



{kind=link}
In the model-building phase of any supervised machine learning project, we train a model with the aim to learn the optimal values for all the weights and biases from labeled examples. If we use the same labeled examples for testing our model then it would be a methodological mistake because a model that would just repeat the labels of the samples that it has just seen would have a perfect score but would fail to predict anything useful on yet-unseen data. This situation is called overfitting. To overcome the problem of overfitting we use cross-validation. So you must what is cross-validation ? and how can it solve the problem of overfitting?
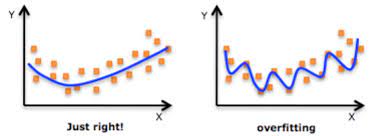
Source:https://www.datarobot.com/wiki/overfitting/
What is Cross-validation?
Cross-validation is a statistical method used to estimate the performance of machine learning models. It is a method for assessing how the results of a statistical analysis will generalize to an independent data set.
How does it tackle the problem of overfitting?
In Cross-Validation, we use our initial training data to generate multiple mini train-test splits. Use these splits to tune your model. For example in standard k-fold cross-validation, we partition the data into k subsets. Then, we iteratively train the algorithm on k-1 subsets while using the remaining subset as the test set. In this way, we can test our model on completely unseen data. In this article, you can read about the 7 most commonly used cross-validation techniques along with their pros and cons. I have also provided the code snippets for each technique.
The techniques are listed below:
1. Hold Out Cross-validation
2. K-Fold cross-validation
3. Stratified K-Fold cross-validation
4. Leave Pout Cross-validation
5. Leave One Out Cross-validation
6. Monte Carlo (Shuffle-Split)
7. Time Series ( Rolling cross-validation)
1.HoldOut Cross-validation or Train-Test Split
In this technique of cross-validation, the whole dataset is randomly partitioned into a training set and validation set. Using a rule of thumb nearly 70% of the whole dataset is used as a training set and the remaining 30% is used as the validation set.
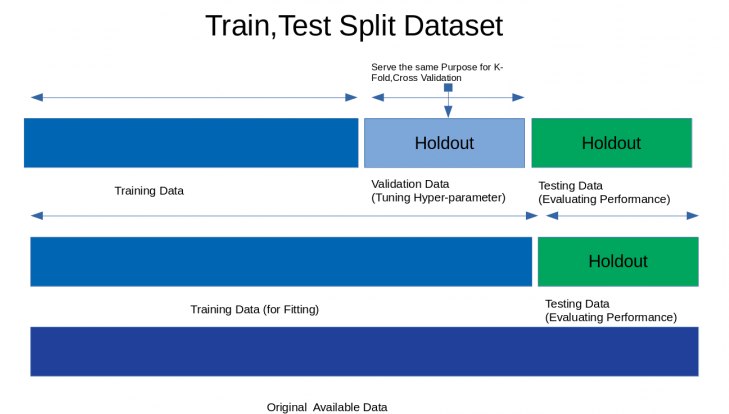
Image Source: blog.jcharistech.com
Pros:
1. Quick To Execute: As we have to split the dataset into training and validation set just once and the model will be built just once on the training set so gets executed quickly.
Cons:
1. Not Suitable for an imbalanced dataset: Suppose we have an imbalanced dataset that has class ‘0’ and class ‘1’. Let’s say 80% of data belongs to class ‘0’ and the remaining 20% data to class ‘1’.On doing train-test split with train set size as 80% and test data size as 20% of the dataset. It may happen that all 80% data of class ‘0’ may be in the training set and all data of class ‘1’ in the test set. So our model will not generalize well for our test data as it hasn’t seen data of class ‘1’ before.
2. A large chunk of data gets deprived of training the model.
In the case of a small dataset, a part will be kept aside for testing the model which may have important characteristics which our model may miss out on as it has not trained on that data.
Python Code:
2. K-Fold Cross-Validation
In this technique of K-Fold cross-validation, the whole dataset is partitioned into K parts of equal size. Each partition is called a “Fold“.So as we have K parts we call it K-Folds. One Fold is used as a validation set and the remaining K-1 folds are used as the training set.
The technique is repeated K times until each fold is used as a validation set and the remaining folds as the training set.
The final accuracy of the model is computed by taking the mean accuracy of the k-models validation data.
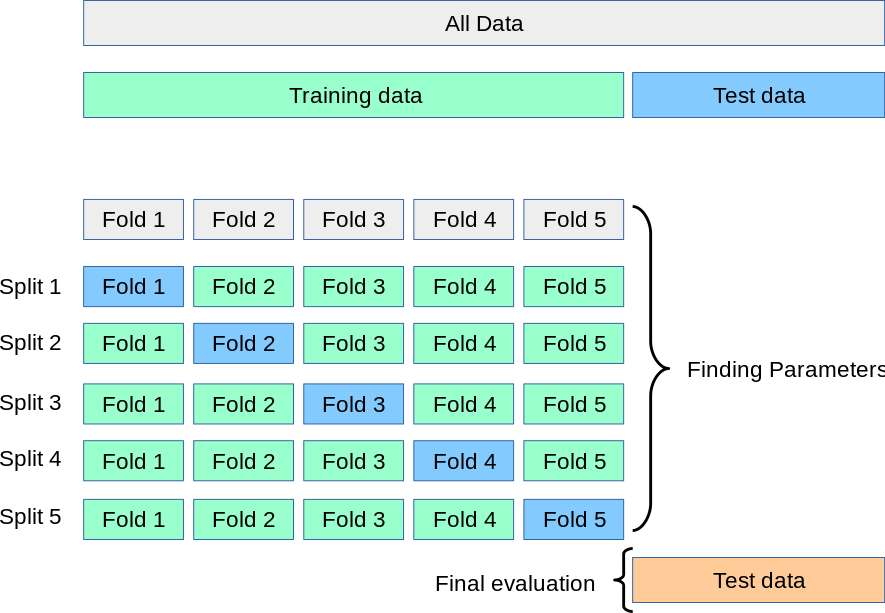
Image Source:scikit-learn.org
Pros:
1. The whole dataset is used as both a training set and validation set:
Cons:
1. Not to be used for imbalanced datasets: As discussed in the case of HoldOut cross-validation, in the case of K-Fold validation too it may happen that all samples of training set will have no sample form class “1” and only of class “0”.And the validation set will have a sample of class “1”.
2. Not suitable for Time Series data: For Time Series data the order of the samples matter. But in K-Fold Cross-Validation, samples are selected in random order.
Python Code:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,KFold
from sklearn.linear_model import LogisticRegression
iris=load_iris()
X=iris.data
Y=iris.target
logreg=LogisticRegression()
kf=KFold(n_splits=5)
score=cross_val_score(logreg,X,Y,cv=kf)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))

