



Introduction

In this blog, I will discuss various things on the recommendation system like what is the recommendation system? What are its use-cases? How many types of recommendation systems and metrics are used for it.
In the above picture of amazon, you may have often seen this page when you try to purchase anything from amazon. These are the recommendation of the product you are trying to purchase and you will be amazed to know that amazon’s 35% of the revenue comes from these recommendation engines. Now you may have noticed the power of the recommendation engine. Nowadays every small to big company uses a recommendation engine. So now let me discuss this.
What Is Recommendation System?
A recommendation system is a subclass of Information filtering Systems that seeks to predict the rating or the preference a user might give to an item. In simple words, it is an algorithm that suggests relevant items to users. Eg: In the case of Netflix which movie to watch, In the case of e-commerce which product to buy, or In the case of kindle which book to read, etc.
Use-Cases Of Recommendation System
There are many use-cases of it. Some are
A. Personalized Content: Helps to Improve the on-site experience by creating dynamic recommendations for different kinds of audiences like Netflix does.
B. Better Product search experience: Helps to categories the product based on their features. Eg: Material, Season, etc.
TYPES OF RECOMMENDATION SYSTEM
1. Content-Based Filtering
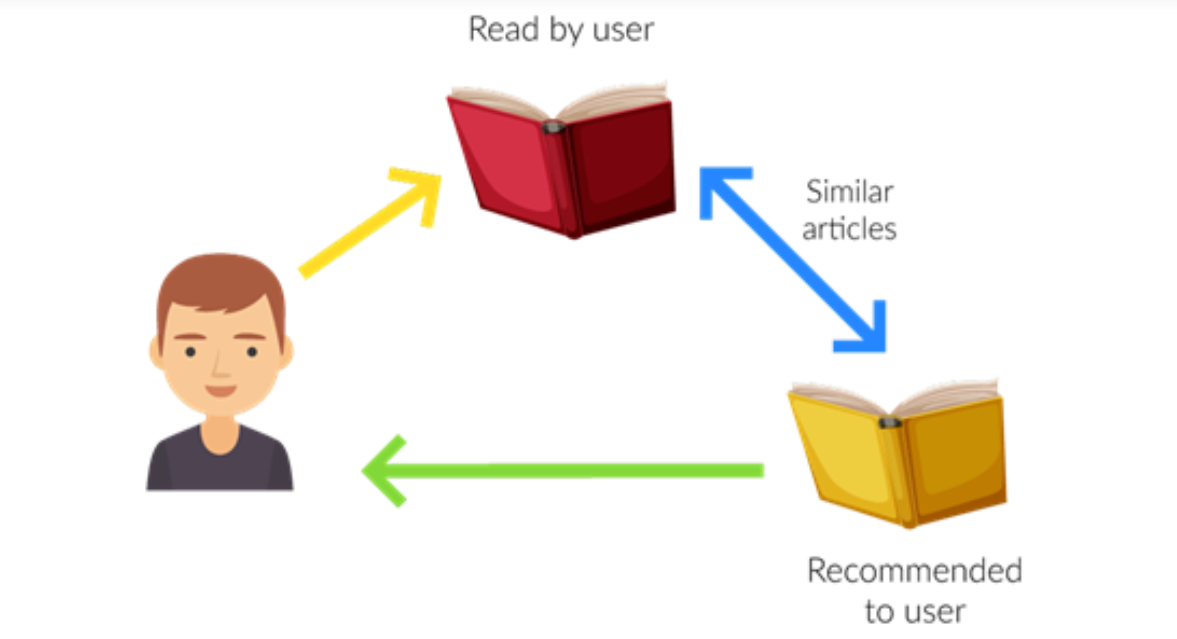
In this type of recommendation system, relevant items are shown using the content of the previously searched items by the users. Here content refers to the attribute/tag of the product that the user like. In this type of system, products are tagged using certain keywords, then the system tries to understand what the user wants and it looks in its database and finally tries to recommend different products that the user wants.
Let us take an example of the movie recommendation system where every movie is associated with its genres which in the above case is referred to as tag/attributes. Now let assume user A comes and initially system don’t have any data about user A. so initially, the system tries to recommend the popular movies to the users or the system tries to get some information of the user by getting a form filled by the user. After some time, users might have given a rating to some of the movies like it gives a good rating to movies based on the action genre and a bad rating to the movies based on the anime genre. So here system recommends action movies to the users. But here you can’t say that the user dislikes animation movies because maybe the user dislikes that movie due to some other reason like acting or story but actually likes animation movies and needs more data in this case.
Advantage
- Model doesn’t need data of other users since recommendations are specific to a single user.
- It makes it easier to scale to a large number of users.
- The model can Capture the specific Interests of the user and can recommend items that very few other users are interested in.
Disadvantage
- Feature representation of items is hand-engineered to some extent, this tech requires a lot of domain knowledge.
- The model can only make recommendations based on the existing interest of a user. In other words, the model has limited ability to expand on the user’s existing interests.
2. Collaborative Based Filtering
Recommending the new items to users based on the interest and preference of other similar users is basically collaborative-based filtering. For eg:- When we shop on Amazon it recommends new products saying “Customer who brought this also brought” as shown below.

