



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
The machine learning process involves various stages such as,
- Data Preparation Stage
- Understanding the data
- Handling the missing values
- Handling categorical variables
- Standardizing the data
- Handling class imbalance
- Modeling Stage
- Splitting or cross-validating the dataset
- Choosing the appropriate machine learning algorithm
- Examine the base-line performance of the chosen algorithm
- Fine-tune the model
- Prediction Stage
- Predict on the standout test data
- check for under/overfitting
The above list is obviously not exhaustive & it might be just overwhelming to carry out all the above steps for each & every data set (barring the AutoML!). It is said that 80% of the time in machine learning is spent on data collection, cleaning & pre-processing & 20% of the time is spent on running the model.
The Preprocessing chunk!
When I started learning Python & data science, like every data science aspirant, I want to try out the machine learning models. Quickly I started working on the various datasets. It was very nice participating in hackathons & learned the practical application of machine learning.
But when I wanted to explore more on the modeling part on various types of datasets & on various models, I felt carrying out the pre-processing steps on various datasets and running various baseline model is time-consuming & less time spent on exploring modeling techniques, whereas I wanted to spend quality time on modeling tasks.
Of course in this era of exploding automl, the complete machine learning task can be done by automl. But it gives a special kind of feel building the complete machine learning model!
Also when running any of the automl, it returns various models & top-performing model’s predictions, but I wasn’t able to extract the cleaned datasets from such automl to further run some deep learning models. I had to pre-process the data manually & run the deep learning models & such deep learning model outputs may not be comparable to automl as the data has been pre-processed separately (unless the exact automl pre-processing steps have been replicated)
Here comes the idea of a package/library…
Pywedge
Pywedge is a pip installable python package that intends to,
-
Quickly preprocess the data by taking the user’s preferred choice of pre-processing techniques & it returns the cleaned datasets to the user in the first step.
-
In the second step, Pywedge offers a baseline class that has a classification summary method & regression summary method, which can return ten various baseline models, which can point the user to explore the best performing baseline model.
The intention of pywedge is to help the user by quickly preprocessing the data and to rightly point out the best performing baseline model for the given dataset so that the user can spend quality time tuning such a model algorithm.
Without wasting much more of your valuable time, let me dive into pywedge experiments.
Classification using pywedge
Let’s take cross-sell classification dataset from the Analytics Vidya hackathon for the below example-
!pip install pywedge
import pywedge as pw
import pandas as pd
train = pd.read_csv('https://raw.githubusercontent.com/taknev83/datasets/master/train_crosssell_classification.csv')
test = pd.read_csv('https://raw.githubusercontent.com/taknev83/datasets/master/test_crosssell_classification.csv')
sample_submission = pd.read_csv('https://raw.githubusercontent.com/taknev83/datasets/master/sample_submission_crosssell_classification.csv')
train.info()

This dataset contains approx 380k line items, with a mix of numerical & categorical columns.
Instantiate the Pre_process_data class as below,
ppd = pw.Pre_process_data(train, test, c='id', y='Response')
Pre_process_data class takes the following arguments,
- train = train dataframe
- test = stand out test dataframe (without target column)
- c = any redundant column to be removed (like ID column etc., at present supports a single column removal, the subsequent version will provision multiple column removal requirements)
- y = target column name as a string
- type = Classification / Regression
Run the dataframe_clean method under Pre_process_data class as below,
new_X, new_y, new_test = ppd.dataframe_clean()
The dataframe_clean method interactively asks the user to select the preprocessing choice as below,
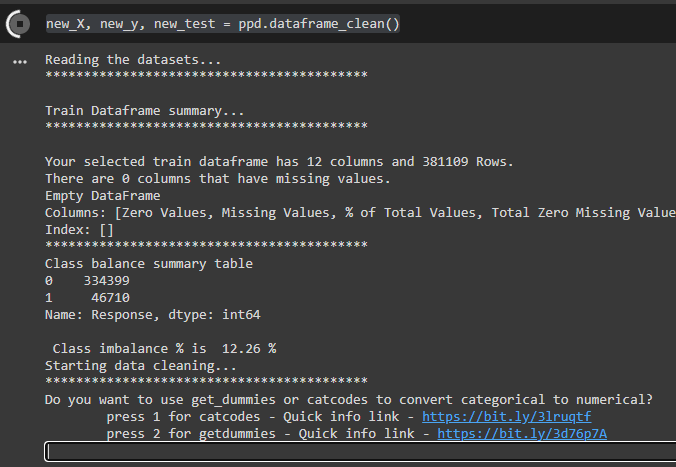
The existing class balance summary table is provided for user info, here we can see the class is imbalanced, we will select oversample in the next few steps,
The user is asked to select cathodes or getdummies to convert categorical variables, let’s select getdummies

In the next step, it asks for which standardization method to be used, let’s select Standardscalar

In the next step, it asks if we want to apply SMOTE to oversample, let’s select yes.
Once smote is completed, dataframe_clean method returns new_X, new_y & new_test.
Assign the new_X, new_y & new_test to new variables X, y & so_test for future use.
X = new_X y = new_y so_test = new_test
Instantiate the baseline class as below,
blm = pw.baseline_model(X,y)
Call the classification_summary method from baseline_model class as below,
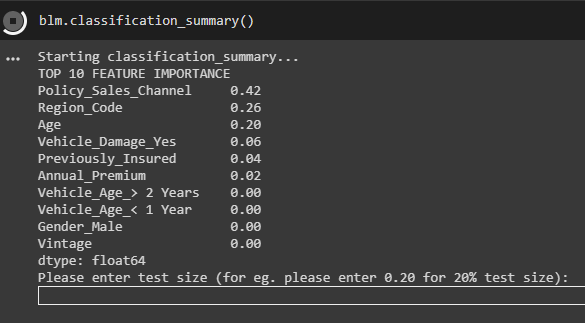
blm.classification_summary()
The classification summary provides Top 10 feature importance (calculated using Adaboost feature importance).
The classification summary asks for the test size from the user, let’s take 20% as test size,
Next comes the cool part, the summary of baseline models,

For this baseline model summary, it’s observed that the catboost classifier performs well & the user can explore tuning the hyperparameters of catboost classifier to achieve further refined results. This hyperparameter tuning user can do separately with the cleaned dataset received from pywedge.
One quick interesting point here is, if we run the same classification_summary method without oversampling, take a look at the below baseline model results

The accuracy seems to be above 80%, but observe the roc_score, all the scores are around 50%, which shows the quick importance of oversampling in class-imbalanced datasets.
Whoa! you all the way read through this, many thanks.
In the same way, regression analysis can be done using a few lines of code, let me not clutter this blog with more examples.
The code examples are available in my GitHub repo.
Pywedge is in BETA version & the following additions are planned,
-
To handle NLP column
-
To handle time series dataset
-
To handle stock prices specific analysis
-
A separate method to produce good charts
Please feel free to pip install pywedge & use & share your valuable feedback, it will motivate me to fine-tune the pywedge. Thanks for reading 🙂