



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Testing forms an integral part of any software development project. Testing helps in ensuring that the final product is by and large, free of defects and it meets the desired requirements. Proper testing in the development phase helps in identifying the critical errors in the design and implementation of various functionalities thereby ensuring product reliability. Even though it is a bit time-consuming and a costly process at first, it helps in the long run of software development.
Although machine learning systems are not traditional software systems, not testing them properly for their intended purposes can lead to a huge impact in the real world. This is because machine learning systems reflect the biases of the real world. Not accounting or testing for them will inevitably have lasting and sometimes irreversible impacts. Some of the examples for such fails include Amazon’s recruitment tool which did not evaluate people in a gender-neutral way and Microsoft’s chatbot Tay which responded with offensive and derogatory remarks.
In this article, we will understand how testing machine learning systems is different from testing the traditional software systems, the difference between model testing and model evaluation, types of tests for Machine Learning systems followed by a hands-on example of writing test cases for “insurance charge prediction”.
Testing Traditional Software Systems v/s Machine Learning Systems
In traditional software systems, code is written for having a desired behavior as the outcome. Testing them involves testing the logic behind the actual behavior and how it compares with the expected behavior.
In machine learning systems, however, data and desired behavior are the inputs and the models learn the logic as the outcome of the training and optimization processes. In this case, testing involves validating the consistency of the model’s logic and our desired behavior.
Due to the process of models learning the logic, there are some notable obstacles in the way of testing Machine Learning systems. They are:
- Indeterminate outcomes: on retraining, it’s highly possible that the model parameters vary significantly
- Generalization: it’s a huge task for Machine Learning models to predict sensible outcomes for data not encountered in their training
- Coverage: there is no set method of determining test coverage for a Machine Learning model
- Interpretability: most ML models are black boxes and don’t have a comprehensible logic for a certain decision made during prediction
These issues lead to a lower understanding of the scenarios in which models fail and the reason for that behavior; not to mention, making it more difficult for developers to improve their behaviors.
Difference between Model Testing and Model Evaluation
From the discussion above, it may feel as if model testing is the same as model evaluation but that’s not true. Model evaluations focus on the performance metrics of the models like accuracy, precision, the area under the curve, f1 score, log loss, etc. These metrics are calculated on the validation dataset and remain confined to that. Though the evaluation metrics are necessary for assessing a model, they are not sufficient because they don’t shed light on the specific behaviors of the model.
It is fully possible that a model’s evaluation metrics have improved but its behavior on a core functionality has regressed. Or retraining a model on new data might introduce a bias for marginalized sections of society all the while showing no particular difference in the metrics values. This is extra harmful in the case of ML systems since such problems might not come to light easily but can have devastating impacts.
In summary, model evaluation helps in covering the performance on validation datasets while model testing helps in explicitly validating the nuanced behaviors of our models. During the development of ML models, it is better to have both model testing and evaluation to be executed in parallel.
Writing Test Cases
We usually write two different classes of tests for Machine Learning systems:
- Pre-train tests
- Post-train tests
Pre-train tests: The intention is to write such tests which can be run without trained parameters so that we can catch implementation errors early on. This helps in avoiding the extra time and effort spent in a wasted training job.
We can test the following in the pre-train test:
- the model predicted output shape is proper or not
- test dataset leakage i.e. checking whether the data in training and testing datasets have no duplication
- temporal data leakage which involves checking whether the dependencies between training and test data do not lead to unrealistic situations in the time domain like training on a future data point and testing on a past data point
- check for the output ranges. In the cases where we are predicting outputs in a certain range (for example when predicting probabilities), we need to ensure the final prediction is not outside the expected range of values.
- Ensuring a gradient step training on a batch of data leads to a decrease in the loss
- data profiling assertions
Post-train tests: Post-train tests are aimed at testing the model’s behavior. We want to test the learned logic and it could be tested on the following points and more:
- invariance tests which involve testing the model by tweaking only one feature in a data point and checking for consistency in model predictions. For example, if we are working with a loan prediction dataset then change in sex should not affect an individual’s eligibility for the loan given all other features are the same or in the case of titanic survivor probability prediction data, change in the passenger’s name should not affect their chances of survival.
- Directional expectations wherein we test for a direct relation between feature values and predictions. For example, in the case of a loan prediction problem, having a higher credit score should definitely increase a person’s eligibility for a loan.
- Apart from this, you can also write tests for any other failure modes identified for your model.
