



Machine learning, deep learning, and AI are enabling transformational change in all fields from medicine to music. It is helping businesses from procuring to pay, plan to produce, order to cash and record to report, to uncover optimizing opportunities and support decision making which was never possible earlier with traditional business analytics and information technology.

Machine learning and AI is a complex field and bit daunting for people from my generation who may not have come across computers before undergraduate level education. In this introductory article, I will illustrate a simplified example of machine learning implementation for the supply chain management. In short, we are going to look at the procurement and quality management business processes’ optimization and how machine learning helps improve this part of supply chain management.
I will avoid complex and subtle details in this article and keep the example simple at this point. We will discuss complex scenarios in the next series in this article. I will be using the programming language Python to implement machine learning algorithms to solve supply chain business challenges in this series, and I am assuming that you have some basic understanding of Python language.
Business Case
A vendor supplies different materials with wide unit prices and total purchase order values. Sometimes a few parts from suppliers fail to pass the quality checks, but the defect percentage doesn’t seem to be following a trend.
Objective
The business would like to predict the defective piece percentage in delivery from the supplier. If the defective piece percentage predicted is below the threshold level, then a quality check will not be performed. Let us consider that if the defect piece percentage in the delivery is more than 0.4%, then explicit incoming inspection is needed to ensure the quality of the end product.
This will help to focus on quality checks on only particular purchase orders delivery, to control the end-product quality, and optimize inspection costs. It will also enable us to uncover the variables/parameters which are influencing the defective deliveries of few materials at times and work collaboratively with the supplier to address it.
Data Points and Information
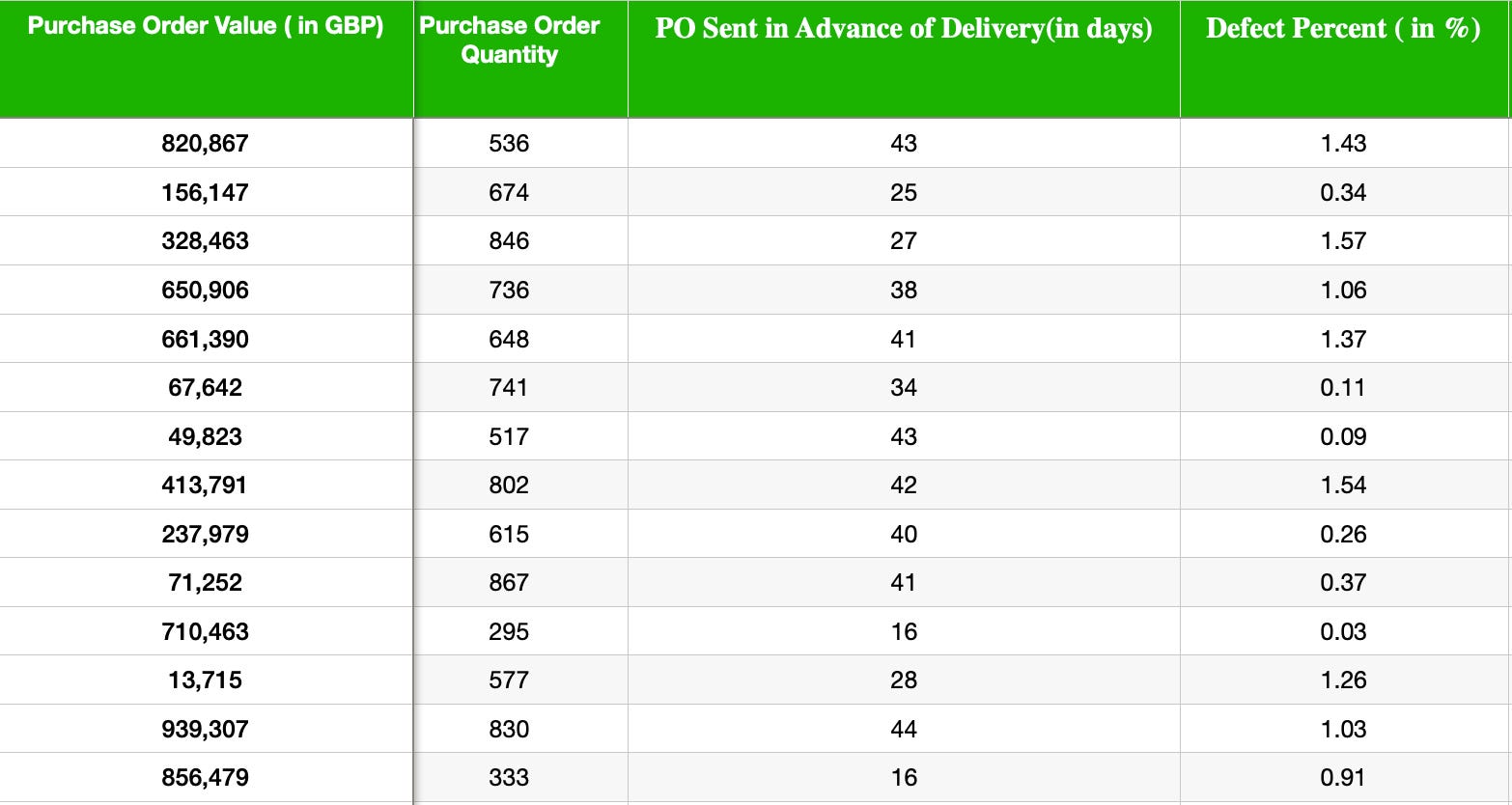
Purchase orders information and respective incoming inspection results in the ERP provided the data points for all the orders over three years period.

Getting Ready
For the sake of simplicity, I assume that we exported the past data points from ERP and save in the local machine in excel format.
I will explain each line of the code and then put the full code at the end of the article for reference. As mentioned earlier, I have oversimplified a few things here for us to understand the core concept, and in future series, I will build more real-life complex examples on it.
-
Step 1
