



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Artificial Intelligence is a forever emerging and advancing technology. Artificial intelligence models are used increasingly widely in today’s world. With the power of data and artificial intelligence, machines are able to demonstrate human intelligence, sometimes even better than humans!
The culmination of data with machine learning has undoubtedly created huge longevity and thrilling material progress in technology, thus achieving inconceivable heights of intelligence.
One such recent yet dramatic progress in Machine Learning is a newly revoluted concept known as Federated Learning.
Federated Learning — a Decentralized Form of Machine Learning
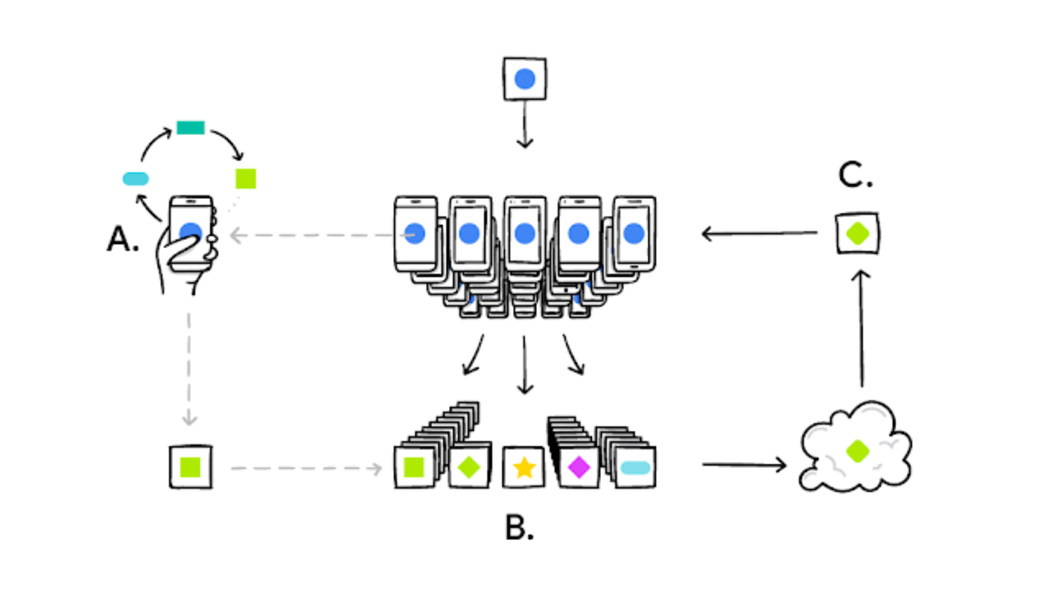
Source-Google AI
Table of contents
A user’s phone personalizes the model copy locally, based on their user choices (A). A subset of user updates are then aggregated (B) to form a consensus change (C) to the shared model. This process is then repeated.
Federated Learning trains central models on decentralized data. They are hyper-personalized for a user, involve minimum latencies, and are privacy preserved. This article is a beginner level primer for Federated Learning.
What is Federated Learning?
Federated Learning is simply the decentralized form of Machine Learning.
In Machine Learning, we usually train our data that is aggregated from several edge devices like mobile phones, laptops, etc. and is brought together to a centralized server. Machine Learning algorithms, then grab this data and trains itself and finally predicts results for new data generated.
Great!
But, can you smell a “privacy nightmare”?
The AI market is dominated by tech giants such as Google, Amazon and Microsoft, offering cloud-based AI solutions and APIs. In the traditional AI methods, sensitive user data are sent to the servers where models are trained.
That’s awful! With the increased awareness of user privacy across different devices and platforms, AI developers should not ignore the fact that their model is accessing and using data that is user-sensitive!
Well, here comes our Savior! The Federated Learning approach.
Types of federated learning
There are mainly three types of federated learning:
Horizontal Federated Learning: Data samples are distributed across devices or servers, and the model is trained collaboratively.
Vertical Federated Learning: Features are divided between devices, and the model is trained on complementary features.
Federated Transfer Learning: Pre-trained models are fine-tuned on decentralized data for specific tasks, reducing the need for extensive local data.
Welcome to the world of Federated Learning!

Federated Learning is born at the intersection of on-device AI, blockchain, and edge computing/IoT.
Here we train a centralized Machine Learning model on decentralized data! Let us take a hypothetical problem statement, and understand how federated learning works, step by step.
So, grab your coffee mug and dive in!
Suppose, you got selected as a machine learning intern in a company, and your task is to create a robust machine learning application, that needs to train itself on user-sensitive data.
You’re allowed to extract user data, aggregate it from many users, and stack them up on a centralized cloud server, for your model to crunch it. You are a smart guy, and you are doing your job!
But wait. Isn’t your work invading someone’s privacy?
Yes, it is. And that is not an ethical practice in technology.
You discussed it in a meeting, and your boss is now worried about the next steps. In the meantime, you and your teammates started discussing the matter.
One of them yelled, “What if we don’t take user-sensitive data, but train our model locally, on each device?”
That was a good idea. But how can we do this?
We will train our model on the devices themselves, and not on the centralized server, that exposes sensitive data! The local data generated by the user history, on a particular device, will now be used as on-device data to train our model and make it smarter, much quicker.
Yay! No more privacy nightmares.
Let us sum up the plan now!
1. So, our centralized machine learning application will have a local copy on all devices, where users can use them according to our need.
2. The model will now gradually learn and train itself on the information inputted by the user and become smarter, time to time.
3. The devices are then allowed to transfer the training results, from the local copy of the machine learning app, back to the central server.
Remember, only results, not data!
4. This same process happens across several devices, that have a local copy of the application. The results will be aggregated together in the centralized server, this time without user data.
5. The centralized cloud server now updates its central machine learning model from the aggregated training results, which is now far better than the previously deployed version.
6. The development team now updates the model to a newer version, and users update the application with the smarter model, created from their own data!
WOW! That’s pretty awesome!
All is going pretty good, while one of your teammates seems to be very worried about the device battery power issue! 😐
She points, “Such long and costly training would always drain our phone battery, guys!”
So, do we have a solution to this? Yes, of course, we do!
Don’t worry. Devices will only participate in the training process when users are not using it. This can occur while your phone is on the charge, in do not disturb mode, or idle.
Cool. That’s a lot of awesomeness.
So, what did we learn about Federated Learning?

