



This article was published as a part of the Data Science Blogathon
Introduction
Hello all, In this tutorial, we will cover some Intermediate statistics terms which are very helpful in exploratory data analysis, feature engineering tasks. If you are a beginner, I would like to request you to please look at our previous article Basic Statistics concepts for Machine Learning, which will familiarize you with statistics, its importance, and some basic terms required to understand these intermediate terms.

Table of Contents
- Z-Score in statistics
- Confidence Interval
- Hypothesis Testing
- Type-I and Type-II Error
- Different test for Hypothesis
- Covariance
- Correlation
- Pearson Correlation Coefficient
- Spearman rank correlation coefficient
- Conclusion
1) Z-Score
Z-score is a measure that describes a relationship of a particular value with the mean of a group of values. It is measured in terms of standard deviation from the mean. it is computed using the below formula.
z = (x – μ) / σ
Applications of using Z-score
- Z-score will help us to know how much standard deviation far a value is from the mean.
- Z-score is used in Standardization – we can scale down the values in feature towards mean using z-score.
- Compare scores between different distributions – we can also use a z-score to compare two distributions and tell that which one is better. for example, suppose Indian-England test series data of past 2 years. we are given an average score, maximum score, and standard deviation, and based on this we want to find in which year India played more powerful. we can use a z-score to solve this type of problem. have a look at the below figure and you will see how we use a z-score to do so.

