



{kind=link}
This article was published as a part of the Data Science Blogathon
Introduction
Oops! What is MLOps? – asked the guy who read the term for the first time.
There has been a lot of buzz around this word recently, isn’t it? Hold on! This article will make things simple for you by the use of examples and practical code-based implementation on this topic.
In earlier times, producing classic cars and automobiles involved a great work of craftmanship. The workers would gather at a single place to work on making a model by using their tools and fitting the metallic car parts. The process would take days and months with the cost being high obviously. Over time, the industrial revolution came in and it started making things efficient and it was only Henry Ford and his company that started producing car models efficiently and at a reduced price. How did this magic happen? All thanks to the assembly line!
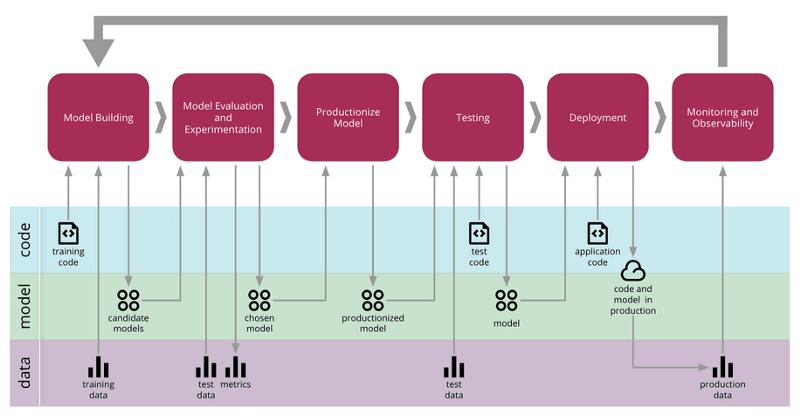
Taking forward the analogy, it won’t be wrong to call MLOps the assembly line for Machine Learning. The term MLOps is a combination of ‘Machine Learning’ and ‘Operations’, meaning that it is a way to manage the operations of ML models, the codes, the data, and everything involved from making it to using it. And not just using it once, but by improving it continuously.
For you to have clarity on MLOps, you need to understand this – For a student working on an ML project individually, probably all the steps are done by him on his laptop, in a single environment, with not much complexity involved. But in a corporate or a tech company, there are several Data Scientists and Engineers working simultaneously and they should be doing all steps efficiently, especially to serve a customer or the use-case.
Remember Henry Ford did the same thing efficiently and even in MLOps, we do the conventional model building/deploying things in a better and more organized way.
WHAT EXACTLY IS MLOps?
Is it new software, a new library/module, or some piece of code? You can still get your answer if you imagine the ‘assembly line’.
MLOps is a concept that involves a set of practices for operating all the steps involved in making Machine Learning work. The exact steps will vary but it generally involves gathering data, making and testing models, improving the models, putting them to use, and then again improving it based on real-time feedback. For all these to happen, there should be an exact set of processes and this is where MLOps comes in.
It’s important to know that MLOps is basically derived from DevOps – the same concept that has been in use for quite a while now in the software domain. It includes a lot of concepts that make it unique, bringing the adoption of MLOps to a dire necessity today. These are –
Focusing on the Machine Learning lifecycle –
The concept of MLOps is primarily based on the idea that every Machine Learning project has to have a lifecycle. Proper implementation is possible only upon giving importance to every step in this cycle. Often data scientists and engineers (having shared roles) work on any one of these steps and thus a proper organization & set of practices is always required. This gives rise to the concept of MLOps.
CI/CD/CT through pipelines & automation –
CI stands for continuous integration. CD stands for continuous development. CT stands for continuous training. MLOps focuses on continuously improving the ML model based on the evaluation and feedback received upon its testing and deployment. The code is subject to several changes across the ML lifecycle and thus a feedback loop is in play through pipelines that automate the process to make it fast.
Making things scalable, efficient, collaborative –
There’s no use of MLOps if it’s no better in comparison to the existing platforms and frameworks. With ML being a known concept for some years now, every team/company most probably has its own strategies for managing the work distribution amongst their people. By adopting the concept of MLOps, the collaboration gets more scalable and efficient with the time consumed is less. This is especially made possible through the various platforms.
LEVERAGING MLOps PLATFORMS
If you have been eager to know how exactly MLOps is implemented, then just like DevOps, it is possible through the various platforms that are available for this job. These allow you to make a pipeline so that you or your company can create an organized integration of ML models, codes, and data. Some of the platforms by the tech leaders are – Google Cloud AI Platform, Amazon SageMaker, Azure Machine Learning.