First, we will import all the python modules which we will be using in our machine learning program. I will not go in detail about these libraries and modules here in this article, and you can find more details about these modules online.
import pandas as pd from sklearn.tree import DecisionTreeRegressor # Import Decision Tree Algorithm from sklearn.preprocessing import StandardScaler from sklearn.svm import SVR #import for support vector regressorPandas is a software library written in Python for data manipulation and analysis. It is very easy to read and write data in excel, CSV, and other file formats using Pandas, and work with time-series data.
Scikit-learn is a free machine learning library for python. We will be predicting the defect percentage in the future supplier delivery using Decision Tree Learning and Support Vector Machine. We will import specifically these two modules from Scikit Learn for the same.
-
Step 2
Then, we will read the past data points in an excel file and save it to pandas dataframe SourceData. Similarly, we will read the data points of the delivery for which we want the algorithm to predict the delivery defect percentage.
SourceData=pd.read_excel("Supplier Past Performance.xlsx") # Load the training data into Pandas DataFrameTestdata=pd.read_excel("Defect Predict.xlsx") # Load the test data
Note — I have saved the python program, past data point excel sheet, and the future data set in the same folder. Hence, in the code, only the file names are specified. In case, files are located in different folder locations then full paths need to be provided.
-
Step 3
Now all four data points from past viz. Purchase Order Amount, Purchase Order Quantity, PO Sent in Advance of Delivery, and Defect Percent to be read from excel into Pandas Dataframe.
We will use the Purchase Order Amount, Purchase Order Quantity, PO Sent in Advance of Delivery(in days) to predict the Defect Percent in future deliveries. Independent variables are the parameters used for making the prediction, and the dependent variable is the variable predicted. As we will be using the past data point collected from ERP to train the machine learning algorithm, hence we will be calling it as SourceData_train_independent and SourceData_train_dependent variable.
In the below code, we have declared all the columns data except “Defect Percent” as the independent variable and only “Defect Percent” as the dependent variable.
SourceData_train_independent= SourceData.drop(["Defect Percent"], axis=1) # Drop depedent variable from training datasetSourceData_train_dependent=SourceData["Defect Percent"].copy() # New dataframe with only independent variable value for training dataset
-
Step 4
The purchase order value ranges from one thousand to one million GBP, whereas the order quantity varies from a hundred to one thousand pallets. Purchase Orders are sent fifteen to forty-five days in advance of the delivery date. As the independent variable ranges are quite disparate, hence we need to scale it to avoid the unintended influence of one variable, Purchase order value in this case, over other factors.
