



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Suppose you are working in an IT firm as a support desk specialist and receive hundreds of support tickets you have to handle daily. The first task you do with each ticket is to classify it into one of the categories you have developed, such as “Credentials expired”, “Operating System Faulty”, “Hardware malfunctioning”, etc. If you are to categorize each support ticket manually, it would require a lot of time and effort to do so. Thanks to the text classification algorithms and Machine Learning, you can automate this task and save many man hours.
What is Text Classification?
Text classification is a machine learning algorithm that allocates categories to the input text. These categories are predefined and customizable; for example, in the previous example quoted above, “Operating System Faulty”, “Hardware Malfunctioning”, and “Credentials expired” are all predefined categories against which you would want your existing and new input data to be categorized into.
Source: https://www.pexels.com/photo/assorted-beans-placed-in-rows-on-white-fabric-5913170/
Applications of Text Classification
There are various applications of Text Classifications. A few of them include:
- Support ticket classification used by IT companies
- Movies or TV shows classification based on their genres
- Journal papers classification based on their field of research
and so on…
Machine Learning Models for Text Classification
There are currently various Machine Learning models that are used for Text Classification Problems, such as:
- Support Vector Machine
- Naive Bayes Algorithm
- Logistic Regression
But we have mostly seen the implementation of these models on numeric classification. For text classification, we need to convert text data into numerical data first, where vectorization comes in. Before moving forward, let us briefly understand these models.
Support Vector Machine
“Support Vector Machine (SVM) is an excellent regression and classification algorithm that helps maximize a model’s accuracy and avoids overfitting. SVMs work the best when the dataset size is large. Common SVM applications include Image recognition, Customer Relationship Management (CRM) tools, text classification, extraction, etc.
Naive Bayes Algorithm
A Naive Bayes Algorithm (NB), is based on the Bayes theorem and works on the principle of conditional probability, which in turn, measures an event’s probability given that another event has occurred.

Logistic Regression
Logistic Regression is a supervised learning algorithm that helps predict the probability of an event or an outcome. Common Logistic Regression problems consist of binary classification of the input data, such as if the emails are spam or not, or if the person likes the hamburger.
The logistic regression model is based on a Logistic function which is defined as:
Logistic function = (1)/((1+e^(-x)))
Vectorization
Text Vectorization is a process through which text data are converted into numerical data. Various tools help with vectorization, such as:
- Bag of Words Term Frequency
- It is a measure of words’ occurrence in a document. Two metrics are obtained from BoW: a vocabulary of words and the count of those words in a document.
- It is a measure of words’ occurrence in a document. Two metrics are obtained from BoW: a vocabulary of words and the count of those words in a document.
- Binary Term Frequency
- If a particular word is found in the document that is also found in the corpus, we get a 1; if not, we get a 0, hence the name, Binary Term Frequency.
- Term Frequency (L1 Normalized)
- It is the measure of how frequent a word is found in a document
- TF-IDF (L2 Normalized)
- Count of a word in a document/ total words count in that document * log (total number of documents/documents containing the given the word).
- Word2Vec
- Word2Vec is an algorithm that works on building word embeddings through neural networks.
In this article, we will focus on Text Classification using a combination of TF-IDF Vectorization and Logistic Regression. Let us first have a brief introduction to TF-IDF Vectorizer and Logistic Regressor.
Term Frequency-Invert Document Frequency (TF-IDF) Vectorizer
Using the TF-IDF model, we can define the significance of each input word depending on its frequency in the text. It is based on the composite score representing the word’s power. This composite score is calculated by multiplying the Term Frequency (TF) factor with the Inverse Document Frequency (IDF) factor.
Term Frequency (TF): This factor shows the occurrence of a word out of total words in that document and is calculated as :
TF: Count of a word in a document/ total words count in that document
Inverse Document Frequency (IDF): This factor takes the log value of the ratio of the total number of documents and the total number of documents that contain that particular word. It is calculated as:
IDF: log (total number of documents/documents containing the given word).
The higher the TF-IDF value is, the more chances the word is unique and occurs rarely. The lower the value of the factor, the more common the word is. For example, the commonly occurring words, such as “and,” “the,” and “is,” all have a meager value of TF-IDF, nearly equal to zero.
Step1: Vectorization using TF-IDF Vectorizer
Let us take a real-life example of text data and vectorize it using a TF-IDF vectorizer. We will be using Jupyter Notebook and Python for this example. So let us first initiate the necessary libraries in Jupyter.
import pandas as pd import warnings from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_extraction import _stop_words
TfidfVectorizer is the required library we need to import from sklearn.feature_extraction. _stop_words is used here to list all the common words in a language.
For this example, we will use the publically available Internet Movie Database (IMDB) movie titles and genres dataset, which can be downloaded from here. I have downloaded the file named “title.basics.tsv.gz“. This is a huge file, around 150MB, with millions of rows. For simplicity, I have taken only the initial 1000+ entries of the dataset and split the dataset into two files, the first 1028 rows for the training dataset (just a random number, no logic behind 1028), called imdb_train.csv, and the remaining 18 entries as imdb_test.csv. We will first be training on the training dataset and then testing our model on the unseen test dataset and letting the model classify the 18 movies into their genres. Finally, we will evaluate how our model did by comparing any random movie’s predicted genre with the actual genre.
Step2: Loading and Visualizing the Dataset
Let us load and display the training dataset as follows:
Python Code:
We have 1058 movie titles along with their genres. There are 17 different genres in which 1058 movies are classified.
Step 3: Vectorization
We will first create a matrix of the movie titles in a corpus.
corpus = train_data['primaryTitle'].values corpus