There are several open-source platforms also, like the MLflow which we will be discussing practically implement today.
GETTING THE FLOW WITH MLflow
When it comes to implementing MLOps, MLFlow is certainly a leading name. With various components to monitor your operations, it makes training, testing, tracking, and rebuilding of models easier, throughout their lifecycle. It’s a very useful platform to quickly set up your company projects onto MLOps infrastructure so that people with different job roles can work collaboratively on a single project.
To start with, MLflow majorly has three components – Tracking, Projects, and Models. This chart sourced from the MLflow site itself clears the air.
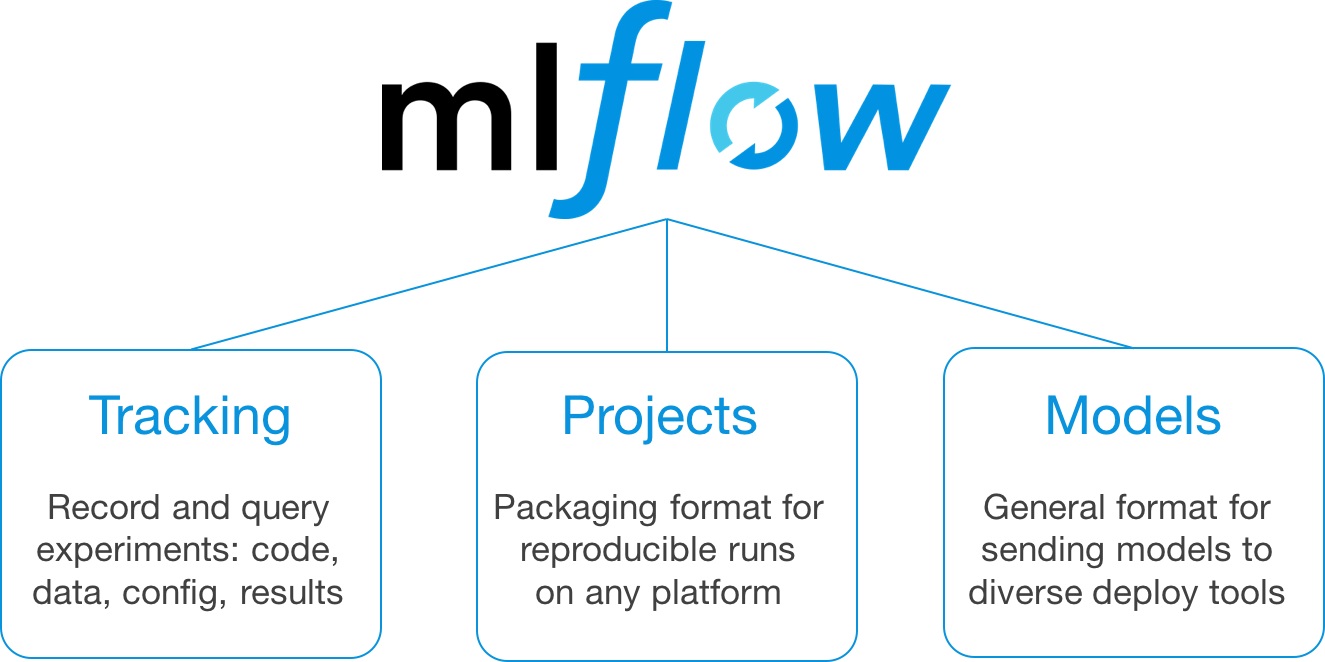
While ‘tracking’ is for keeping a log of changes that you make, ‘projects’ is for creating desired pipelines. We have the Models feature. An MLFlow model is a standard format for packaging machine learning models that can be used in a variety of downstream tools — for example, real-time serving through a REST API or batch inference on Apache Spark.
HANDS-ON WITH MLflow & Google Colab
With all things said and done, it’s time to get going and set up MLflow for our own projects. As said earlier, you can get the true essence of the MLOps concept only in a real corporate environment when you are working with other people with shared roles. Nevertheless, you can have an experience of how it works on your own laptop.
We will be installing and setting MLflow on Google Colab. You can of course do it in your local environment or Jupyter Notebook. But by using Colab, we keep it fast and shareable. We also get some things to learn, like using ngrock to get a public URL for remote tunnel access. Let’s get started by opening a new notebook and trying the code below.
## Step 1 - Installing MLflow and checking the version
!pip install mlflow --quiet import mlflow print(mlflow.__version__)
## Step 2 - Starting MLflow, running UI in background
with mlflow.start_run(run_name="MLflow on Colab"):
mlflow.log_metric("m1", 2.0)
mlflow.log_param("p1", "mlflow-colab")
# run tracking UI in the background
get_ipython().system_raw("mlflow ui --port 5000 &")
## Step 3 - Installing pyngrok for remote tunnel access using ngrock.com
!pip install pyngrok --quiet from pyngrok import ngrok from getpass import getpass # Terminate open tunnels if any exist ngrok.kill()
## Step 4 - Login on ngrok.com and get your authtoken from https://dashboard.ngrok.com/auth
# Enter your auth token when the code is running
NGROK_AUTH_TOKEN = getpass('Enter the ngrok authtoken: ')
ngrok.set_auth_token(NGROK_AUTH_TOKEN)
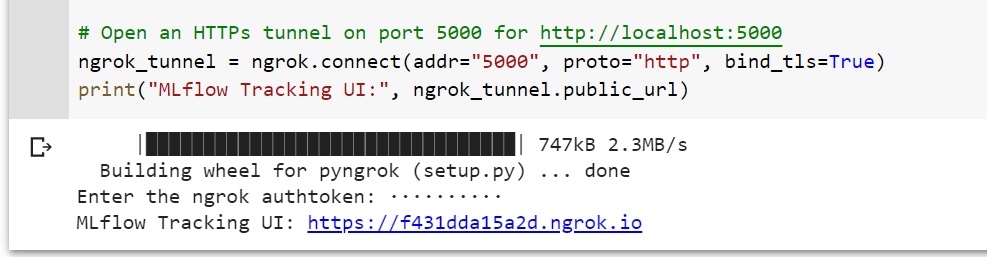
ngrok_tunnel = ngrok.connect(addr="5000", proto="http", bind_tls=True)
print("MLflow Tracking UI:", ngrok_tunnel.public_url)
## Step 5 - Loading dataset, training a XGBoost model and tracking results using MLflow
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, log_loss
import xgboost as xgb
import mlflow
import mlflow.xgboost
def main():
# Loading iris dataset to prepare test and train
iris = datasets.load_iris()
X = iris.data
Y = iris.target
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=25)
# enable auto logging in MLflow
mlflow.xgboost.autolog()
dtrain = xgb.DMatrix(X_train, label=Y_train)
dtest = xgb.DMatrix(X_test, label=Y_test)
with mlflow.start_run():
# train the XGBoost model
params = {
"objective": "multi:softprob",
"num_class": 3,
"learning_rate": 1,
"eval_metric": "mlogloss",
"seed": 42,
}
model = xgb.train(params, dtrain, evals=[(dtrain, "train")])
# evaluate model
Y_prob = model.predict(dtest)
Y_pred = Y_prob.argmax(axis=1)
loss = log_loss(Y_test, Y_prob)
acc = accuracy_score(Y_test, Y_pred)
# log metrics
mlflow.log_metrics({"log_loss": loss, "accuracy": acc})
if __name__ == "__main__":
main()
By clicking on the link generated before, you should be able to see the list of experiments on the MLflow UI page. Every experiment is listed along with several parameters and metrics. You can search, filter, and compare them too. By clicking on each experiment, you get to discover a lot more details. There’s also an option to download in CSV format.