We only need to scale the independent variables.
In the code below we scale the independent train and test variable and name them X-train and X_test respectively. In y_train, we save the dependent trained variable without scaling.
sc_X = StandardScaler() X_train=sc_X.fit_transform(SourceData_train_independent.values) # scale the independent training datasetvariablesX_test=sc_X.transform(Testdata.values) # scale the independent test datasety_train=SourceData_train_dependent # scaling is not required for dependent variable
-
Step 5
Then we will feed the independent and dependent train data i.e. X_train and y_train respectively to train the Support Vector Machine model. To avoid confusion, I will not discuss intricate details like the setting of the algorithms (hyperparameters) in this first series.
In the below code first, we fit the X_train and y_train with a fit method. Then we pass the test independent variable values i.e “PO Amount”, “PO Qty” and “PO Sent in Advance of Delivery” of a new order with the X_test variable. Then store the predicted defect percentage in the variable “predictions”.
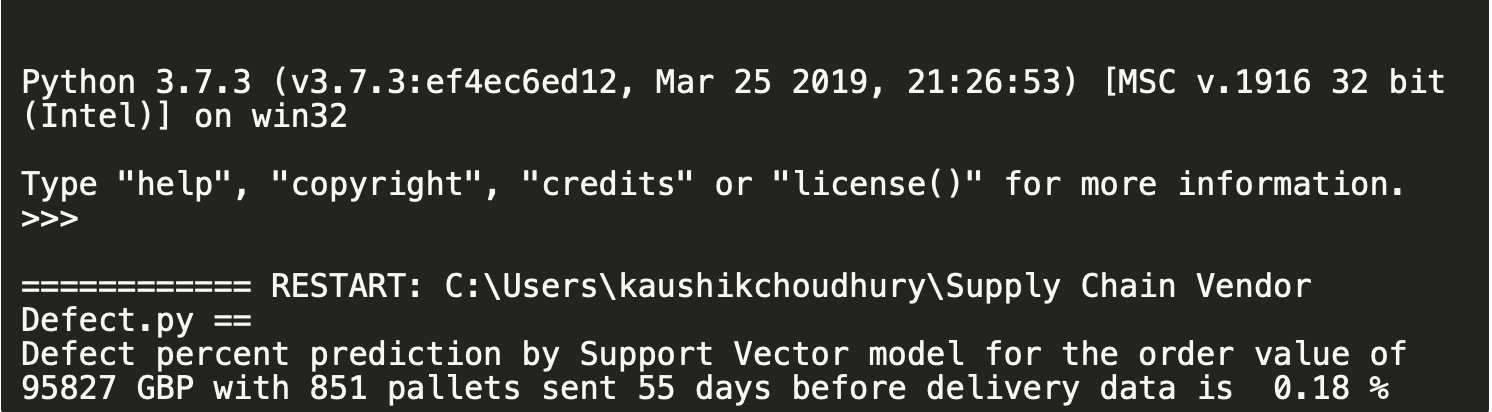
svm_reg = SVR(kernel="linear", C=1) svm_reg.fit(X_train, y_train) # fit and train the modelpredictions = svm_reg.predict(X_test) print("Defect percent prediction by Support Vector model for the order value of 95827 GBP with 851 pallets sent 55 days before delivery data is " ,round(predictions[0],2) , "%")
Finally, we print the predicted defect percentage.

-
Step 6
In the same way, we will feed the training dataset (independent and dependent variable value) to the Decision Tree model.
