



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
We all check our email every day, possibly more than once. The majority of email service providers have the useful feature of automatically separating spam emails from other emails. This is an example of a common NLP problem called text classification.
Text is unstructured and getting insights from it can be difficult and time-consuming. But categorizing text data is becoming simpler as a result of developments in machine learning and natural language processing.
In this article, we will understand more about text classification and create a model to classify comments into toxic and non-toxic.
What is Text Classification?
Classification in machine learning refers to the problem of identifying a data item into one or more predefined classes. The data point can be in a variety of formats, including text, numerical, audio or image. Text classification is a specific case of the classification problem in which text is used as the input data point and the objective is to classify the text into one or more predefined classes.
Depending on the number of categories included, every supervised classification method can be further divided into three categories: binary, multiclass, and multilabel classification. Binary classification is used when the number of classes is two. Multiclass classification is the term used when there are more than two classes. A document may have one or more labels or classes associated with it when using multilabel classification
In the email spam identifier, we have two categories spam and non-spam. Every email is pre-processed and passed through a classifier which categorizes the email into spam and non-spam.
Applications of Text Classification
- Classification of textual data includes content organization, search engines, recommendation systems etc.
- Fake news classification is another example of text classification.
- Customer Support: Sometimes brands require to respond to messages received in the form of tweets or emails. A customer may be voicing a complaint or a desire to buy a product. Thus it is necessary to identify the intent of these messages.
- Sentiment Analysis of reviews on e-commerce websites to understand customers’ perception of a product based on their comments.
How to do Text Classification?
On social media, people are free to express themselves. There are numerous online forums these days where users actively participate and post a comment. However, occasionally if someone uses abusive language, it becomes essential to filter these comments. To address this issue, we will develop a model that determines whether or not a comment is toxic.
We will use the toxic comments dataset, which comprises a large number of Wikipedia comments labelled as toxic by human raters. There are six types of toxicities in this data: toxic, severe-toxic, obscene, threat, insult and identity-hate. A comment may fall under more than one category. As a result, it becomes a multilabel classification problem.
Import the necessary libraries
import pandas as pd import numpy as np from nltk.corpus import stopwords import re import string from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, classification_report, roc_auc_score ,confusion_matrix from nltk.stem import WordNetLemmatizer, PorterStemmer
from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import MultinomialNB, GaussianNB
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
plt.rcParams['figure.figsize'] = (15, 10)
Load the dataset
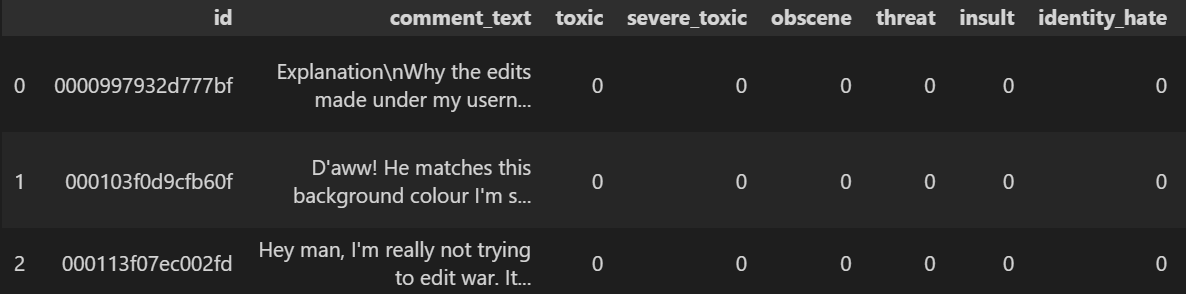
We can find the number of comments in each category in the dataset using the following code.
Python Code:
Data Cleaning
We will clean the text by removing the punctuations and converting all the abbreviations into their full forms.