Now, let’s try a hands-on approach and write tests for the Medical Cost Personal Datasets. Here, we are given a bunch of features and we have to predict the insurance costs
Machine Learning – Hands-on Approach
You can find the whole code here.
Let’s see the features first. The following columns are provided in the dataset:
-
- Age
- Sex (categorical feature)
- BMI
- Number of children
- Smoker (categorical feature)
- Region (categorical feature)
- Charges
Doing a little bit of analysis on the dataset will reveal the relationship between various features. Since the main aim of this article is to learn how to write tests, we will skip the analysis part and directly write basic tests.
Refer to the various notebooks here for a detailed analysis of the data.
We will start with pre-processing the data. But before that, let’s set up some helper functions in the “util” package of the project.
Helper Functions
Functions for loading data:
def load_data_from_path(filepath):
df = pd.read_csv(filepath)
return df
def load_insurance_data():
input_path = "data/raw/insurance.csv"
df = load_data_from_path(input_path)
return df
def load_processed_insurance_data():
input_path = "data/processed/processed_insurance_data.csv"
df = load_data_from_path(input_path)
return df
As is evident from the code itself,
- load_data_from_path() function will load data from a given file path and return the data frame
- load_insurance_data() function will load the data we have downloaded from Kaggle and return a data frame
- load_processed_insurance_data() function will load the processed dataset from the hardcoded path
As is evident from the code itself,
- load_data_from_path() function will load data from a given file path and return the data frame
- load_insurance_data() function will load the data we have downloaded from Kaggle and return a data frame
- load_processed_insurance_data() function will load the processed dataset from the hardcoded path
Function for splitting training and testing data:
def split_train_test_data():
df = load_processed_insurance_data()
X = df.drop(columns=["charges"])
# In the above line, the column sex is also dropped but let's see what's the effect of keeping sex on the
# invariance test
y = df["charges"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
save_train_test_data(X_train, y_train, X_test, y_test)
return X_train, y_train, X_test, y_test
The above function will load the processed insurance data first. Then it will remove the column to be predicted from it (X) and create a separate data frame with output charge values (y). Next, it will split the X and y data frames so formed into training and testing datasets and return those to the caller.
Functions for saving the dataset:
def save_insurance_data(df: pd.DataFrame):
output_path = "data/processed/processed_insurance_data.csv"
df.to_csv(output_path, index=False)
return
The above function will save the processed data to the folder named “processed” under the data folder for further use.
def save_train_test_data(Xtrain: pd.DataFrame, Ytrain: pd.DataFrame, Xtest: pd.DataFrame, Ytest: pd.DataFrame):
Xtrain.to_csv("data/model_training_data/training_data.csv", index=False)
Ytrain.to_csv("data/model_training_data/training_data_result.csv", index=False)
Xtest.to_csv("data/model_testing_data/testing_data.csv", index=False)
Ytest.to_csv("data/model_testing_data/testing_data_result.csv", index=False)
return
The above function will save the previously split training and testing data to their designated locations.
Next, let’s write the script for pre-processing the data.
Data Pre-Processing Script
In data pre-processing, we will load the insurance data using the function load_insurance_data() as discussed before. We will introduce two new columns in the dataset:
- age_range: this column will categorize each row into an age range. The categorization is as follows: all data points with
- age value less than 30 will have value for age_range as 1;
- age value less than 40 but greater than or equal to 30 will have value for age_range as 2
- age value less than 50 but greater than or equal to 40 will have value for age_range as 3
- age value greater than 50 will have value for age_range as 4
- have_children: this column will have value as “Yes” for all rows with values for children feature as greater than 0 and “No” value for the rest
def data_preprocessing():
""" Runs data processing scripts to turn raw data from (../raw) into
cleaned data ready to be analyzed (saved in ../processed).
"""
logger = logging.getLogger(__name__)
logger.info('making final data set from raw data')
# df = pd.DataFrame()
df = load_insurance_data()
# creating new feature by using age column
df["age_range"] = 1000
for i in range(len(df["age"])):
if df["age"][i] < 30:
df["age_range"][i] = 1
elif 30 <= df["age"][i] < 40:
df["age_range"][i] = 2
elif 40 <= df["age"][i] < 50:
df["age_range"][i] = 3
elif df["age_range"][i] >= 50:
df["age_range"][i] = 4
df["have_children"] = ["No" if i == 0 else "Yes" for i in df["children"]]
cat_variable = [‘sex’, ‘smoker’, ‘region’, ‘have_children’]
lb = LabelEncoder()
df[cat_variable] = df[cat_variable].apply(lambda col: lb.fit_transform(col.astype(str)))
save_insurance_data(df)
return
After introducing two new columns in the dataset, we will encode the columns with categorical values using sklearn’s LabelEncoder. A label encoder transforms the labels of a categorical column into numeric form for efficient processing by the machine learning algorithms.