In a nutshell, Federated Learning with the above 6 steps discussed, will now create a system that encrypts the user-sensitive data with an encryption key that is not in the hands of your centralized cloud server.
Such an approach is referred to as the Secure Aggregation Principle, where our server is allowed to secure and combine the encrypted results and decrypt only the aggregated results.
This kind of functional encryption is simply said to be a zero-sum masking protocol. Zero-sum masks sum to 1 in one direction, and 0 in another. One of them combines and secures the encrypted or secure user data, while the next decrypts the training results to the server.
This process continues until completed, and then the masks cancel out each other.
That is all about Federated Learning!
Federated learning works?
Federated learning works by training a central model across decentralized devices or servers. Instead of moving all data to a central location, the model is trained locally on each device, and only the model updates are shared. This maintains privacy and allows collaborative learning without sharing raw data.
Hands-on with Federated Learning with Keras and TensorFlow
Before we start, please make sure that your environment is correctly set up and import all the dependencies.
!pip uninstall --yes tensorboard tb-nightly
!pip install --quiet --upgrade tensorflow-federated-nightly
!pip install --quiet --upgrade nest-asyncio
!pip install --quiet --upgrade tb-nightly # or tensorboard, but not both
import nest_asyncio
nest_asyncio.apply()
import collections
import numpy as np
import tensorflow as tf
import tensorflow_federated as tff
np.random.seed(0)
Now, we will load and preprocess our data. We will use the federated version of MNIST data.
def preprocess(dataset):
def batch_format_fn(element):
return collections.OrderedDict(
x=tf.reshape(element['pixels'], [-1, 784]),
y=tf.reshape(element['label'], [-1, 1]))
return dataset.repeat(NUM_EPOCHS).shuffle(SHUFFLE_BUFFER).batch(
BATCH_SIZE).map(batch_format_fn).prefetch(PREFETCH_BUFFER)
def make_federated_data(client_data, client_ids):
return [
preprocess(client_data.create_tf_dataset_for_client(x))
for x in client_ids
]
sample_clients = emnist_train.client_ids[0:NUM_CLIENTS]
federated_train_data = make_federated_data(emnist_train, sample_clients)
print('Number of client datasets: {l}'.format(l=len(federated_train_data)))
print('First dataset: {d}'.format(d=federated_train_data[0]))We preprocessed the data and sample the set of clients once, and reuse the same set across rounds to speed up convergence. In the next step, we will create our model.
def create_keras_model():
return tf.keras.models.Sequential([
tf.keras.layers.InputLayer(input_shape=(784,)),
tf.keras.layers.Dense(10, kernel_initializer='zeros'),
tf.keras.layers.Softmax(),
])
def model_fn():
keras_model = create_keras_model()
return tff.learning.from_keras_model(
keras_model,
input_spec=preprocessed_example_dataset.element_spec,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])Now it’s time to train our model on decentralized or user data.
state, metrics = iterative_process.next(state, federated_train_data)
print('round 1, metrics={}'.format(metrics))
NUM_ROUNDS = 11
for round_num in range(2, NUM_ROUNDS):
state, metrics = iterative_process.next(state, federated_train_data)
print('round {:2d}, metrics={}'.format(round_num, metrics))This step will complete your model training on client or user data. Finally, we will see how we can evaluate and test the model.
evaluation = tff.learning.build_federated_evaluation(MnistModel)
train_metrics = evaluation(state.model, federated_train_data)
federated_test_data = make_federated_data(emnist_test, sample_clients)
test_metrics = evaluation(state.model, federated_test_data)So, this is how you can train your centralized machine learning model on decentralized or user-sensitive data!
Conclusion
Federated Learning seems to have a lot of potentials. Not only it secures user sensitive information, but also aggregates results and identifies common patterns from a lot of users, which makes the model robust, day by day.
It trains itself as per its user data, keeps it secure, and then comes back as a smarter guy, which is again ready to test itself from its own user! Training and testing became smarter!
Be it training, testing, or information privacy, Federated Learning created a new era of secured AI.
Federated Learning is still in its early stages and faces numerous challenges with its design and deployment. A good way to tackle this challenge is by defining the Federated Learning problem and designing a data pipeline such that it can be properly productionized.
You can run a TensorFlow tutorial of Federated Learning here to get your hands-on!
Frequently Asked Questions
TensorFlow is the primary framework for federated learning
It’s a method where a central model is trained on decentralized data, with TensorFlow enabling this collaborative approach.
Applied in healthcare, finance, smart devices, and IoT for secure and privacy-preserving model training on distributed data.
References –
1. Federated Learning: Strategies for Improving Communication Efficiency — Google Research
2. Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications -ResearchGate
3. TensorFlow Federated Tutorials!
For further discussions, reach me out via LinkedIn and Medium.
Happy Machine Learning! 🤖
The media shown in this article on Top Machine Learning Libraries in Julia are not owned by Analytics Vidhya and is used at the Author’s discretion.