Then, we will vectorize our corpus
vectorizer = TfidfVectorizer(stop_words='english') X = vectorizer.fit_transform(corpus) print(vectorizer.get_feature_names())

First, we generating the Vectorizer object using vectorizer = TfidfVectorizer(stop_words=’english’) command. In the next step, we converted the input text into a TF-IDF matrix using X = vectorizer.fit_transform(corpus) command, and we print the words selected in the TF-IDF matrix in the final step.
Vector_Text=pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names()) Vector_Text['originalText']=pd.Series(corpus) Vector_Text
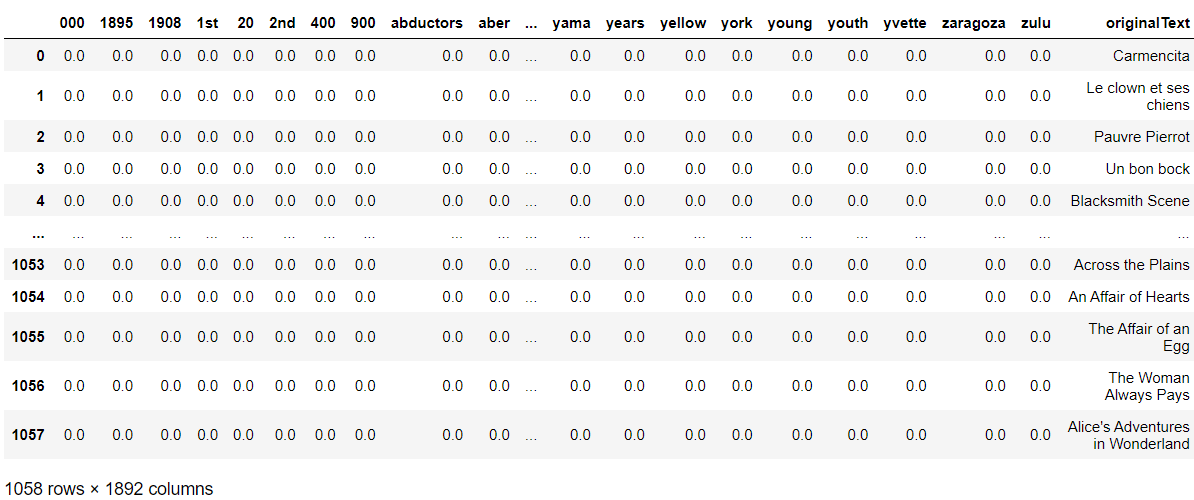
In the previous step, we visualized the document term matrix using TF_IDF. Now let us add the genres column back to the vectorized table.
ML_Data=pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names()) ML_Data['genres']=train_data['genres'] ML_Data.head()
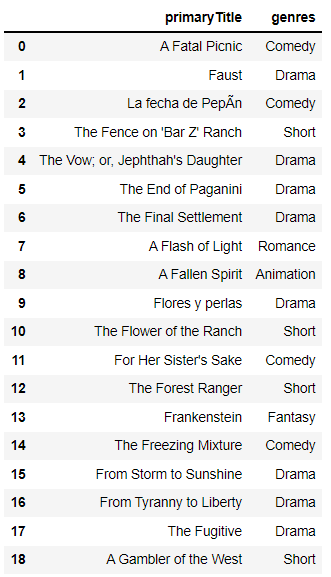

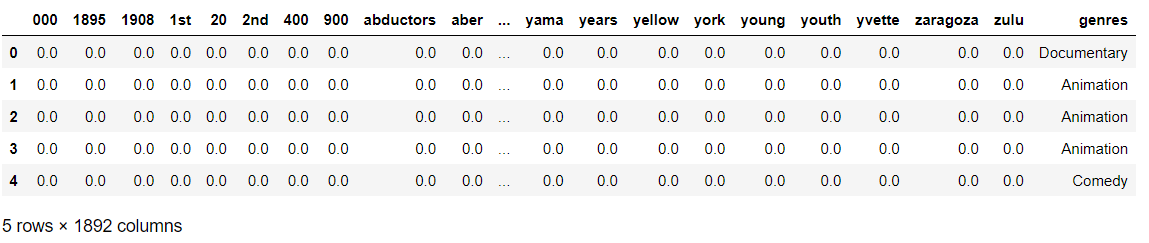
Step4: Data Formatting
Now let us do some data formatting and adjustments
Target=ML_Data.columns[-1] Predictors=ML_Data.columns[:-1] X=ML_Data[Predictors].values y=ML_Data[Target].values
Step5: Logistic Regression for Classification
The Logistic regression model helps estimate an event’s probability based on the independent variables dataset. We can try other models for classification, such as Naive Bayes, Decision Trees, and such, but for simplicity, we are using Logistic Regression here. Readers are encouraged to try the other models and comment if those models produced a better result.
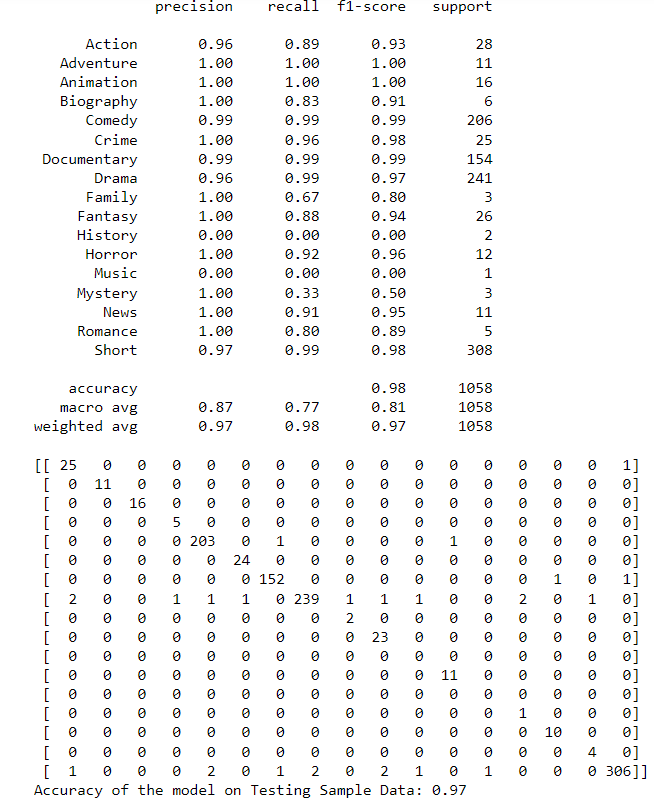
from sklearn.linear_model import LogisticRegression from sklearn import metrics clf = LogisticRegression(C=5, solver='newton-cg',penalty='l2') LOG=clf.fit(X,y) pred=LOG.predict(X) Test_Data=pd.DataFrame(data=X, columns=Predictors) Test_Data['TargetVariable']=y Test_Data['Prediction']=pred print(Test_Data.head()) print(metrics.classification_report(y, pred)) print(metrics.confusion_matrix(pred, y)) F1_Score=metrics.f1_score(y, pred, average='weighted') print('Accuracy of the model on Testing Sample Data:', round(F1_Score,2)
Step6: Predictions for New Movie Labels
In this step, we will be loading the test dataset and see how our model does with predicting the movies’ genres. We will define a function that converts the words into numeric vectors.
def genres_test(inpText):
X=vectorizer.transform(input_text)
Prediction=FinalModel.predict(X)
Result=pd.DataFrame(data=input_text, columns=['title'])
Result['Prediction']=Prediction
return(Result)
Now, let’s call the function
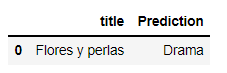
movie_name=["Flores y perlas"] predicted_genre=genres_test(input_text=movie_name) predicted_genre
Results of Text Classification
Now let us compare the predicted genre with the original genre of the same title in our dataset.
test_data=pd.read_csv('imdb_test.csv')
test_data
We can see in row number 9 that the actual genre of the movie “Flores y perlas” is also “Drama”.
Conclusion
In this article, we started by defining what Text Classification is in the field of Machine Learning and what its applications are. Then, we read how text classification is carried out by first vectorizing our text data using any vectorizer model such as Word2Vec, Bag of Words, or TF-IDF, and then using any classical classification methods, such as Naive Bayes, Decision Trees, or Logistic Regression to do the text classification.
We used the refined IMDB movies dataset with just the movie titles and their genres. Fed the model with a portion of the dataset so it could learn and then fed it with new unseen data to predict the movies’ genres, which it did with high accuracy.
Key takeaways from this article are:
- Text Classification is a crucial machine learning function. It has multiple applications in the field, such as Support ticket classification used by IT companies, Movies or TV shows classification based on their genres and journal papers classification based on their field of research, etc.
- Text classification is a two-step process. First, we need to convert the input text into vectors and then classify those vectors using a classification algorithm.
- Various vectorization algorithms are available such as TF-IDF, Word2Vec, Bag of Words, etc. Similarly, various classification algorithms include Logistic Regression, Naive Bayes, and Decision Trees/Random Forest.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.