



{kind=link}
Introduction
Before the large language models era, extracting invoices was a tedious task. For invoice extraction, one has to gather data, build a document search machine learning model, model fine-tuning etc. The introduction of Generative AI took all of us by storm and many things were simplified using the LLM model. The large language model has removed the model-building process of machine learning; you just needs to be good at prompt engineering, and your work is done in most of the scenario. In this article, we are making an invoice extraction bot with the help of a large language model and LangChain.
Learning Objectives
- Learn how to extract information from a document
- How to structure your backend code by using LangChain and LLM
- How to provide the right prompts and instructions to the LLM model
- Good knowledge of Streamlit framework for front-end work
This article was published as a part of the Data Science Blogathon.
Table of contents
- What is a Large Language Model?
- What is LangChain?
- Building Invoice Extraction Bot using LangChain and LLM
- Step 1: Create an OpenAI API Key
- Step 2: Importing Libraries
- Step 3: Create a Function to Extract Information from a PDF File
- Step 4: Create a Function to Extract Required Data
- Step 5: Create a Function that will Iterate through all the PDF Files
- Streamlit Framework
- Conclusion
- Frequently Asked Question
What is a Large Language Model?
Large language models (LLMs) are a type of artificial intelligence (AI) algorithm that uses deep learning techniques to process and understand natural language. LLMs are trained on enormous volumes of text data to discover linguistic patterns and entity relationships. Thanks to this, they can now recognize, translate, forecast, or create text or other information. LLMs can be trained on possible petabytes of data and can be tens of terabytes in size. For instance, one gigabit of text space may hold around 178 million words.
For businesses wishing to offer customer support via a chatbot or virtual assistant, LLMs can be helpful. Without a human present, they can offer individualized responses.
What is LangChain?
LangChain is an open-source framework used for creating and building applications using a large language model (LLM). It provides a standard interface for chains, many integrations with other tools, and end-to-end chains for common applications. This enables you to develop interactive, data-responsive apps that use the most recent advances in natural language processing.

Core Components of LangChain
A variety of Langchain’s components can be “chained” together to build complex LLM-based applications. These elements consist of:
- Prompt Templates
- LLMs
- Agents
- Memory
Building Invoice Extraction Bot using LangChain and LLM
Before the era of Generative AI extracting any data from a document was a time-consuming process. One has to build an ML model or use the cloud service API from Google, Microsoft and AWS. But LLM makes it very easy to extract any information from a given document. LLM does it in three simple steps:
- Call the LLM model API
- Proper prompt needs to be given
- Information needs to be extracted from a document
For this demo, we have taken three invoice pdf files. Below is the screenshot of one invoice file.

