



{kind=link}
Introduction
Movies hold universal appeal, connecting people of all backgrounds. Despite this unity, our individual movie preferences remain distinct, ranging from specific genres like thrillers, romance, or sci-fi to focusing on favorite actors and directors. While it’s challenging to generalize movies everyone would enjoy, data scientists analyze behavioral patterns to identify groups of similar movie preferences in society. As data scientists, we extract valuable insights from audience behavior and movie attributes to develop the “Movie Recommendation System.” These systems aim to suggest movies tailored to individual tastes, enhancing the movie-watching experience. Let’s delve into the fundamentals of the “Movie Recommendation System” to unlock the magic of personalized movie suggestions.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is a Recommendation System?
A Recommendation System is a filtration program whose prime goal is to predict a user’s “rating” or “preference” towards a domain-specific item or item. In our case, this domain-specific item is a movie. Therefore the main focus of our recommendation system is to filter and predict only those movies which a user would prefer given some data about the user him or herself.
Why Recommendation Systems?
Recommendation Systems are essential for several reasons:
- Recommendation Systems offer personalized suggestions based on user preferences, ensuring that users discover content and products that are relevant and interesting to them.
- By providing tailored recommendations, users are more likely to engage with the platform, increasing user satisfaction and retention.
- E-commerce platforms use recommendation systems to promote products, leading to higher sales and revenue as users discover and purchase items they might not have otherwise considered.
- In today’s vast digital landscape, recommendation systems help users navigate the overwhelming amount of content available, making it easier to find what they seek.
- Recommendation systems expose users to new and diverse content, expanding their horizons and introducing them to items they might have overlooked.
- For complex and subjective choices, such as movies, music, or books, recommendation systems help users make informed decisions by relying on past behavior and preferences.
Types of Recommendation Systems
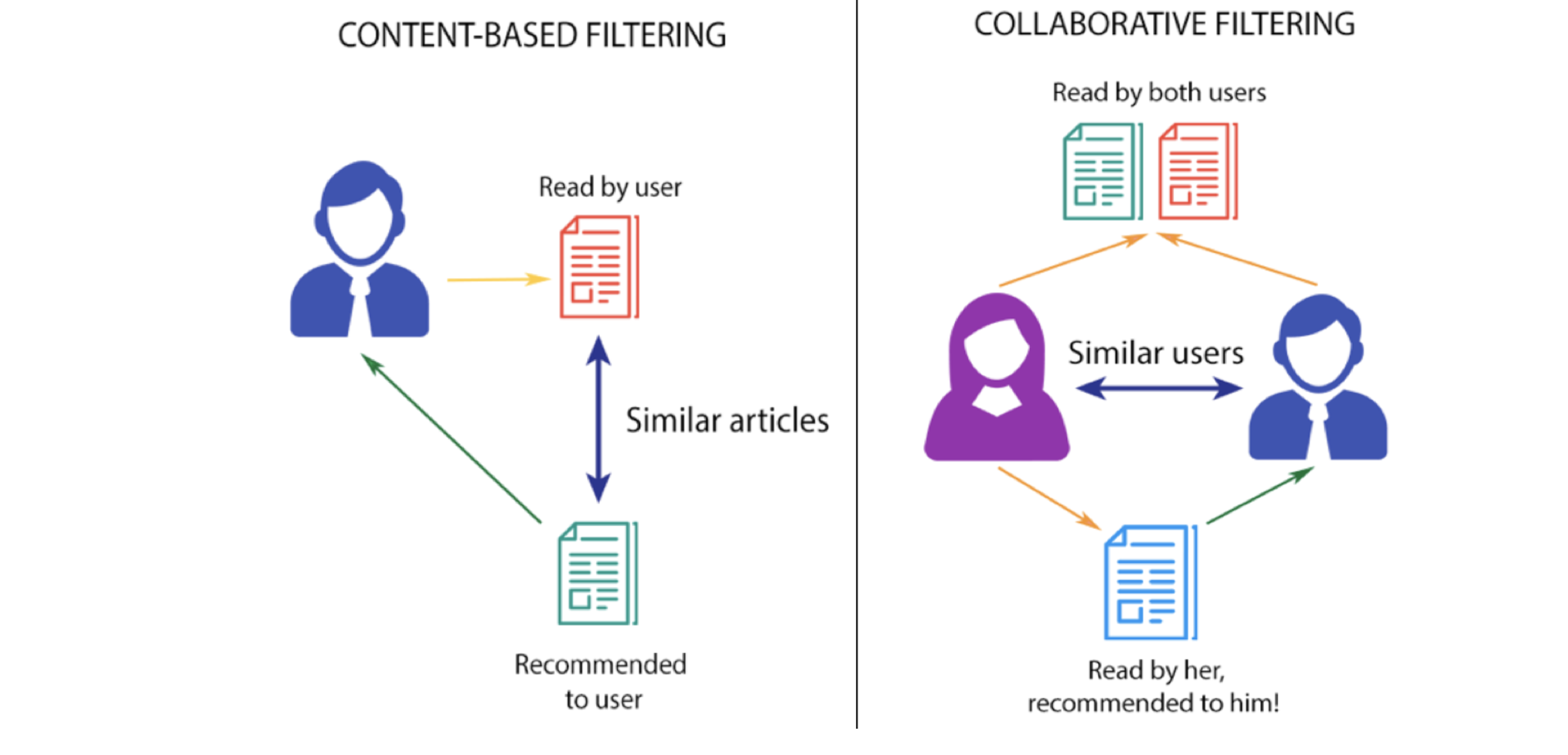
Content-based Filtering
Content-based filtering is a recommendation strategy that suggests items similar to those a user has previously liked. It calculates similarity (often using cosine similarity) between the user’s preferences and item attributes, such as lead actors, directors, and genres. For example, if a user enjoys ‘The Prestige’, the system recommends movies with ‘Christian Bale’, ‘Thriller’ genre, or films by ‘Christopher Nolan’.
However, content-based filtering has drawbacks. It limits exposure to different products, preventing users from exploring a variety of items. This can hinder business expansion as users might not try out new types of products
Collaborative Filtering
Collaborative filtering is a recommendation strategy that considers the user’s behavior and compares it with other users in the database. It uses the history of all users to influence the recommendation algorithm. Unlike content-based filtering, collaborative filtering relies on the interactions of multiple users with items to generate suggestions. It doesn’t solely depend on one user’s data for modeling. There are various approaches to implement collaborative filtering, but the key concept is the collective influence of multiple users on the recommendation outcome.
There are 2 types of collaborative filtering algorithms:
User-based Collaborative filtering
User-based collaborative filtering aims to recommend items to a user (A) based on the preferences of similar users in the database. It involves creating a matrix of items rated/liked/clicked by each user, computing similarity scores between users, and then suggesting items that user A hasn’t encountered yet but similar users have liked.
For example, if user A likes ‘Batman Begins’, ‘Justice League’, and ‘The Avengers’, and user B likes ‘Batman Begins’, ‘Justice League’, and ‘Thor’, they share similar interests in the superhero genre. Therefore, there is a high likelihood that user A would enjoy ‘Thor’, and user B would like ‘The Avengers’.
Disadvantages
User-based collaborative filtering has several disadvantages:
- Fickle User Preferences: User preferences can change over time, leading to initial similarity patterns between users becoming outdated. This can result in inaccurate recommendations as users’ tastes evolve.
- Large Matrices: As the number of users is typically much larger than the number of items, maintaining large matrices becomes challenging and resource-intensive. Regular recomputation is required to keep the data up-to-date.
- Vulnerability to Shilling Attacks: Shilling attacks involve creating fake user profiles with biased preference patterns to manipulate the recommendation system. User-based collaborative filtering is susceptible to such attacks, potentially leading to biased and manipulated recommendations.
Item-based Collaborative Filtering
Item-based Collaborative Filtering focuses on finding similar movies instead of similar users to recommend to user ‘A’ based on their past preferences. It identifies pairs of movies rated/liked by the same users, measures their similarity across all users who rated both, and then suggests similar movies based on the similarity scores.
For example, when comparing movies ‘A’ and ‘B’, we analyze the ratings given by users who rated both movies. If these ratings show high similarity, it indicates that ‘A’ and ‘B’ are similar movies. Thus, if someone liked ‘A’, they should be recommended ‘B’, and vice versa.
Advantages over User-based Collaborative
Filtering include stable movie preferences, as movies do not change like people’s tastes do. Additionally, maintaining and computing matrices is easier as there are usually fewer items than users. Shilling attacks are also more challenging since items cannot be faked, making this approach more robust.
Movie Recommendation System Code
In this implementation, when the user searches for a movie we will recommend the top 10 similar movies using our movie recommendation system. We will be using an item-based collaborative filtering algorithm for our purpose. The dataset used in this demonstration is the movielens-small dataset.
Getting the Data Up and Running
First, we need to import libraries which we’ll be using in our movie recommendation system. Also, we’ll import the dataset by adding the path of the CSV files. Then we will have a look at the movies dataset :
Python Code:
Movie dataset has:
- movieId – once the recommendation is done, we get a list of all similar movieId and get the title for each movie from this dataset.
- genres – which is not required for this filtering approach.
Code
ratings.head()Output
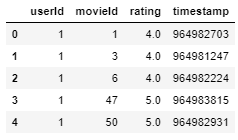
Ratings dataset has-
- userId – unique for each user.
- movieId – using this feature, we take the title of the movie from the movies dataset.
- rating – Ratings given by each user to all the movies using this we are going to predict the top 10 similar movies.
Here, we can see that userId 1 has watched movieId 1 & 3 and rated both of them 4.0 but has not rated movieId 2 at all. This interpretation is harder to extract from this dataframe. Therefore, to make things easier to understand and work with, we are going to make a new dataframe where each column would represent each unique userId and each row represents each unique movieId.
Code
final_dataset = ratings.pivot(index='movieId',columns='userId',values='rating')
final_dataset.head()Output
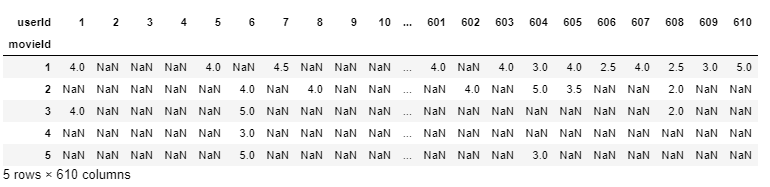
Now, it’s much easier to interpret that userId 1 has rated movieId 1& 3 4.0 but has not rated movieId 3,4,5 at all (therefore they are represented as NaN ) and therefore their rating data is missing.
Let’s fix this and impute NaN with 0 to make things understandable for the algorithm and also making the data more eye-soothing.
Code
final_dataset.fillna(0,inplace=True)
final_dataset.head()Output
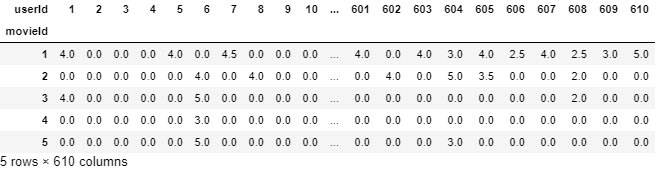
Removing Noise from the data
In the real-world, ratings are very sparse and data points are mostly collected from very popular movies and highly engaged users. We wouldn’t want movies that were rated by a small number of users because it’s not credible enough. Similarly, users who have rated only a handful of movies should also not be taken into account.
