bombay in Aerospace Engineering. He has spent more than 10 years in field of Data Science. His work experience ranges from mature markets like UK to a developing market like India. During this period he has lead teams of various sizes and has worked on various tools like SAS, SPSS, Qlikview, R, Python and Matlab.