3. Stratified K-Fold Cross-Validation
Stratified K-Fold is an enhanced version of K-Fold cross-validation which is mainly used for imbalanced datasets. Just like K-fold, the whole dataset is divided into K-folds of equal size.
But in this technique, each fold will have the same ratio of instances of target variable as in the whole datasets.
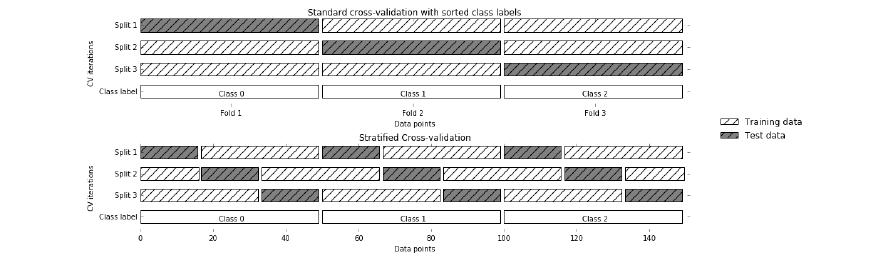
Image Source: Introduction to Machine Learning in Python-O’REILLY
Pros:
1. Works perfectly well for Imbalanced Data: Each fold in stratified cross-validation will have a representation of data of all classes in the same ratio as in the whole dataset.
Cons:
1. Not suitable for Time Series data: For Time Series data the order of the samples matter. But in Stratified Cross-Validation, samples are selected in random order.
Python Code:
<div class="coding-window"><iframe width="100%" height="1400px" frameborder="no" scrolling="no" sandbox="allow-forms allow-pointer-lock allow-popups allow-same-origin allow-scripts allow-modals" allowfullscreen="allowfullscreen" data-src="https://replit.com/@VikramM3/AmusedUrbanProcedures?lite=true"><span data-mce-type="bookmark" style="display: inline-block; width: 0px; overflow: hidden; line-height: 0;" class="mce_SELRES_start"></span></iframe></div>
4. Leave P Out cross-validation
LeavePOut cross-validation is an exhaustive cross-validation technique, in which p-samples are used as the validation set and remaining n-p samples are used as the training set.
Suppose we have 100 samples in the dataset. If we use p=10 then in each iteration 10 values will be used as a validation set and the remaining 90 samples as the training set.
This process is repeated till the whole dataset gets divided on the validation set of p-samples and n-p training samples.
Pros:
All the data samples get used as both training and validation samples.
Cons:
1. High computation time: As the above technique will keep on repeating until all samples get used up as a validation set, it will have higher computational time.
2. Not Suitable for Imbalanced dataset: Same as in K-Fold Cross-validation, if in the training set we have samples of only 1 class then our model will not be able to generalize for the validation set.
Python Code:
from sklearn.model_selection import LeavePOut,cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
iris=load_iris()
X=iris.data
Y=iris.target
lpo=LeavePOut(p=2)
lpo.get_n_splits(X)
tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)
score=cross_val_score(tree,X,Y,cv=lpo)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))