calculate Z-score using Python
Python Code:
2) Confidence Interval
Confidence Interval is a probability that a population parameter will fall between a certain range for a certain proportion of times. In simple words, confidence interval tells the percentage confidence of certain events happening in a particular range. It is one of the important measures in data analysis for proving our assumptions true
CI = point estimate ± Margin of an error
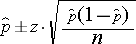
where the margin of error is basically a standard deviation and point estimate is mean. for calculating confidence interval we calculate point estimate, for example, we need to find 95 per cent confidence so we will assume point estimate as 95 and try to find the quantity of data lie between which range.
How to Compute Confidence Interval using Python
import scipy.stats as stat
np.random.seed(10)
data = np.random.randint(10, 30, 50)
#create 95% confidence interval for population mean weight
conf_interval = stat.norm.interval(alpha=0.95, loc=np.mean(data), scale=stat.sem(data))
print(conf_interval)
The 95 per cent Confidence interval for the true population mean is (18.93, 22.10)
3) Hypothesis Testing
A hypothesis in simple words is an assumption or a guess about something in a world around you. So results can be 2 things like either your guess is correct or incorrect. In data science terms we refer to hypothesis testing as where We try to evaluate 2 mutually exclusive statements on a population using a sample of data.
Steps of Hypothesis testing
- make initial assumptions – The initial assumption you make is known as the Null Hypothesis with is denoted with H0, which is always assumed as true before the experiment. And in opposite to it, we have an Alternate Hypothesis denoted by H1.
- Collect data – To prove your assumptions correct we collect some data related to it or we can say as we collect evidence to prove our statement correct. while working with the Machine learning problem statements we are having data, we try to find some patterns from it as evidence.
Type-I Error and Type-II Error
When we know the actual outcome that the Null Hypothesis is True but due to lack of evidence we failed to prove it and we have to reject it and select an Alternate hypothesis is known as Type-1 error. And in the opposite of it, the same applies to Type-II error, when we have cannot reject the Null hypothesis, there Type-II error is achieved. You can understand it in a better way in form of Confusion Matrix.
Different tests to perform Hypothesis testing
I) P-Value Test
P-value is the probability of obtaining results at least as extreme as observed results for the Hypothesis test assuming the Null hypothesis as correct and is performed by knowing the distribution of data. The P-value is also known as significance level and also denoted as alpha. the default value assumed is 5 per cent or 0.05. when P-value is less than 5 per cent, it means we do not have enough evidence to prove the NULL hypothesis as correct and have to reject it. P-value is usually found using a P-value table also known as a z-table.
If we have 2 categorical variables then we use the chi-square test.
II) Chi-Square Test
Chi-square is a very good way to show a relationship between 2 categorical features. Chi-square is a measure that basically tells a difference that exists between your observed counts and the count you would expect if there would no relationship between 2 variables in the population.
Compute P-value for Chi-Square test using Python
stat.chi2.pdf(3.84, 1)
we apply the chi-square transformation and calculated the probability density function which in turn gives P-value.
III) T-test
When we assume continuous feature for Hypothesis testing then the type of test we use is T-test. T-test tells the significant difference between the mean of two groups which may or may not be related to a label. In simple words, the t-test helps us in comparing an average of 2 groups and determine that if they came from the same population or not.
For calculating T-value we require 3 data values. It includes differences between mean values, standard deviation, and several observations.
If we want to perform a test on a more continuous feature then we go with Correlation which we will study in the further part of the article.
4) Covariance
Covariance is one of the very important topics when we consider data preprocessing in order. Quantifying the relationship between two random variables is known as Covariance. It is similar to variance, where variance tells how a single variable varies from the mean, covariance helps to know how two variables vary together. Covariance does not represent strength between two variable and only indicate the direction of the linear relationship between them.
Cov(x,y) = SUM [(xi – xm) * (yi – ym)] / (n – 1)
- xi is a given x value in the data set
- xm is the mean, or average, of the x values
- Yi is the y value in the data set that corresponds with xi
- ym is the mean, or average, of the y values
- n is the number of data points
Covariance is an important term that will help you in the data analysis step and also it is used by many machine learning algorithms like Linear Regression.
Compute covariance using Python.
arr = np.array([[2,6,8],[1,5,7],[3,6,9]])
print("covariance: ", np.cov(arr))
5) Correlation
Correlation is a measure used to represent how strongly 2 variables relate to each other. Correlation is the scaled form of covariance. correlation ranges between -1 to +1. If the value of correlation is near +1, it means two variables are highly positively correlated. And in the opposite, its value is near -1 which means two variables are negatively correlated. It basically measures the strength and direction of a linear relationship between two variables.
- Strength – if I have 2 variables as X and Y, then if X increases then do Y increase or decrease, this is only a strength that correlation tells us.
- The direction of relationship – It means whether the relationship is in a positive or negative direction.
We also use correlation in feature selection and to avoid multicollinearity in data. There are different ways to calculate the correlation coefficient between two variables.
I) Pearson Correlation Coefficient
It is the most used technique to find correlation coefficients. Pearson Correlation coefficient is the covariance of two variables divided by-product of their standard deviation. Its range is between -1 to +1 and It is represented by ρ (rho).
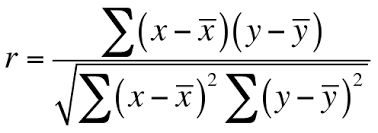
- When there is the perfect linear relationship then the value of the Pearson correlation coefficient will be +1(When x increases, Y also increases).
- When X(independent variable) is increasing, Y(dependent variable) is decreasing then the value will be -1.
- When there is a non-linear relationship or a constant line at 0 then the value is 0.
we can directly use the corr method of pandas dataframe to find the Pearson correlation coefficient.
df.corr()
II) Spearman rank Correlation Coefficient
It is a little bit different in both methods. In Spearman rank correlation we trying to find the Pearson correlation of rank of x and rank of y. now, what is the rank of X and Y?

{kind=link}
Steps to compute Spearman Correlation coefficient is,
- Sort the data by the first column(Xi), and create a new column and assign it ranked values from 1,2,3,…n.
- Now sort the data by second column(Yi). Create another column and rank it.
- Create a new column difference(Di) that holds a difference between two rank columns.
- Finally, create a new column that holds a squared value of the difference column.
Now you have all the values, substitute values to the equation and you will get a correlation coefficient.
Conclusion
We have covered some of the important statistical concepts which are used in feature engineering, data analysis. I hope that it was easy for you to cope up with every concept. If you have any doubt then please drop it in the comment box below. At this point, our basic and intermediate statistics are completed, and Now in an upcoming article, we will discuss some advanced statistics terms which are mostly used and asked in interviews.
keep learning, happy learning
About the Author
Raghav Agrawal
I am pursuing my bachelor’s in computer science. I am very fond of Data science and big data. I love to work with data and learn new technologies. Please feel free to connect with me on Linkedin.
If you like my article, please give it a read to others too. link
I am a final year undergraduate who loves to learn and write about technology. I am a passionate learner, and a data science enthusiast. I am learning and working in data science field from past 2 years, and aspire to grow as Big data architect.