After the column transformation, we save the processed dataset using the save_insurance_data() discussed before.
Next, we will write train_model.py and predict_model.py scripts.
Training and Prediction Scripts
For training, we will consider only two models: Linear Regression and K Nearest Neighbors.
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
def linear_regression(xtrain, ytrain):
lr = LinearRegression()
lr.fit(xtrain, ytrain)
return lr
def k_neighbours(xtrain, ytrain):
knn = KNeighborsRegressor()
knn.fit(xtrain, ytrain)
return knn
As is known from the code above, linear_regression function will initiate the LinearRegression() from the sklearn package and train it on the given training data. k_neighbours() function behaves similarly.
Let’s look at the prediction script now:
import pandas as pd
def predict_on_test_data(model, xtest):
y_test = model.predict(xtest)
filename = str(model.__class__.__name__)+"predicted output.csv"
prediction = pd.DataFrame(y_test)
pd.DataFrame(y_test).to_csv("data/model_testing_data/"+filename)
return prediction
predict_on_test_data() function will simply take the model passed into it and predict the values for the test data passed as a second argument. Then it will save the resulting predictions into the appropriate folders and return the prediction data frame.
Let’s write the pre-train and post-train test scripts now.
Pre-train and Post-train Test Scripts
Before writing the tests, let us write fixtures. We will write fixtures using the decorator @pytest.fixtures. Fixtures are designed to run before each of the test functions that it is applied to. They provide important context to the tests. Refer to this link for more information on pytest fixtures
@pytest.fixture
def data_preparation():
data_preprocessing()
return split_train_test_data()
@pytest.fixture
def linear_regression_prediction(data_preparation):
xtrain, ytrain, xtest, ytest = data_preparation
lr = linear_regression(xtrain, ytrain)
ypred = predict_on_test_data(lr, xtest)
return xtest, ypred
@pytest.fixture
def k_neighbors_prediction(data_preparation):
xtrain, ytrain, xtest, ytest = data_preparation
knn = k_neighbours(xtrain, ytrain)
ypred = predict_on_test_data(knn, xtest)
return xtest, ypred
@pytest.fixture
def return_models(data_preparation):
xtrain, ytrain, xtest, ytest = data_preparation
lr = linear_regression(xtrain, ytrain)
knn = k_neighbours(xtrain, ytrain)
return [lr, knn]
We’ve designed 4 fixtures:
- data_preparation(): this fixture will call the data_preprocessing() function defined before to pre-process the raw data. Next, it will call the split_train_test_data() function to split the data and pass it to the caller
- linear_regression_prediction(): this fixture will take data_preparation() fixture values as it’s input. It will train the linear_regression model on the training data passed by the data_preparation fixture followed by calling predict_on_test_data() to predict the values based on the trained model and will finally return the test data and predicted values
- k_neighbors_prediction(): this fixture will work in the same way as the previous fixture except that it will train the model using the K Nearest Neighbors algorithm
- return_models(): this fixture will take data-preparation as its input and return the trained linear regression and k nearest neighbor models on the training data.
Machine Learning Pre-train Test Script
We will check for two things in this example – test data leakage and predicted output shape validation. The script is as follows:
import pytest_check as check
def test_data_leak(data_preparation):
xtrain, ytrain, xtest, ytest = data_preparation
concat_df = pd.concat([xtrain, xtest])
concat_df.drop_duplicates(inplace=True)
assert concat_df.shape[0] == xtrain.shape[0] + xtest.shape[0]
def test_predicted_output_shape(linear_regression_prediction, k_neighbors_prediction):
print("Linear regression")
xtest, ypred = linear_regression_prediction
check.equal(ypred.shape, (xtest.shape[0], ))
# assert ypred.shape == (xtest.shape[0], 1)
print("K nearest neighbours")
xtest, ypred = k_neighbors_prediction
check.equal(ypred.shape, (xtest.shape[0], ))
# assert ypred.shape == (xtest.shape[0], )
In the test_data_leak() function, we take the data_preparation() fixture as the input which will provide us with the dataset. Next, we will concatenate the training and test data and drop the duplicates from it. Now, we’ll check whether the size of the concatenated datasets without duplicates is the same as the addition of shapes of training and testing data.