def clean_text(text):
text = text.lower()
text = re.sub(r"i'm", "i am", text)
text = re.sub(r"r", "", text)
text = re.sub(r"he's", "he is", text)
text = re.sub(r"she's", "she is", text)
text = re.sub(r"it's", "it is", text)
text = re.sub(r"that's", "that is", text)
text = re.sub(r"what's", "that is", text)
text = re.sub(r"where's", "where is", text)
text = re.sub(r"how's", "how is", text)
text = re.sub(r"'ll", " will", text)
text = re.sub(r"'ve", " have", text)
text = re.sub(r"'re", " are", text)
text = re.sub(r"'d", " would", text)
text = re.sub(r"'re", " are", text)
text = re.sub(r"won't", "will not", text)
text = re.sub(r"can't", "cannot", text)
text = re.sub(r"n't", " not", text)
text = re.sub(r"n'", "ng", text)
text = re.sub(r"'bout", "about", text)
text = re.sub(r"'til", "until", text)
text = re.sub(r"[-()"#/@;:{}`+=~|.!?,]", "", text)
text = text.translate(str.maketrans('', '', string.punctuation))
text = re.sub("(\W)"," ",text)
text = re.sub('S*dS*s*','', text)
return text
df["text"] = df['comment_text'].apply(lambda text: clean_text(text)
We can compare the cleaned text and the original comment using:
df[['comment_text','clean_text']].head(2)
| comment_text | clean_text | |
| 0 | ExplanationnWhy the edits made under my usern.. | explanation why the edits made under my userna… |
| 1 | D’aww! He matches this background colour I’m s… | daww he matches this background colour i am se… |
Train Test Split
cols_target = ['toxic','severe_toxic','obscene','threat','insult','identity_hate']
X_train, X_test, y_train, y_test = train_test_split(df['text'], df[cols_target], test_size= 0.3)
We can check the dimensions using:
print(X_train.shape) print(y_train.shape) print(X_test.shape) print(y_test.shape)
(95742,)
(95742, 6)
(63829,)
(63829, 6)
Vectorise the text
We will use TfidfVectorizer to create vectors of the textual data.
vect = TfidfVectorizer(
strip_accents='unicode',
analyzer='word',
token_pattern=r'w{1,}',
ngram_range=(1, 3),
stop_words='english',
sublinear_tf=True)
X_train = vect.fit_transform(X_train) X_test = vect.transform(X_test)
Use the OneVsRestClassifier
As we know this is a multilabel classification problem and each comment may belong to one or more categories. The multilabel classification can be transformed into binary classification by building a distinct model for each category. This can be accomplished by training six separate models while iterating over the categories in a loop. One simple method to accomplish this is to use OneVsRestClassifier, which automatically fits one classifier per class. To build the model, we will wrap a Multinomial Naive Bayes Classifier in OneVsRestClassifier.
model = OneVsRestClassifier(MultinomialNB()) model.fit(X_train,y_train) y_pred = model.predict(X_test)
Evaluate the model
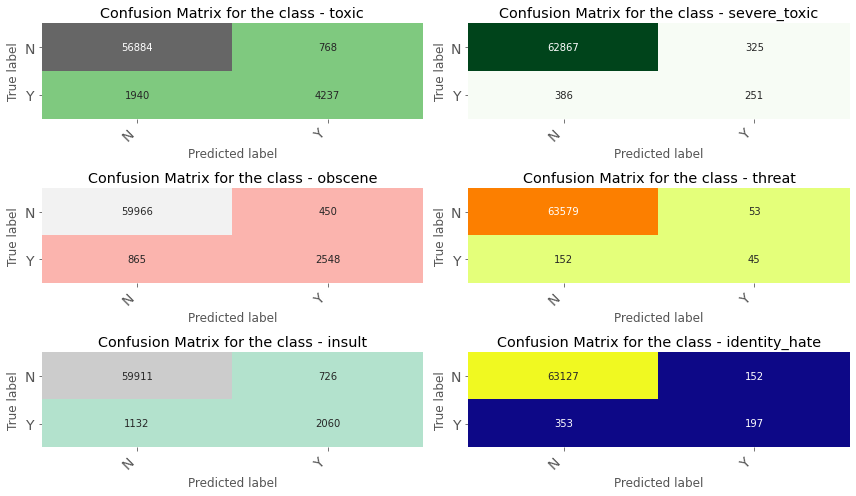
To evaluate the model we will create a confusion matrix for each category.
