



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Data is everywhere these days. Human beings have been sensing, processing, and utilizing it since their birth; now, it is perceptible to machines as well.
The data volume has increased exponentially in the recent past (on to exabytes = 10^6 x terabytes now!), combined together with the availability of a wide variety of data (e.g. demographic, transactional, social, etc.). This scale and complexity are beyond the natural capacity of humans to handle directly.

Machine Learning (ML) is the domain that has come-up to the rescue, to meaningfully process abundant data. It is based on Statistics – a subject couple of centuries-old; the difference being the machine doesn’t make any initial assumptions about the data, rather tries and learns from the data automatically.
With the continuous evolution of technological domains and associated services, human expectations have increased in tandem; necessitating a need by the industry to adapt, make quick and accurate decisions.
Here, the Agile Scrum process has gained popularity across the globe.
While the enterprises have familiarized themselves with the new process, its application to ML (and the acceptance of results) is still nascent.
In this article, an approach of scrumming the ML steps i.e. structuring and sequencing in collaborative sprints, leading to business acceptance, is presented.
Machine Learning Steps
In machine learning, we start with an intent to try and answer the associated business question(s) quantitatively, by looking at the available data. For example:
- What are the key contributors to the observed results? What is the impact of each?
- What is the confidence level of the analysis?
- What are the recommended actions?
The typical sequential steps involved in the exercise are tabulated in Figure 1.
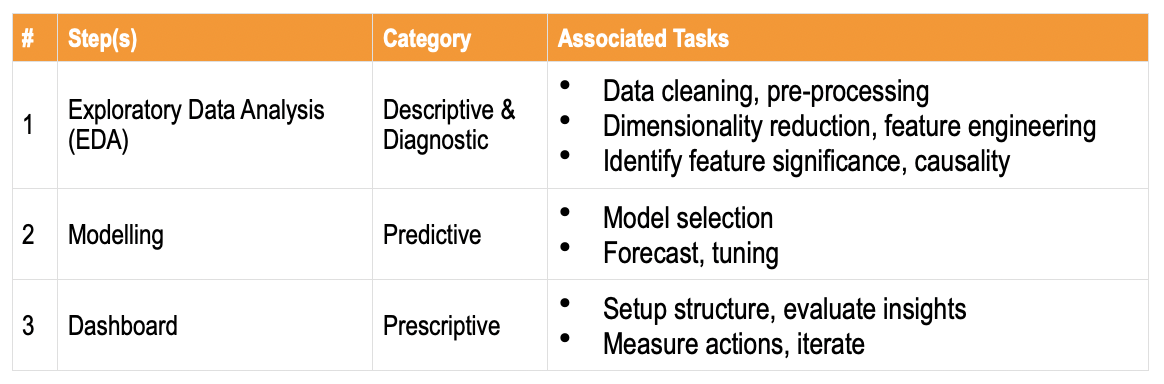
The challenge here is not just the volume and variety of data (e.g. unstructured text), but also its incoming velocity (which may vary continuously e.g. real-time). Additionally, gaps in data (missing values, outliers), limited features, etc. further impede an accurate analysis and hypothesis verification.
In other words, the above steps require close collaboration with the Business to continuously validate the veracity of the incremental results.
Broadly, there are 2 approaches to win over the above challenges.
First, do not move to a subsequent step until the prior is completed fully. Or second, complete the step(s) broadly in a single iteration (e.g. with a small portion of the whole data), and then refine incrementally.
The latter carries the advantage of forecasting an intermediate glimpse of the outcome, during the journey; therefore, preferable.
Structuring a Sprint
Agile Scrum proposes time-boxed durations for each increment, known as a Sprint.
It comprises of regular connections within the team to analyze the data, build and refine model(s), create dashboards and revise them, and finally come up with actionable insights and recommendations.
The idea is to structure a sprint in such a way that it covers all the machine learning steps while devoting a fixed portion of duration to each step; and then, revise these portions incrementally across the sprints.
To take an example, consider a restaurant chain that wants to analyze what factors contribute to its sales and develop the ability to accurately predict the same.
Here, the EDA would primarily explore factors such as restaurant location, available options in the menu for its customers, the seating within the restaurants, dine-in, and takeaways, and the likes.
The modeling and dashboard activities may focus on either individual or a category of items, possibly at the individual restaurant level, and present future sales in a display format that is digestible to the owners.
The above steps in the exercise would undergo multiple iterations, based on feedback.
Figure 2 models a simple release comprising of 4 sprints (each, say, of 1-week).