So with all that taken into account and some trial and error experimentations, we will reduce the noise by adding some filters for the final dataset.
- To qualify a movie, a minimum of 10 users should have voted a movie.
- To qualify a user, a minimum of 50 movies should have voted by the user.
Let’s Visualize How These Filters Look Like
Aggregating the number of users who voted and the number of movies that were voted.
Code
no_user_voted = ratings.groupby('movieId')['rating'].agg('count')
no_movies_voted = ratings.groupby('userId')['rating'].agg('count')Let’s visualize the number of users who voted with our threshold of 10.
f,ax = plt.subplots(1,1,figsize=(16,4))
# ratings['rating'].plot(kind='hist')
plt.scatter(no_user_voted.index,no_user_voted,color='mediumseagreen')
plt.axhline(y=10,color='r')
plt.xlabel('MovieId')
plt.ylabel('No. of users voted')
plt.show()Output
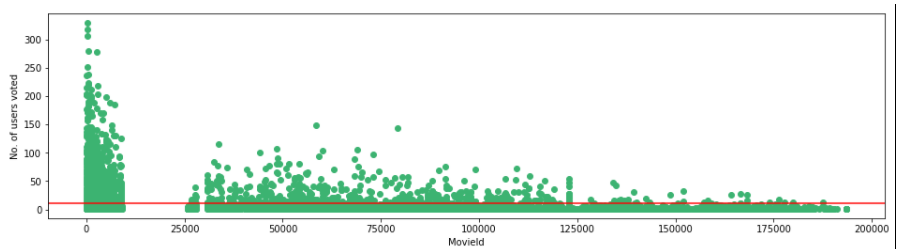
Making the necessary modifications as per the threshold set.
Code
final_dataset = final_dataset.loc[no_user_voted[no_user_voted > 10].index,:]Let’s visualize the number of votes by each user with our threshold of 50.
f,ax = plt.subplots(1,1,figsize=(16,4))
plt.scatter(no_movies_voted.index,no_movies_voted,color='mediumseagreen')
plt.axhline(y=50,color='r')
plt.xlabel('UserId')
plt.ylabel('No. of votes by user')
plt.show()Output
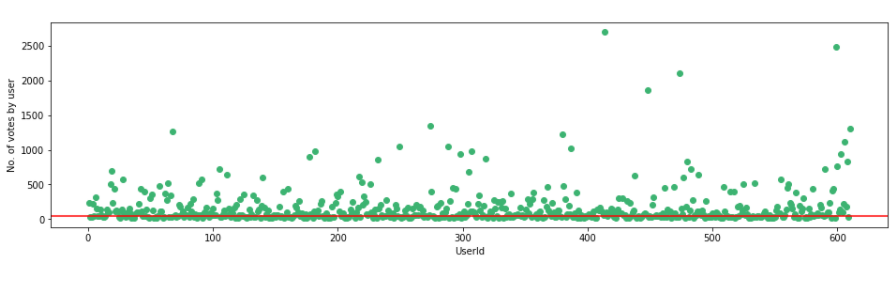
Making the necessary modifications as per the threshold set.
Code
final_dataset=final_dataset.loc[:,no_movies_voted[no_movies_voted > 50].index]
final_datasetOutput
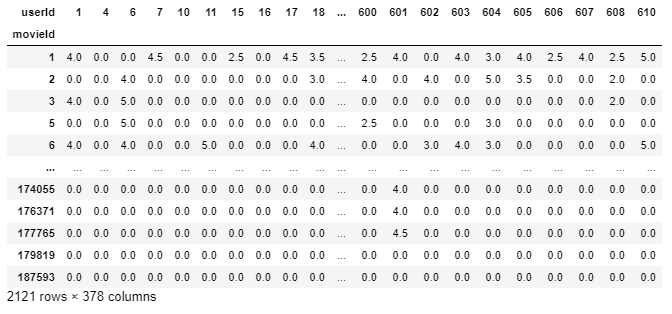
Removing Sparsity
Our final_dataset has dimensions of 2121 * 378 where most of the values are sparse. We are using only a small dataset but for the original large dataset of movie lens which has more than 100000 features, our system may run out of computational resources when that is feed to the model. To reduce the sparsity we use the csr_matrix function from the scipy library.