5. Leave One Out cross-validation
LeaveOneOut cross-validation is an exhaustive cross-validation technique in which 1 sample point is used as a validation set and the remaining n-1 samples are used as the training set.
Suppose we have 100 samples in the dataset. Then in each iteration 1 value will be used as a validation set and the remaining 99 samples as the training set. Thus the process is repeated till every sample of the dataset is used as a validation point.
It is the same as LeavePOut cross-validation with p=1.
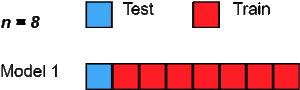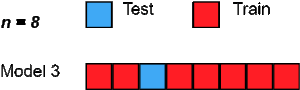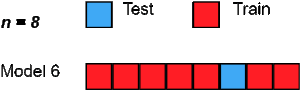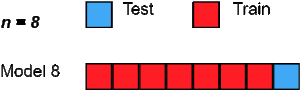
Image Source: www.towardsdatascience.com
Code In Python:
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import LeaveOneOut,cross_val_score
iris=load_iris()
X=iris.data
Y=iris.target
loo=LeaveOneOut()
tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)
score=cross_val_score(tree,X,Y,cv=loo)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))

6. Monte Carlo Cross-Validation(Shuffle Split)
Monte Carlo cross-validation, also known as Shuffle Split cross-validation, is a very flexible strategy of cross-validation. In this technique, the datasets get randomly partitioned into training and validation sets.
We have decided upon the percentage of the dataset we want to be used as a training set and the percentage to be used as a validation set. If the added percentage of training and validation set size is not sum up to 100 then the remaining dataset is not used in either training or validation set.
Let’s say we have 100 samples and 60% of samples to be used as training set and 20% of the sample to be used as validation set then the remaining 20%( 100-(60+20)) is not to be used.
This splitting will be repeated ‘n’ times that we have to specify.

Image Source: Introduction to Machine Learning in Python-O’REILLY
Pros:
1. We are free to use the size of the training and validation set.
2. We can choose the number of repetitions and not depend on the number of folds for repetitions.
Cons:
1. Few samples may not be selected for either training or validation set.
2. Not Suitable for Imbalanced datasets: After we define the size of the training set and validation set, all the samples are randomly selected, so it may happen that the training set may don’t have the class of data that is in the test set, and the model won’t be able to generalize for unseen data.
Python Code:
from sklearn.model_selection import ShuffleSplit,cross_val_score from sklearn.datasets import load_iris from sklearn.linear_model import LogisticRegression
logreg=LogisticRegression() shuffle_split=ShuffleSplit(test_size=0.3,train_size=0.5,n_splits=10)
scores=cross_val_score(logreg,iris.data,iris.target,cv=shuffle_split)
print("cross Validation scores:n {}".format(scores))
print("Average Cross Validation score :{}".format(scores.mean()))

7. Time Series Cross-Validation
What is a Time Series Data?
Time series data is data that is collected at different points in time. As the data points are collected at adjacent time periods there is potential for correlation between observations. This is one of the features that distinguishes time-series data from cross-sectional data.
How cross-validation is done in the case of Time-series data?
In the case of time-series data, we cannot choose random samples and assign them to either training or validation set as it makes no sense in using the values from the future data to predict values of the past data.
As the order of the data is very important for time series related problems, so we split the data into training and validation set according to time, also called as “Forward chaining” method or rolling cross-validation.
We start with a small subset of data as the training set. Based on that set we predict later data points and then check the accuracy.
The Predicted samples are then included as part of the next training dataset and subsequent samples are forecasted.
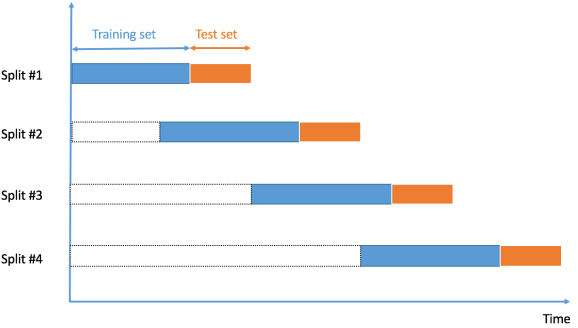
Image Source: www.r-bloggers.com
Pros:
One of the finest techniques .
Cons:
Not suitable for validation of other data types: As in other techniques we choose random samples as training or validation set, but in this technique order of data is very important.
Code In Python:
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
time_series = TimeSeriesSplit()
print(time_series)
for train_index, test_index in time_series.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
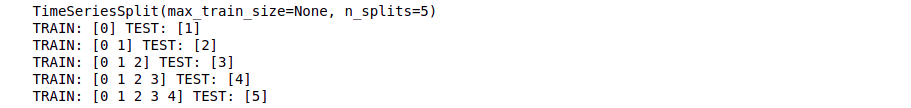
Conclusion
In this article, I tried to give an overview of how various cross-validation techniques work and things we should keep in mind to implement the techniques. I sincerely hope to help you a bit in this journey of data science.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion