



{kind=link}
This article was published as a part of the Data Science Blogathon
Overview:
Machine Learning (ML) and data science applications are in high demand. When ML algorithms offer information before it is known, the benefits for business are significant. Integrating machine learning algorithms for inference into production systems is a technological barrier. The ML algorithms, on the other hand, function in two stages:
The training phase is when the machine learning algorithm gets developed with previous data.
The ML method is used to compute predictions on fresh data with uncertain outcomes during the inference phase.
Table of content:
- 1) Introduction.
- 2) Steps involved in training the model.
- 3) Building the Django application.
- 4) Training the Machine Learning model.
- 5) Testing the API.
- 6) About myself.
- 7) Conclusion.
Introduction:
This project aims to make the machine learning algorithm accessible through DJANGO API, RPC, or WebSockets. This technique causes the creation of a server that handles queries and routes them to machine learning algorithms. All criteria for the ML production system may be met using this method.
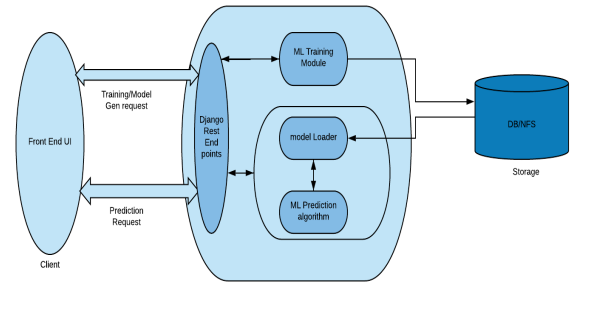
The last progress is to engage a commercial provider to implement machine learning algorithms, which may be done on-premise or in the cloud. This isn’t always the case.
The steps involved in :
- Building the Django application
- Training the Machine Learning model
- Testing the API
Building the Django application
Let’s create and initialize the development environment.
python3 -m venv env source env/bin/activate
Installation of required packages:
pip install django djangorestframework sklearn numpy
Open the command line and type the comments to create and copy the directory where you store your Django projects. Create a directory for this application and copy(cd) it into the directory.
mkdir DjangoMLAPI cd DjangoMLAPI django-admin startproject api
We have created a Django project, which will include all the code we’re working on. It would also contain database configuration and application settings.
While a “project” corresponds to the application we’re developing, Django refers to a package within a project as an “app.” The main package will be API.
The Start Project API creates a large amount of boilerplate code that is needed to run our project. It will resemble the left-hand file tree.
The outer /api folder just includes all of our project’s code.
The main python package for our project is the inner /api.
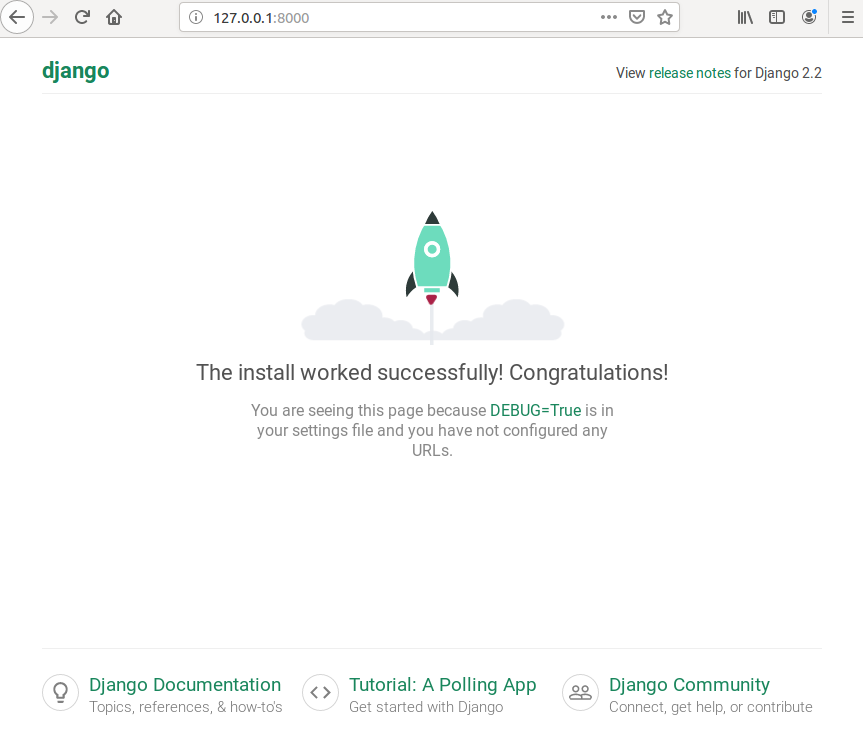
python manage.py runserver
You should see the default Django welcome webpage if you type 127.0.0.1:8000 into your web browser.
After that, we’ll create an “app” within our project. This will spread the machine learning behind the API. We’ll name this soundpredictor.
cd api python manage.py startapp soundpredictor
we added a folder called /soundpredictor with many files inside.
view.py contains the code that can run on every request. As a result, we added vectorization and regression logic to the equation.
apps.py is the file where we’ll specify our config class. This code will only execute once so we’ll ultimately put the code to load our models there
Let’s add this app to APPS_INSTALLED. Open /api/api/settings.py and add ‘soundpredictor’ to APPS_INSTALLED.
APPS_INSTALLED = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'predictor'
]
It’s important to create a folder called /models inside /soundpredictor. Move the trained models into this directory.
Note that in a real production environment, so that we don’t have to re-deploy the app every time the model changes. However, in this case, we’ll just include the model in the app.
We must add these lines to the settings. This code will load the model.
MODELS = os.path.join(BASE_DIR, 'soundpredictor/models')
Write the code that loads our models when the application starts. Inside /api/soundpredictor/apps.py deploy the code. Create a path to models and load models into separate variables.
from django.apps import AppConfig
from django.conf import settings
import os
import pickle
class soundpredictorConfig(AppConfig):
path = os.path.join(settings.MODELS, 'models.p')
with open(path, 'rb') as pickled:
data = pickle.load(pickled)
regressor = data['regressor']
vectorize = data['vectorize']
Now we need to create a view that encourages our regression logic. Open /api/predictor/views.py and let’s update with this code.
from django.shortcuts import render
from .apps import soundpredictorConfig
from django.http import JsonResponse
from rest_framework.views import APIView
class call_model(APIView):
def get(self,request):
if request.method == 'GET':
sound = request.GET.get('sound')
vector = PredictorConfig.vectorizer.transform([sound])
prediction = soundpredictorConfig.regressor.predict(vector)[0]
response = {'dog': prediction}
return JsonResponse(response)
The final step is to add URLs to our models so that we may access them. Please add the following code to the urls.py file in /api/api/urls.py :
from django.urls import path
from predictor import viewsurlpatterns = [
path('classify/', views.call_model.as_view())
]
from django.conf.urls import url, include
from rest_framework.routers import DefaultRouter
urlpatterns = [
url(r"^api/v1/", include(router.urls)),
]
Training the ML model
To start with the project, open a jupyter notebook. Run the command,
pip3 install jupyter notebook
ipython kernel install --user --name=venv
Create a directory to store the notebook files,
mkdir research cd research jupyter notebook
This predictive analysis is to train the model to predict whether the animal is a duck based on its tone.
As a result, we’ll train a model using fictitious data. That stated it will work in the same way as any other sklearn model you may create.
The algorithm will determine whether it is a Duck, based on the sounds that an animal produces.
After creating fictional data, the first index in each inner list is the sound of an animal, and the second index is a boolean label indicating if the animal is a duck.

data = [
['Honk', 1],
['Woof', 0],
['ruff', 0],
['bowwow', 0],
['cackle', 1],
['moo', 0],
['meow', 0],
['clang', 1],
['buzz', 0],
['quack', 0],
['pika', 0]
]
The next task is to convert the above data into lists of features and labels.
X = []
y = []
for i in data:
X.append( i[0] )
y.append( i[1] )
After we convert the features into a list, fit a vectorizer, and transform the features.
from sklearn.feature_extraction.text import CountVectorizer vectorize = CountVectorizer() X_vectorized = vectorize.fit_transform(X)
we are in the final step to train a linear regression model,
from sklearn.linear_model import LinearRegression import numpy as npregressor = LinearRegression() regressor.fit(X_vectorized, y)
we have to test it out on a few examples to check whether the model working correctly,
test_feature = vectorizer.transform(['Honk']) prediction = regressor.predict(test_feature) print(prediction) test_feature = vectorizer.transform(['bowwow']) prediction = regressor.predict(test_feature) print(prediction) test_feature = vectorizer.transform(['meoww']) prediction = regressor.predict(test_feature) print(prediction)
#=> [1.] #=> [0.] #=> [0.36363636]
The model looks perfect.
Pickle our models into a byte stream so that it can store them in the app.
import pickle
pick = {
'vectorize': vectorize,
'regressor': regressor
}
pickle.dump( pick, open( 'models' + ".p", "wb" ) )
Testing the API
We can run the server with the following command:
python manage.py runserver
Add a couple of curl requests to test it out. We can directly input the URLs into the browser address bar.
curl -X GET http://127.0.0.1:8000/classify/?sound=buzz #=> {"duck": 0.0} curl -X GET http://127.0.0.1:8000/classify/?sound=quack #=> {"duck": 1.0}
This model is working! A digit close to 1 indicates it’s a duck and a digit close to 0 indicates it’s not a duck.
We can also check these in the browser. At the URL:
http://127.0.0.1:8000/classify/?sound=buzz
http://127.0.0.1:8000/classify/?sound=quack
A Django API can load and runs a trained machine learning model and the application is tested with a URL.
About Myself:
I’m Lavanya from Chennai. I am a passionate writer and enthusiastic content maker. I am fond of reading books on deep learning. While reading, I came across many fascinating topics in ML and deep learning. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of deep learning. I am seeking forward to your valuable comments and views on my article.
Conclusion:
I hope you enjoyed the article, and I am happy if I hear some opinions about my article from your side, so feel frank to add them up in the comment section. Thank You for reading.
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Computer Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and computer to take further my research goals.