



This article was published as a part of the Data Science Blogathon
Machine Learning Models that reside in your editor environment are as good as dead 🙁
Introduction
In this blog, we will learn how we can bring a machine learning model to life using Flask as well as provide an easy graphical user interface (GUI) to interact with the model API using the Flasgger package.
We will specifically learn about encapsulating our model into a REST-API using the Flask framework and also generate a simple visual UI around the API using the flasgger python package so that you can easily present your model to stakeholders.
Process Overview.
- Build and save a simple machine learning model using scikit-learn and pickle
- Create a Flask API for using this model
- Add Easy UI components in the flask app itself using flasgger (No Front-End Knowledge Needed)
Table of Contents
1. Overview of Packages Used
2. Installing Required Packages
3.Building and Saving Machine Learning Model
4.Converting Model into REST API using flask
5. Add Simple UI elements into Flask API using flasgger
6. Display Output Application
7. Code Links
1. Packages Overview
1.1 Flask
Flask is a web application framework written in python that enables us to interact with python code (in our case machine learning models ) directly from the browser without needing any code files libraries etc.
Flask enables us to create web application programming interfaces (APIs) easily so that data scientists can spend more time on Exploratory Data Analysis, Feature Engineering, Model Building, etc without worrying about the availability of models to the outside world.
We can easily deploy our machine learning models by way of creating an API through Flask and make it available over the browser itself.
For more information on Flask, Please go through the basic documentation-
1.2 Flasgger
Flasgger is a Flask extension to extract OpenAPI-Specification from all Flask views registered in your API. Flasgger also comes with SwaggerUI embedded so you can access http://localhost:5000/apidocs and visualize and interact with your API resources. Flasgger is a Flask extension to help the creation of Flask APIs with documentation and a live playground powered by SwaggerUI
2. Installing Required Packages
Open Anaconda Prompt in case of using conda environment or cmd in case of using standard python installation,
For Mac OS users open terminal and type
pip install flask pip install flasgger
3. Building and Saving Machine Learning Model
In the below code we will build a simple Binary Classifier using Logistic Regression, We will create the dataset with the help of the scikit learn library make classification method and then finally save/export the model using pickle library.
We will be building a simple model for the sake of simplicity as the main aim of writing this article is to depict how we can easily consume our machine learning models by developing APIs using Flask and Flassger.
# Importing Libraries import numpy as np from flask import Flask,jsonify,request from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score,classification_report from sklearn.linear_model import LogisticRegression import pickle import os from flasgger import Swagger import flasgger
def train_and_save_model():
'''This function creates and saves a Binary Logistic Regression
Classifier in the current working directory
named as LogisticRegression.pkl
'''
## Creating Dummy Data for Classificaton from sklearn.make_classification
## n_samples = number of rows/number of samples
## n_features = number of total features
## n_classes = number of classes - two in case of binary classifier
X,y = make_classification(n_samples = 1000,n_features = 4,n_classes = 2)
## Train Test Split for evaluation of data - 20% stratified test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42,stratify=y)
## Building Model
logistic_regression = LogisticRegression(random_state=42)
## Training the Model
logistic_regression.fit(X_train,y_train)
## Getting Predictions
predictions = logistic_regression.predict(X_test)
## Analyzing valuation Metrics
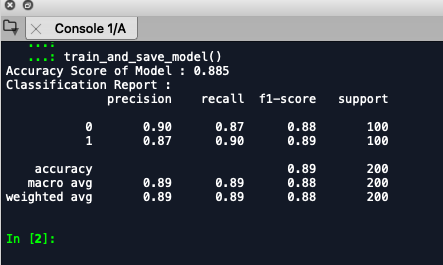
print("Accuracy Score of Model : "+str(accuracy_score(y_test,predictions)))
print("Classification Report : ")
print(str(classification_report(y_test,predictions)))
## Saving Model in pickle format
## Exports a pickle file named Logisitc Regrssion in current working directory
output_path = os.getcwd()
file_name = '/LogisticRegression.pkl'
output = open(output_path+file_name,'wb')
pickle.dump(logistic_regression,output)
output.close()
train_and_save_model()
Calling this function saves a file named LogisticRegression.pkl in the current working directory and produces this output –
{kind=link}
 4. Building Flask API for consuming the model
4. Building Flask API for consuming the model
Voila, now we have the Logistic Regression Model (89% Accuracy 🙂 ) pickle file with us.