In the test_predicted_output_shape() function, we take the linear_regression_prediction() and k_neighbors_prediction() fixtures discussed before as the input. Next, we obtain their prediction values and compare their shape with that of the testing dataset. Here, for illustration purposes, the wrong comparison is done. The actual shape comparison should be (xtest.shape[0], 1).
Also note that, instead of assert, we have pytest_check. It acts as a soft assert meaning that even if an assertion fails in between, the test will not stop there but instead proceed till completion and report all the assertion fails.
The result of running the above pre-train tests is as shown below:
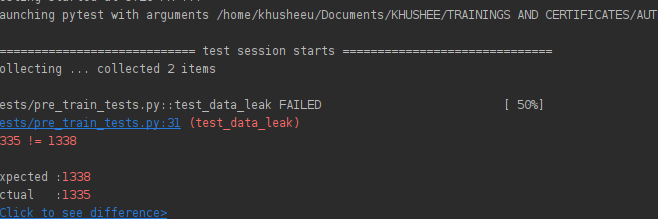
- Result of test_predicted_output_shape. Image by author
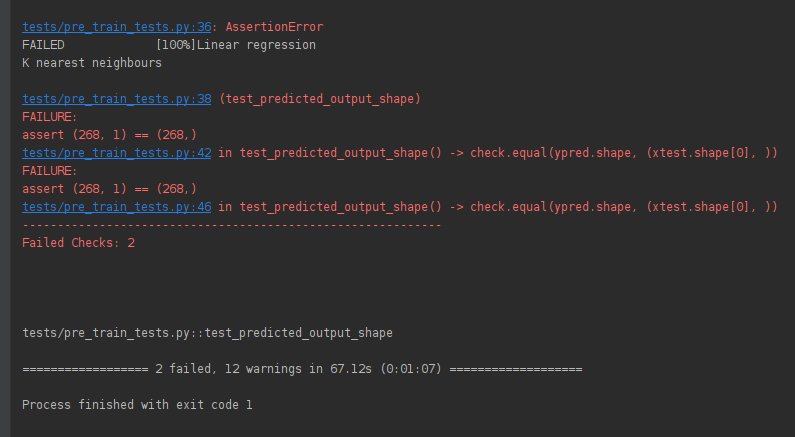
Result of test_predicted_output_shape. Image by author
Machine Learning Post-train test script
We will check for sex feature invariance in the post-train test script. Ideally, the charges should not vary according to the gender of the individual applying for insurance. But since we did not drop that column from the table, it will inevitably affect the model’s learned logic. Let’s test for it by writing this test script.
def test_sex_invariance(return_models):
models = return_models
for model in models:
print("Checking for " + str(model.__class__.__name__))
female_sample = [19, 1, 27.9, 0, 1, 2, 1, 1]
male_sample = [19, 0, 27.9, 0, 1, 2, 1, 1]
result_female_sample = model.predict(np.array(female_sample).reshape(1, -1))
result_male_sample = model.predict(np.array(male_sample).reshape(1, -1))
check.equal(result_female_sample, result_male_sample)
# assert result_female_sample == result_male_sample
The above test script will take the return_models() fixture defined before. For each model, we define two data points one with sex as “female” and the other with sex as “male” with all other values being equal. Now, we predict the charges using the model and check whether the charges are equal or not.
Below is the result of running this script.
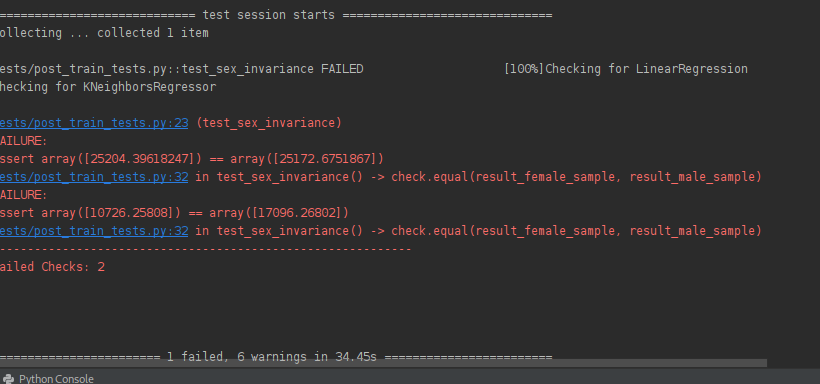
Result of test_sex_invariance. Image by author
Conclusion
In this article, we understood the importance of testing for Machine Learning Models, their difference from model evaluation, and practices a hands-on example for writing the test cases.
Read more articles on Machine Learning here!