I’ll give an example of how it works :
Code
sample = np.array([[0,0,3,0,0],[4,0,0,0,2],[0,0,0,0,1]])
sparsity = 1.0 - ( np.count_nonzero(sample) / float(sample.size) )
print(sparsity)Output

Code
csr_sample = csr_matrix(sample)
print(csr_sample)Output

As you can see there is no sparse value in the csr_sample and values are assigned as rows and column index. for the 0th row and 2nd column, the value is 3.
Applying the csr_matrix method to the dataset :
csr_data = csr_matrix(final_dataset.values)
final_dataset.reset_index(inplace=True)Making the movie recommendation system model
We will be using the KNN algorithm to compute similarity with cosine distance metric which is very fast and more preferable than pearson coefficient.
knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=20, n_jobs=-1)
knn.fit(csr_data)Making the Recommendation Function
The working principle is very simple. We first check if the movie name input is in the database and if it is we use our recommendation system to find similar movies and sort them based on their similarity distance and output only the top 10 movies with their distances from the input movie.
def get_movie_recommendation(movie_name):
n_movies_to_reccomend = 10
movie_list = movies[movies['title'].str.contains(movie_name)]
if len(movie_list):
movie_idx= movie_list.iloc[0]['movieId']
movie_idx = final_dataset[final_dataset['movieId'] == movie_idx].index[0]
distances , indices = knn.kneighbors(csr_data[movie_idx],n_neighbors=n_movies_to_reccomend+1)
rec_movie_indices = sorted(list(zip(indices.squeeze().tolist(),distances.squeeze().tolist())),key=lambda x: x[1])[:0:-1]
recommend_frame = []
for val in rec_movie_indices:
movie_idx = final_dataset.iloc[val[0]]['movieId']
idx = movies[movies['movieId'] == movie_idx].index
recommend_frame.append({'Title':movies.iloc[idx]['title'].values[0],'Distance':val[1]})
df = pd.DataFrame(recommend_frame,index=range(1,n_movies_to_reccomend+1))
return df
else:
return "No movies found. Please check your input"Finally, Let’s Recommend some movies!
get_movie_recommendation('Iron Man')
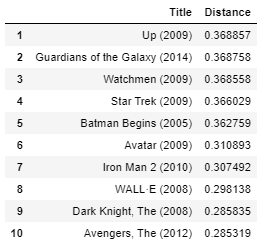
I personally think the results are pretty good. All the movies at the top are superhero or animation movies which are ideal for kids as is the input movie “Iron Man”.
Let’s try another one :
get_movie_recommendation('Memento')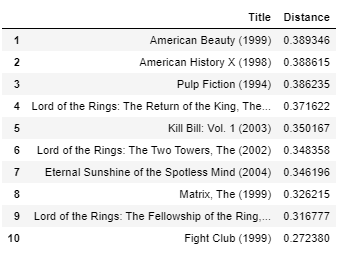
All the movies in the top 10 are serious and mindful movies just like “Memento” itself, therefore I think the result, in this case, is also good.
Our model works quite well- a movie recommendation system based on user behavior. Hence, we conclude our collaborative filtering here. You can get the complete implementation notebook here.
Conclusion
In conclusion, creating a movie recommendation system with machine learning improves user experience. It offers personalized movie suggestions based on individual preferences. Join the Blackbelt Plus program to enhance your machine-learning skills and build cutting-edge recommendation models. Propel your career in data science and make a difference in the world of personalized movie recommendations. Enroll in the program today and step into the future of movie suggestions!