



{kind=link}
This article was published as a part of the Data Science Blogathon.
What is Machine Learning?
Machine Learning: Machine Learning (ML) is a highly iterative process and ML models are learned from past experiences and also to analyze the historical data. On top, ML models are able to identify the patterns in order to make predictions about the future of the given dataset.

Why is Machine Learning Important?
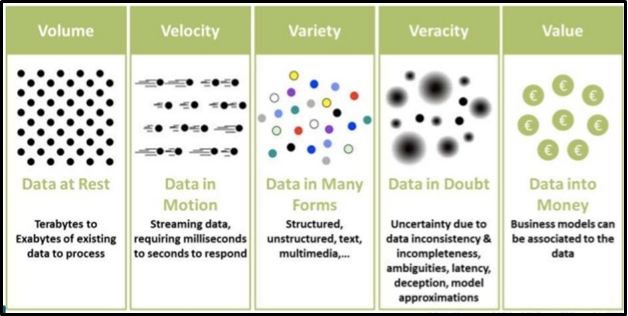
Since 5V’s are dominating the current digital world (Volume, Variety, Variation Visibility, and Value), so most of the industries are developing various models for analyzing their presence and opportunities in the market, based on this outcome they are delivering the best products, services to their customers on vast scales.
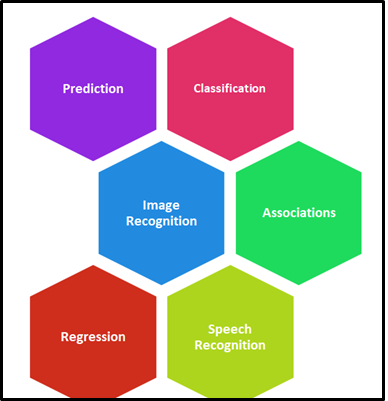
What are the major Machine Learning applications?
Machine learning (ML) is widely applicable in many industries and its processes implementation and improvements. Currently, ML has been used in multiple fields and industries with no boundaries. The figure below represents the area where ML is playing a vital role.
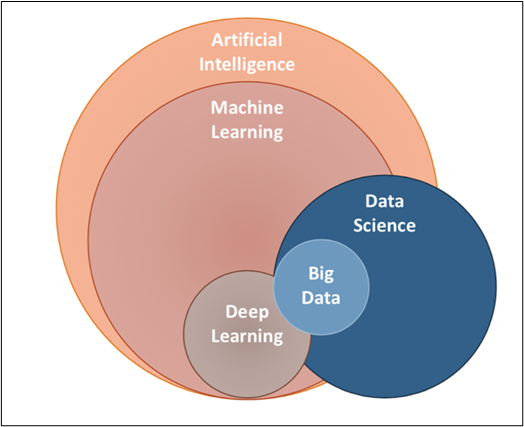
Where is Machine Learning in the AI space?
Just have a look at the Venn Diagram, we could understand where the ML in the AI space and how it is related to other AI components.
As we know the Jargons flying around us, let’s quickly look at what exactly each component talks about.
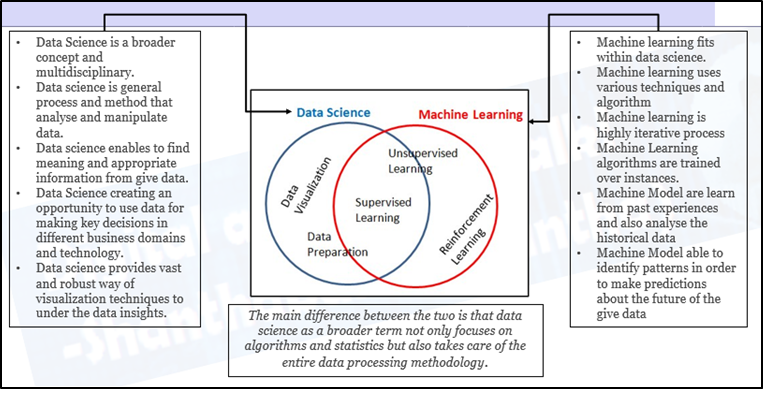
How Data Science and ML are related?
Machine Learning Process, is the first step in ML process to take the data from multiple sources and followed by a fine-tuned process of data, this data would be the feed for ML algorithms based on the problem statement, like predictive, classification and other models which are available in the space of ML world. Let us discuss each process one by one here.