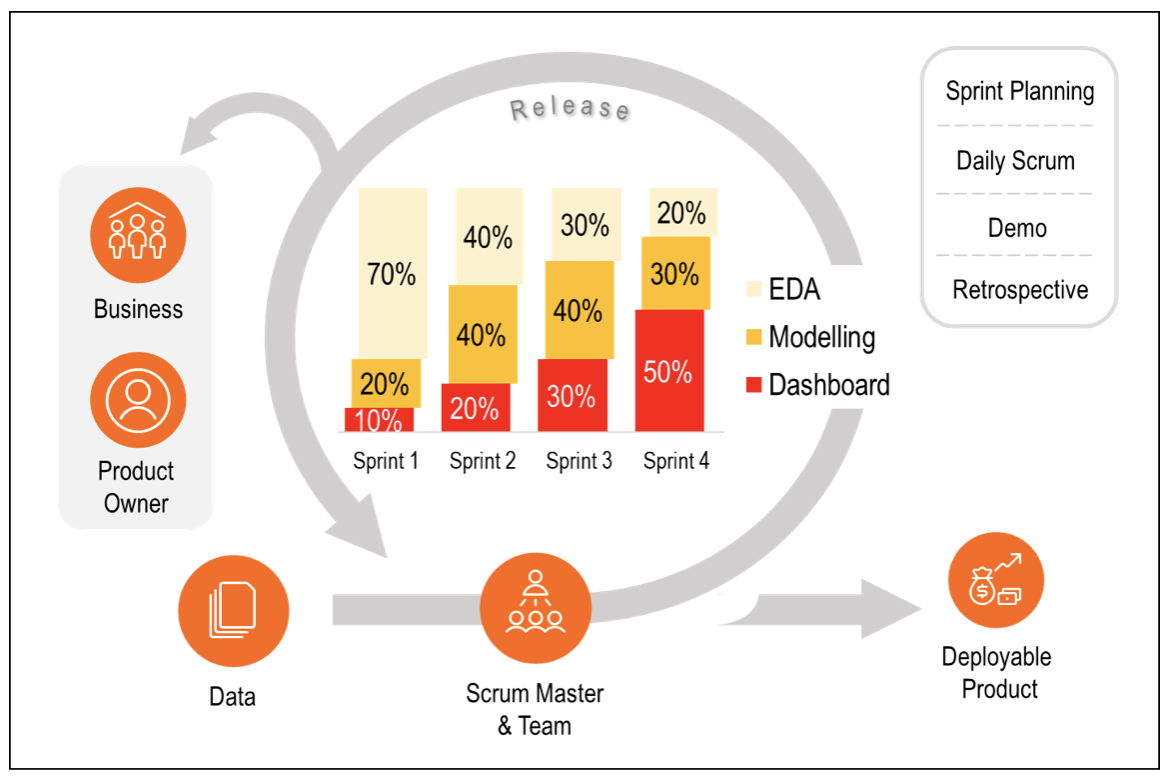
The EDA in Sprint 1 covers over two-thirds of the sprint duration (i.e. 70%), as data familiarity is important in the beginning. Examples of EDA are 5-number summary, univariate & bivariate analysis, correlations, etc. It may result in previously unknown insights e.g. clustering in Unsupervised Learning.
In subsequent sprints, its continuation is needed to accommodate further incoming data; but cover a decreased percentage.
Modeling evaluates the data analysis & causality and provides strategic forecast to fulfill enterprise needs. This needs constant tuning and realignment i.e. re-training based on the latest data and feedback.
Sprint 1 introduces Dashboard to the Business and thereafter needs an increasing focus to help generate measurable actions and monitor them. It enlarges to cover half of the duration in the last sprint (i.e. 50%).
Scrum Master and Teamwork together with the Product Owner and Business continuously.
The first release may serve as a learning-pilot execution.
Fine Tuning and Next Steps
The solution embraces change while covering all the ML steps within a single sprint.
A release may require additional sprints (or even longer ones) based on the data/requirements at hand.
While this may take the release to elapse for more than a month, the primary benefit offered is continuous syncing with the Business at every iteration; finally, resulting in a deliverable holding business value.
It is imperative to have trust in the approach, and thereafter, fine-tune it as needed.
As a final takeaway, clear expectations and honest communication go a long way towards building a strong and trusting relationship with Business.
Scrum Agile is a proven way of solving complex problems.
ML offers an accurate approach for root-cause analysis of the problem, based on data, and coming up with a quantifiable resolution.
The amalgamation of the two, in an incremental manner, enables the delivery of human delight.