Let’s look at the code for encapsulating the same into a Flask API also embedding some UI components from flasgger
4.1 Let’s first declare our flask app and it to Swagger interface-
app = Flask(__name__) Swagger(app)
4.2 Now we will define an app route for an API which essentially means whenever we visit http://127.0.0.1:5000/predict_home this function will be executed in which we have hard-coded feature values and generated predictions from our model.
@app.route('/predict_home/',methods = ['GET'])
def get_predictions_home():
feature_1 = 1
feature_2 = 2
feature_3 = 3
feature_4 = 4
test_set = np.array([[feature_1,feature_2,feature_3,feature_4]])
## Loading Model
infile = open('LogisticRegression.pkl','rb')
model = pickle.load(infile)
infile.close()
## Generating Prediction
preds = model.predict(test_set)
return jsonify({"class_name":str(preds)})
Now we need to start the flask server by running python model_deployment_blog_script.py
in the terminal and open the mentioned http://127.0.0.1:5000/predict_home/ in the browser
Output Screenshot –
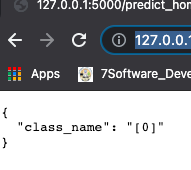
Voila, We have our first flask API up and running :). Good Work 🙂
5. Adding Simple UI Elements to interact with this Flask API.
Now we will define another app route in our code which would have a function containing the UI elements as well in the form of the docstring.
We will add 4 input fields with names feature_1, feature_2, feature_3, feature_4 so that we can take inputs from the user itself.
Please Note – in the docstring please maintain the indentation level.
Here is the detailed code snippet for the function –
@app.route('/predict',methods = ['GET'])
def get_predictions():
"""
A simple Test API that returns the predicted class given the 4 parameters named feature 1 ,feature 2 , feature 3 and feature 4
---
parameters:
- name: feature_1
in: query
type: number
required: true
- name: feature_2
in: query
type: number
required: true
- name: feature_3
in: query
type: number
required: true
- name: feature_4
in: query
type: number
required: true
responses:
200:
description : predicted Class
"""
## Getting Features from Swagger UI
feature_1 = int(request.args.get("feature_1"))
feature_2 = int(request.args.get("feature_2"))
feature_3 = int(request.args.get("feature_3"))
feature_4 = int(request.args.get("feature_4"))
# feature_1 = 1
# feature_2 = 2
# feature_3 = 3
# feature_4 = 4
test_set = np.array([[feature_1,feature_2,feature_3,feature_4]])
## Loading Model
infile = open('LogisticRegression.pkl','rb')
model = pickle.load(infile)
infile.close()
## Generating Prediction
preds = model.predict(test_set)
return jsonify({"class_name":str(preds)})
Now we need to save the code and restart the server once again and visit
http://127.0.0.1:5000/apidocs/
and we can see the output.
6. Output Screenshot
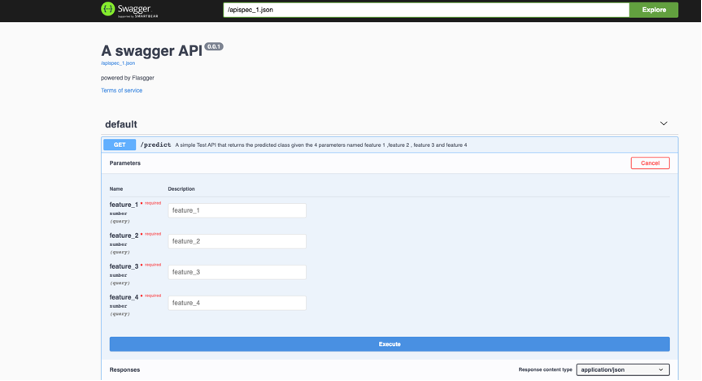
Here we can add the 4 feature numerical values and click execute to see the response from our model.
7. Code Links
https://github.com/siddinho/flask-flasgger-tutorial/tree/master
ENDNOTES
Today we learned how to encapsulate our Machine Learning Model in a Flask API and also how to easily add UI Components for easy interaction with the API through flassger.
We can easily build rapid prototypes of our models using these concepts and present the same to the stakeholders.
To check out the full code please refer to my Github repository
Hope all of this helps! 🙂
Happy Data Sleuthing.
About the Author
Hi Everyone,
I am Siddharth Vohra,
Currently working as a Senior Data Scientist with Dürr Group, having total experience of 3.5 years in Data Science and Machine Learning Space
Please feel free to connect with me on Linkedin