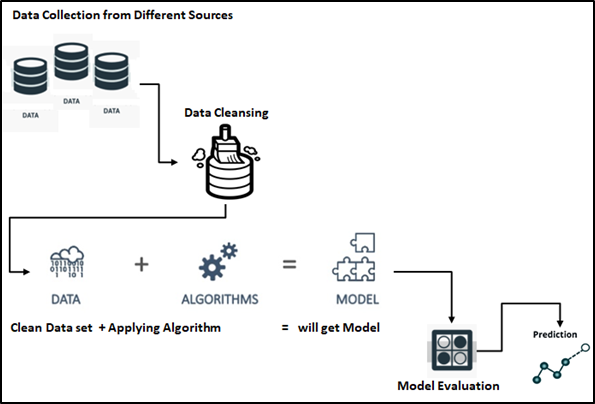
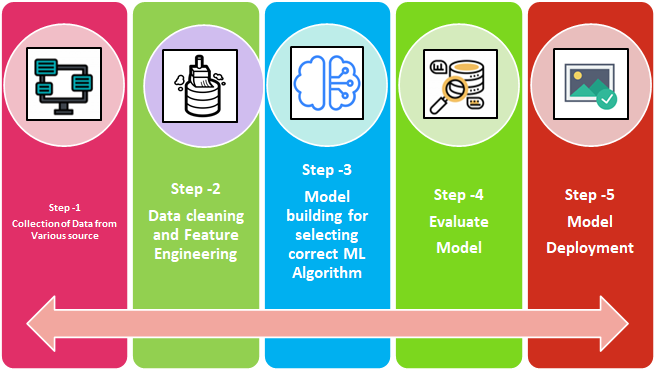
Machine Learning – Stages: We can split ML process stages into 5 as below mentioned in the flow diagram.
- Collection of Data
- Data Wrangling
- Model Building
- Model Evaluation
- Model Deployment
Identifying the Business Problems, before we go to the above stages. So, we must be clear about the objective of the purpose of ML implementation. To find the solution for the given/identified problem. we must collect the data and follow up the below stages appropriately.
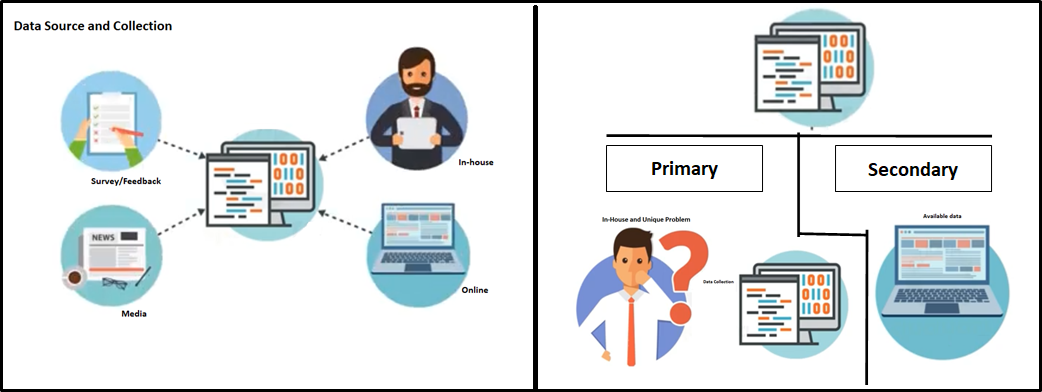
Collection of Data
Data collection from different sources could be internal and/or external to satisfy the business requirements/problems. Data could be in any format. CSV, XML.JSON, etc., here Big Data is playing a vital role to make sure the right data is in the expected format and structure.
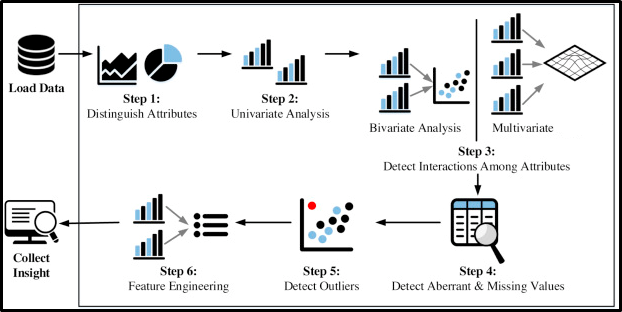
Data Wrangling and Data Processing: The main objective of this stage and focus are as below.
Data Processing (EDA):
- Understanding the given dataset and helping clean up the given dataset.
- It gives you a better understanding of the features and the relationships between them
- Extracting essential variables and leaving behind/removing non-essential variables.
- Handling Missing values or human error.
- Identifying outliers.
- The EDA process would be maximizing insights of a dataset.
Feature engineering:
- Handling missing values in the variables
- Convert categorical into numerical since most algorithms need numerical features.
- Need to correct not Gaussian(normal). linear models assume the variables have Gaussian distribution.
- Finding Outliers are present in the data, so we either truncate the data above a threshold or transform the data using log transformation.
- Scale the features. This is required to give equal importance to all the features, and not more to the one whose value is larger.
- Feature engineering is an expensive and time-consuming process.
- Feature engineering can be a manual process, it can be automated
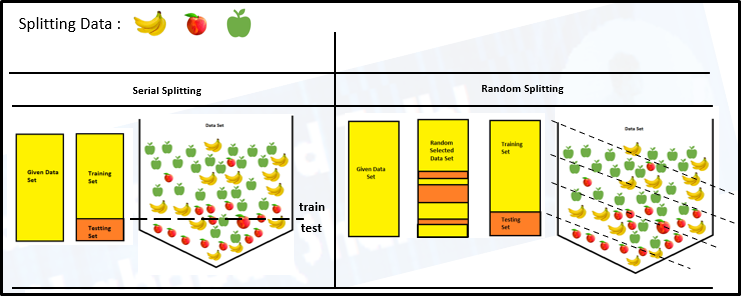
Training and Testing:
- The training data is used to make sure the machine recognizes patterns of the data, cross-validation of data is used to ensure better accuracy and
the efficiency of the algorithm which is used to train the machine. - Test data is used to see how well the machine can predict new answers based on its training.
- The train-test split procedure is used to estimate the ML performance of algorithms when they are used to make predictions on data that is not
used to train the model.
Training
- Training data is the data set on which you train the model.
- Train data from which the model has learned the experiences.
- Training sets are used to fit and tune your models.
Testing
- Test data is the data which is used to check if the model has
learnt good enough from the experiences it got in the train data set. - Test sets
are “unseen” data to evaluate your models.
Train data: It trains our machine learning algorithm
Test data: After the training the model, test data is used to test its efficiency and performance of the model
The purpose of the random state in train test split: Random state ensures that the splits that you generate are reproducible. The random state that you provide is used as a seed to the random number generator. This ensures that the random numbers are generated in the same order.
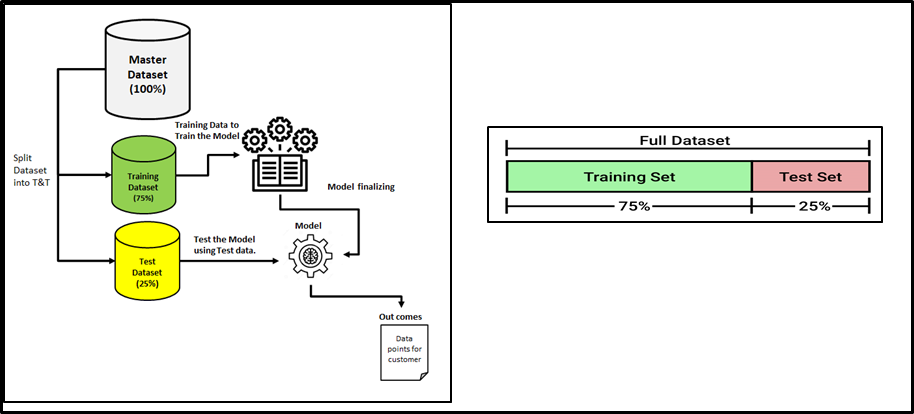
Data Split into Training/Testing Set
- We used to split a dataset into training data and test data in the machine learning space.
- The split range is usually 20%-80% between testing and training stages from the given data set.
- A major amount of data would be spent on to train your model
- The rest of the amount can be spent to evaluate your test model.
- But you cannot mix/reuse the same data for both Train and Test purposes
- If you evaluate your model on the same data you used to train it, your model could be very overfitted. Then there is a question of whether models can predict new data.
- Therefore, you should have separate training and test subsets of your dataset.
MODEL EVALUATION: Each model has its own model evaluation mythology, some of the best evaluations are here.
- Evaluating the Regression Model.
- Sum of Squared Error (SSE)
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- Mean Absolute Error (MAE)
- Coefficient of Determination (R2)
- Adjusted R2
- Evaluating Classification Model.
- Confusion Matrix.
- Accuracy Score.
- AUC and ROC.|
Deployment of an ML-model simply means the integration of the finalized model into a production environment and getting results to make business decisions.
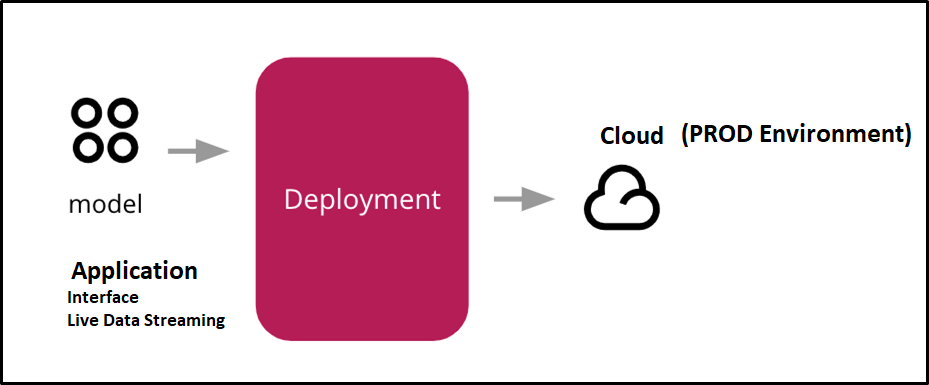
So, Hope you are able to understand the Machine Learning end-to-end process flow and I believe it would be useful for you, Thanks for your time.