This overcomes the disadvantage of content-based filtering as it will use the user Interaction instead of content from the items used by the users. For this, it only needs the historical performance of the users. Based on the historical data, with the assumption that user who has agreed in past tends to also agree in future.
There are 2 types of collaborative filtering:-
A. User-Based Collaborative Filtering
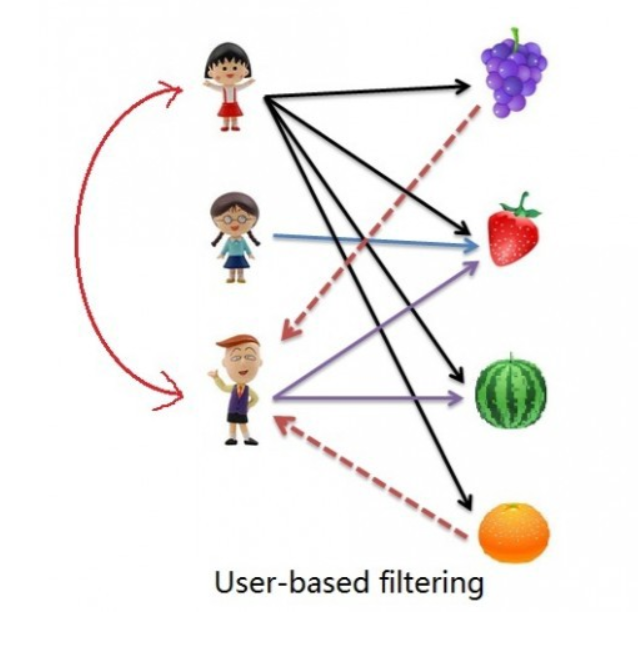
Rating of the item is done using the rating of neighbouring users. In simple words, It is based on the notion of users’ similarity.
Let see an example. On the left side, you can see a picture where 3 children named A, B, C, and 4 fruits i.e, grapes, strawberry, watermelon, and orange respectively.
Based on the image let assume A purchased all 4 fruits, B purchased only strawberry and C purchased strawberry as well as watermelon. Here A & C are similar kinds of users because of this C will be recommended Grapes and Orange as shown in dotted line.
B. Item-Based Collaborative Filtering
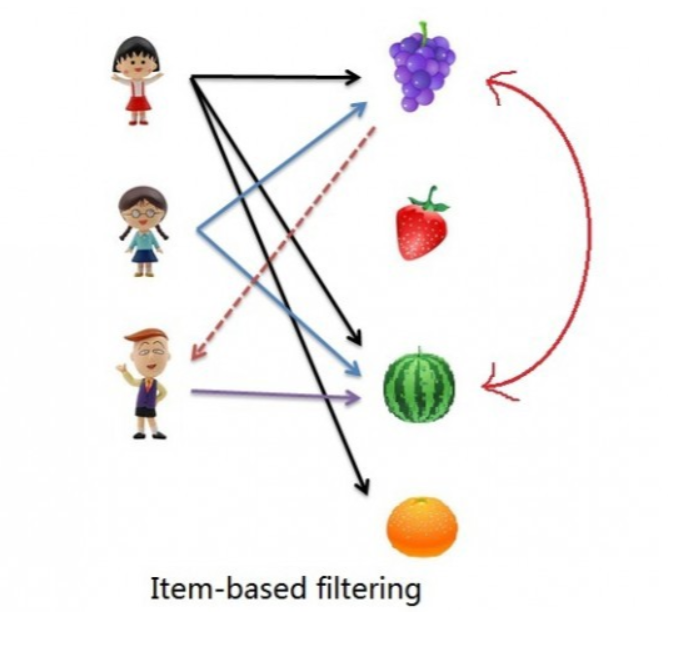
{kind=link}
The rating of the item is predicted using the user’s own rating on neighbouring items. In simple words, it is based on the notion of item similarity.
Let us see with an example as told above about users and items. Here the only difference is that we see similar items, not similar users like if you see grapes and watermelon you will realize that watermelon is purchased by all of them but grapes are purchased by Children A & B. Hence Children C is being recommended grapes.
Now after understanding both of them you may be wondering which to use when. Here is the solution if No. of items is greater than No. of users go with user-based collaborative filtering as it will reduce the computation power and If No. of users is greater than No. of items go with item-based collaborative filtering. For Example, Amazon has lakhs of items to sell but has billions of customers. Hence Amazon uses item-based collaborative filtering because of less no. of products as compared to its customers.
Advantage
- It works well even if the data is small.
- This model helps the users to discover a new interest in a given item but the model might still recommend it because similar users are interested in that item.
- No need for Domain Knowledge
Disadvantage
- It cannot handle new items because the model doesn’t get trained on the newly added items in the database. This problem is known as Cold Start Problem.
- Side Feature Doesn’t have much importance. Here Side features can be actor name or releasing year in the context of movie recommendation.
EVALUATION METRICS
As we have discussed different types of recommendation systems their advantages and disadvantages but how can we evaluate whether the given model is recommending the right things or not and how many relevant things this system predicts and here comes evaluation metrics. There are several metrics for evaluating the model but here we will discuss 4 major metrics.
1. Mean Average precision at K
It gives how much relevant is the list of recommended items. Here precision at K means Recommended items in top k sets that are relevant.
2. Coverage
It is the percentage of items in the training data model able to recommend in test sets. Or Simply, the percentage of a possible recommendation system can predict.
3. Personalization
It is basically how many same items the model recommends to different users. Or, the dissimilarity between users lists and recommendations.
4. Intralist Similarity
It is an average cosine similarity of all items in a list of recommendations.
CONCLUSION
This blog covered many topics related to recommendation engines like What are it and its use-cases. Apart from this different types of recommendation systems like content-based filtering and collaborative based filtering and in collaborative filtering also user-based as well as item-based along with its examples, advantages and disadvantages, and finally the evaluation metrics to evaluate the model.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.