Step 1: Create an OpenAI API Key
First, you have to create an OpenAI API key (paid subscription). One can find easily on the internet, how to create an OpenAI API key. Assuming the API key is created. The next step is to install all the necessary packages such as LangChain, OpenAI, pypdf, etc.
#installing packages
pip install langchain
pip install openai
pip install streamlit
pip install PyPDF2
pip install pandasStep 2: Importing Libraries
Once all the packages are installed. It’s time to import them one by one. We will create two Python files. One contains all the backend logic (named “utils.py”), and the second one is for creating the front end with the help of the streamlit package.
First, we will start with “utils.py” where we will create a few functions.
#import libraries
from langchain.llms import OpenAI
from pypdf import PdfReader
import pandas as pd
import re
from langchain.llms.openai import OpenAI
from langchain.prompts import PromptTemplateStep 3: Create a Function to Extract Information from a PDF File
Let’s create a function which extracts all the information from a PDF file. For this, we will use the PdfReader package:
#Extract Information from PDF file
def get_pdf_text(pdf_doc):
text = ""
pdf_reader = PdfReader(pdf_doc)
for page in pdf_reader.pages:
text += page.extract_text()
return textStep 4: Create a Function to Extract Required Data
Then, we will create a function to extract all the required information from an invoice PDF file. In this case, we are extracting Invoice No., Description, Quantity, Date, Unit Price, Amount, Total, Email, Phone Number, and Address and calling OpenAI LLM API from LangChain.
def extract_data(pages_data):
template = '''Extract all following values: invoice no., Description,
Quantity, date, Unit price, Amount, Total,
email, phone number and address from this data: {pages}
Expected output : remove any dollar symbols {{'Invoice no.':'1001329',
'Description':'Office Chair', 'Quantity':'2', 'Date':'05/01/2022',
'Unit price':'1100.00', Amount':'2200.00', 'Total':'2200.00',
'email':'[email protected]', 'phone number':'9999999999',
'Address':'Mumbai, India'}}
'''
prompt_template = PromptTemplate(input_variables=['pages'], template=template)
llm = OpenAI(temperature=0.4)
full_response = llm(prompt_template.format(pages=pages_data))
return full_response
Step 5: Create a Function that will Iterate through all the PDF Files
Writing one last function for the utils.py file. This function will iterate through all the PDF files which means you can upload multiple invoice files at one go.
# iterate over files in
# that user uploaded PDF files, one by one
def create_docs(user_pdf_list):
df = pd.DataFrame({'Invoice no.': pd.Series(dtype='str'),
'Description': pd.Series(dtype='str'),
'Quantity': pd.Series(dtype='str'),
'Date': pd.Series(dtype='str'),
'Unit price': pd.Series(dtype='str'),
'Amount': pd.Series(dtype='int'),
'Total': pd.Series(dtype='str'),
'Email': pd.Series(dtype='str'),
'Phone number': pd.Series(dtype='str'),
'Address': pd.Series(dtype='str')
})
for filename in user_pdf_list:
print(filename)
raw_data=get_pdf_text(filename)
#print(raw_data)
#print("extracted raw data")
llm_extracted_data=extracted_data(raw_data)
#print("llm extracted data")
#Adding items to our list - Adding data & its metadata
pattern = r'{(.+)}'
match = re.search(pattern, llm_extracted_data, re.DOTALL)
if match:
extracted_text = match.group(1)
# Converting the extracted text to a dictionary
data_dict = eval('{' + extracted_text + '}')
print(data_dict)
else:
print("No match found.")
df=df.append([data_dict], ignore_index=True)
print("********************DONE***************")
#df=df.append(save_to_dataframe(llm_extracted_data), ignore_index=True)
df.head()
return dfTill here our utils.py file is completed, Now it is time to start with the app.py file. The app.py file contains front-end code with the help of the streamlit package.
Streamlit Framework
An open-source Python app framework called Streamlit makes it easier to build web applications for data science and machine learning. You can construct apps using this system in the same way as you write Python code because it was created for machine learning engineers. Major Python libraries including scikit-learn, Keras, PyTorch, SymPy(latex), NumPy, pandas, and Matplotlib are compatible with Streamlit. Running pip will get you started with Streamlit in less than a minute.
Install and Import all Packages
First, we will install and import all the necessary packages
#importing packages
import streamlit as st
import os
from dotenv import load_dotenv
from utils import *Create the Main Function
Then we will create a main function where we will mention all the titles, subheaders and front-end UI with the help of streamlit. Believe me, with streamlit, it is very simple and easy.
def main():
load_dotenv()
st.set_page_config(page_title="Invoice Extraction Bot")
st.title("Invoice Extraction Bot...💁 ")
st.subheader("I can help you in extracting invoice data")
# Upload the Invoices (pdf files)
pdf = st.file_uploader("Upload invoices here, only PDF files allowed",
type=["pdf"],accept_multiple_files=True)
submit=st.button("Extract Data")
if submit:
with st.spinner('Wait for it...'):
df=create_docs(pdf)
st.write(df.head())
data_as_csv= df.to_csv(index=False).encode("utf-8")
st.download_button(
"Download data as CSV",
data_as_csv,
"benchmark-tools.csv",
"text/csv",
key="download-tools-csv",
)
st.success("Hope I was able to save your time❤️")
#Invoking main function
if __name__ == '__main__':
main()Run streamlit run app.py
Once that is done, save the files and run the “streamlit run app.py” command in the terminal. Remember by default streamlit uses port 8501. You can also download the extracted information in an Excel file. The download option is given in the UI.
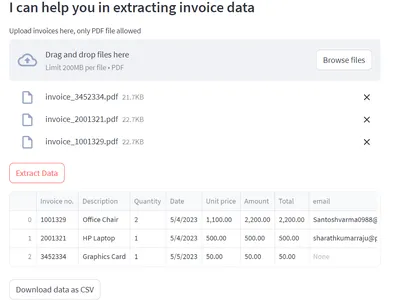
Conclusion
Congratulations! You have built an amazing and time-saving app using a large language model and streamlit. In this article, we have learned what a large language model is and how it is useful. In addition, we have learned the basics of LangChain and its core components and some functionalities of the streamlit framework. The most important part of this blog is the “extract_data” function (from the code session), which explains how to give proper prompts and instructions to the LLM model.
You have also learned the following:
- How to extract information from an invoice PDF file.
- Use of streamlit framework for UI
- Use of OpenAI LLM model
This will give you some ideas on using the LLM model with proper prompts and instructions to fulfill your task.
Frequently Asked Question
A. Streamlit is a library which allows you to build the front end (UI) for your data science and machine learning tasks by writing all the code in Python. Beautiful UIs can easily be designed through numerous components from the library.
A. Flask is a lightweight micro-framework that is simple to learn and use. A more recent framework called Streamlit is made exclusively for web applications that are driven by data.
A. No, It depends on the use case to use case. In this example, we know what information needs to be extracted but if you want to extract more or less information you need to give the proper instructions and an example to the LLM model accordingly it will extract all the mentioned information.
A. Generative AI has the potential to have a profound impact on the creation, construction, and play of video games as well as it can replace most human-level tasks with automation.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.