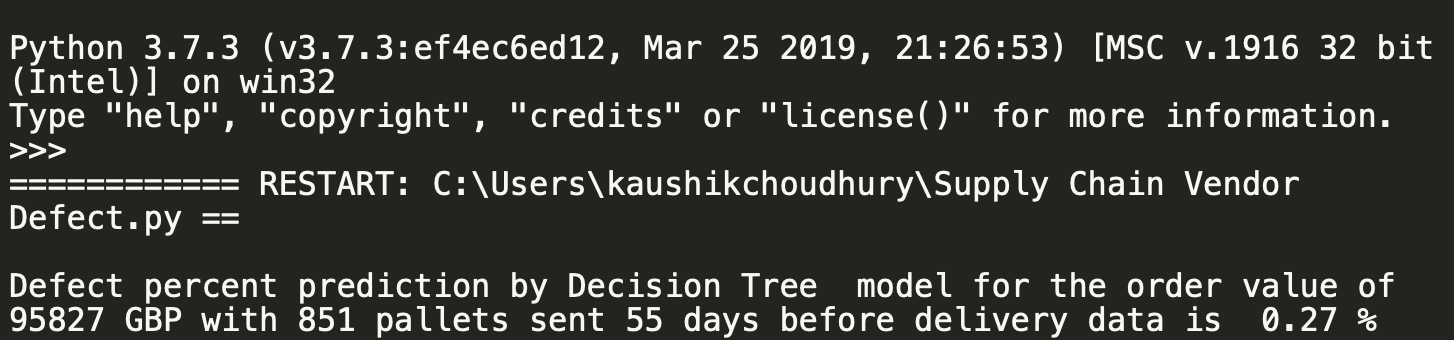
tree_reg = DecisionTreeRegressor() tree_reg.fit(X_train, y_train) # fit and train the modeldecision_predictions = tree_reg.predict(X_test) # Predict the value of dependent variableprint("Defect percent prediction by Decision Tree model for the order value of 95827 GBP with 851 pallets sent 55 days before delivery data is " ,round(decision_predictions[0],2) , "%")
Print the predicted defect percent using the print statement.

We learn how to use the Decision Tree Learning and Support Vector Model algorithm to predict the defect percentage quantity in future deliveries and based on its quality plan the inspection for specific vendor deliveries. Please note that I have simplified a few elements from real-life use cases to build the initial understanding.
{kind=link}
To summarize, in this example, we are training the model every time we are running the code to predict the result for new orders. This may not be practicable for large datasets and complex examples. And this is how we leverage machine learning in supply chain management.
Full Code
""" Step 1 - Import the required modules""" import pandas as pd from sklearn.tree import DecisionTreeRegressor from sklearn.preprocessing import StandardScaler from sklearn.svm import SVR """ Step 2 - Read the data source""" SourceData=pd.read_excel("Supplier Past Performance.xlsx") # Load the training data into Pandas DataFrame Testdata=pd.read_excel("Defect Predict.xlsx") # Load the test data """ Step 3 - Declare the independent and dependent train data from the sample""" SourceData_train_independent= SourceData.drop(["Defect Percent"], axis=1) # Drop depedent variable from training dataset SourceData_train_dependent=SourceData["Defect Percent"].copy() # New dataframe with only independent variable value for training dataset """ Step 4 - Scale the independent test and train data""" sc_X = StandardScaler() X_train=sc_X.fit_transform(SourceData_train_independent.values) # scale the independent variables y_train=SourceData_train_dependent # scaling is not required for dependent variable X_test=sc_X.transform(Testdata.values) """ Step 5 - Fit the test data in maching learning model - Support Vector Regressor""" svm_reg = SVR(kernel="linear", C=1) svm_reg.fit(X_train, y_train) # fit and train the modelpredictions = svm_reg.predict(X_test) print("Defect percent prediction by Support Vector model for the order value of 95827 GBP with 851 pallets sent 55 days before delivery data is " ,round(predictions[0],2) , "%") """ Step 6 - Fit the test data in maching learning model - Decision Tree Model""" tree_reg = DecisionTreeRegressor() tree_reg.fit(X_train, y_train) # fit and train the modeldecision_predictions = tree_reg.predict(X_test) # Predict the value of dependent variableprint("Defect percent prediction by Decision Tree model for the order value of 95827 GBP with 851 pallets sent 55 days before delivery data is " ,round(decision_predictions[0],2) , "%")
About the Author

Kaushik Choudhury – Senior Solution Design Architect