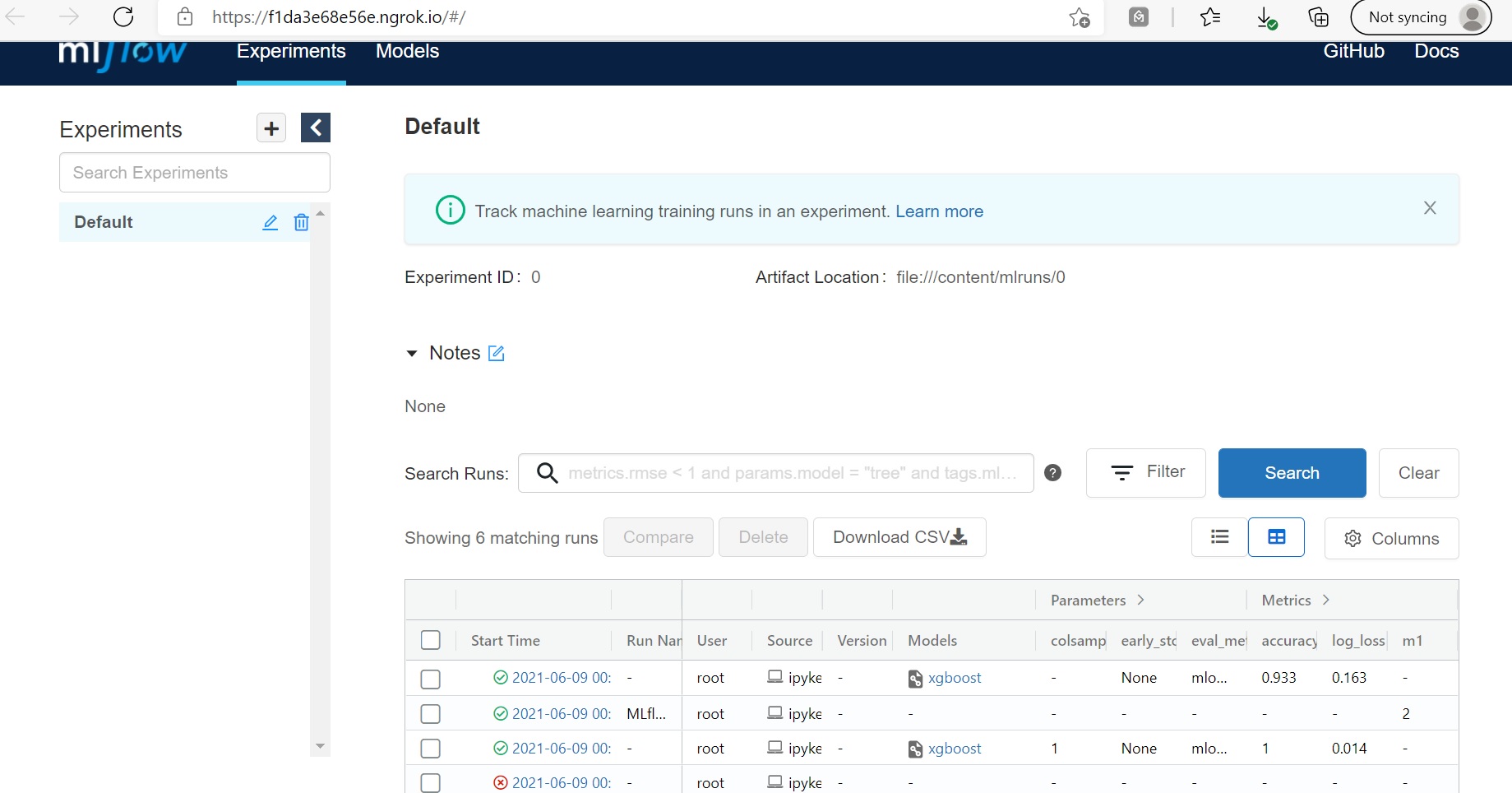
The results for all the experiments are tracked. You can also see the log-loss function below –
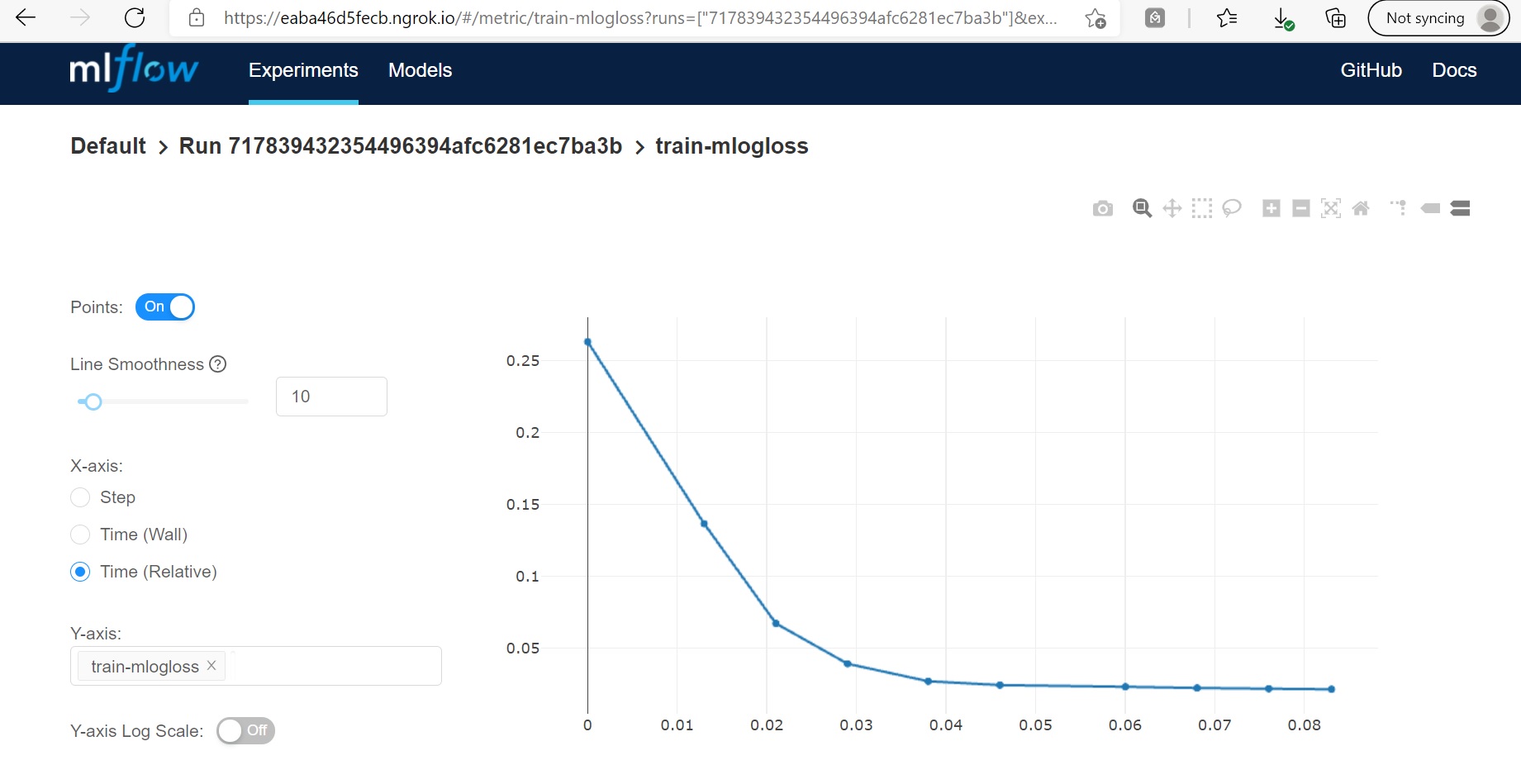
This is just a tiny example of what MLflow has to offer and it’s now for us to make the best use. More concept details and examples here.
Curious to know how better you can use MLflow with Colab to store and track all your models, check here.
BE THE BOSS WITH MLOps – THE TIME IS NOW!
A lot has been already saying and doing with Machine Learning. But practical implementation is what the world has to look for. Though ML & AI are wonderful concepts, using them appropriately involves multiple aspects and also the combined efforts of people with diverse skillsets. Thus managing ML projects in a corporate is never an easy task.
Using MLOps and its various platforms like MLflow are probably the best ways to deal with this issue, just like a boss and even you can make a platform of your own. The MLOps concept is just at its nascent stage and there’s a lot of development expected in the coming days. So it’s high time to keep our eyes and ears open (and being a little nosy with ML).
Frequently Asked Questions
A. MLflow is an open-source platform used for managing the machine learning lifecycle. It enables organizations to track and manage experiments, reproduce models, and deploy them into production. MLflow provides tools for experiment tracking, versioning of models, model packaging, and deployment. It promotes collaboration and reproducibility in machine learning projects, making it easier to manage and scale ML workflows.
A. Yes, Azure Machine Learning (Azure ML) integrates with MLflow. Azure ML provides built-in support for MLflow, allowing users to leverage MLflow’s capabilities within the Azure ML ecosystem. This integration enables seamless experiment tracking, model versioning, and deployment using MLflow’s tools and features, enhancing the machine learning lifecycle management capabilities of Azure ML.
About Author
Hello, this is Jyotisman Rath from Bhubaneswar, and it’s the toughest challenges that always excite me. Currently pursuing my I-MTech in Chemical Engineering, I have a keen interest in the field of Machine Learning, Data Science, and AI and I keep looking for their integration with other disciplines like science, chemistry with my research interests.
Would love to see you on LinkedIn and Instagram. Mail me here for any queries.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.