cfs = []
for i in range(6):
cf = np.asarray(confusion_matrix(y_test[cols_target[i]], predicted_y_test[:,i]))
cfs.append(cf)
def print_confusion_matrix(confusion_matrix, axes, class_label, class_names,c,fontsize=14):
df_cm = pd.DataFrame(
confusion_matrix, index=class_names, columns=class_names,
)
heatmap = sns.heatmap(df_cm, annot=True,cmap=c, fmt="d", cbar=False, ax=axes)
heatmap.yaxis.set_ticklabels(heatmap.yaxis.get_ticklabels(), rotation=0, ha='right', fontsize=fontsize)
heatmap.xaxis.set_ticklabels(heatmap.xaxis.get_ticklabels(), rotation=45, ha='right', fontsize=fontsize)
axes.set_ylabel('True label')
axes.set_xlabel('Predicted label')
axes.set_title("Confusion Matrix for the class - " + class_label)
fig, ax = plt.subplots(3, 2, figsize=(12, 7))
cmaps = ['Accent','Greens','Pastel1','Wistia','Pastel2','plasma']
for axes, cfs_matrix, label, i in zip(ax.flatten(), cfs, cols_target,range(6)):
c = cmaps[i]
print_confusion_matrix(cfs_matrix, axes, label,["N", "Y"],c,14)
fig.tight_layout()
plt.show()
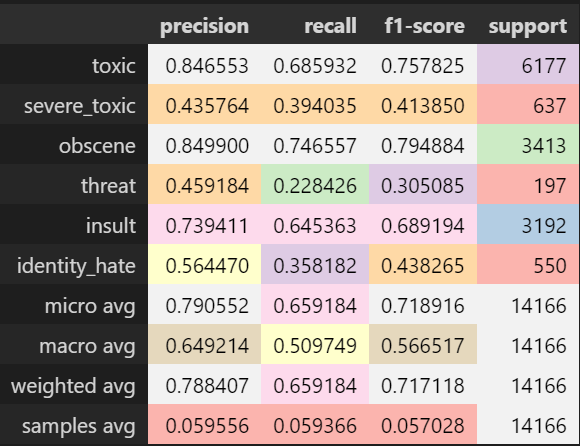
A classification report can be obtained using:
cr = pd.DataFrame(classification_report(y_test,y_pred, target_names=cols_target,output_dict=True)).T cr['support'] = cr.support.apply(int) cr.style.background_gradient(cmap='Pastel1')
Use the model
Now that we have built and evaluated our model, which performs pretty well without any tuning. We will use our model to predict the toxicity of a user-defined comment.
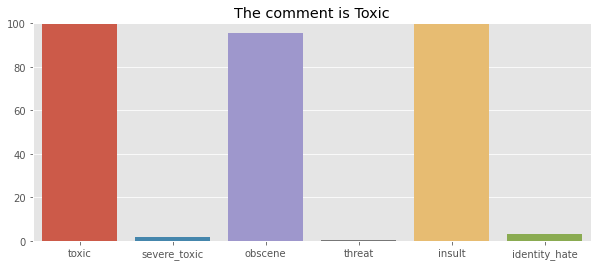
def make_test_predictions(df,classifier):
df.comment_text = df.comment_text.apply(clean_text)
X_test = df.comment_text
X_test_transformed = vect.transform(X_test)
y_test_pred = classifier.predict_proba(X_test_transformed)
a = np.array(y_test_pred[0])
sns.barplot(x = cols_target,y =a*100)
plt.ylim((0,100))
result = sum(y_test_pred[0])
if result >= 1:
plt.title('The comment is Toxic')
else :
plt.title('The comment is Non Toxic')
#Enter the comment
comment_text = "how can you say that stupid"
comment ={'id':[1],'comment_text':[comment_text]}
comment = pd.DataFrame(comment)
make_test_predictions(comment,model)
comment_text = "You are a good musician"
comment ={'id':[1],'comment_text':[comment_text]}
comment = pd.DataFrame(comment)
make_test_predictions(comment,model)
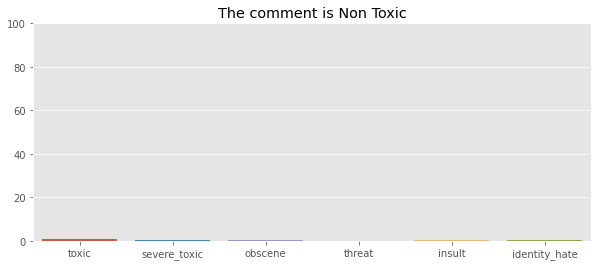
The graphs display the probability percentage to which a comment may belong. When the probabilities are added up, if the total is less than 1, the comment is considered non-toxic because it does not fit into any of the categories; otherwise, the comment is toxic.
Conclusion
In this article, we discussed text classification and understood how text classification can be quite helpful in extracting meaningful insights from text data. We developed a multi-label classifier and applied our trained model to predict the toxic comments.
I hope that after reading this, you are prepared to solve text classification problems for your use case and scenario, understand how to leverage the current solution, and create your own classifiers.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.