



{kind=link}
MLOps is the intersection of Machine Learning, DevOps and Data Engineering.
Introduction:
As the data science and machine learning models are becoming more capable of solving complex business problems, it is evident that many businesses continue to invest in building their capabilities in this field to deliver business value to their users. This trend is also driven by the fact that managing resources such as huge data, infrastructure, compute power, pretrained models, etc have become very inexpensive and on-demand which has enabled teams to go from prototype to production in a very short time.
However, the businesses have also realized that the real challenge isn’t in building machine learning models but on the operational side of things, especially in production. How do we ensure the different pieces of functionalities built by various teams integrate seamlessly? How do make sure that the model in production is not drifting? How do we automatically validate the data from various sources and check for standards? How do we refresh models in production on the fly?
These and many more such questions are not new, and we have seen similar stuff on the typical web development over the years. There have been various methodologies and approaches developed and one such thing is DevOps which has to a large extent addressed these challenges and is the norm currently. So, is there a way to leverage its power in data science?. Let’s explore.
DevOps Lifecycle:
DevOps refers to a software development method and a collaborative way of developing and deploying software. It is a practice that allows a single team to manage the entire application development life cycle, that is, development, testing, deployment, operations. DevOps helps to establish cross-functional teams that share responsibility for maintaining the system that runs the software and prepares the software to run on that system with increased quality feedback and automation issues. At a high level, there are different stages of the DevOps lifecycle.
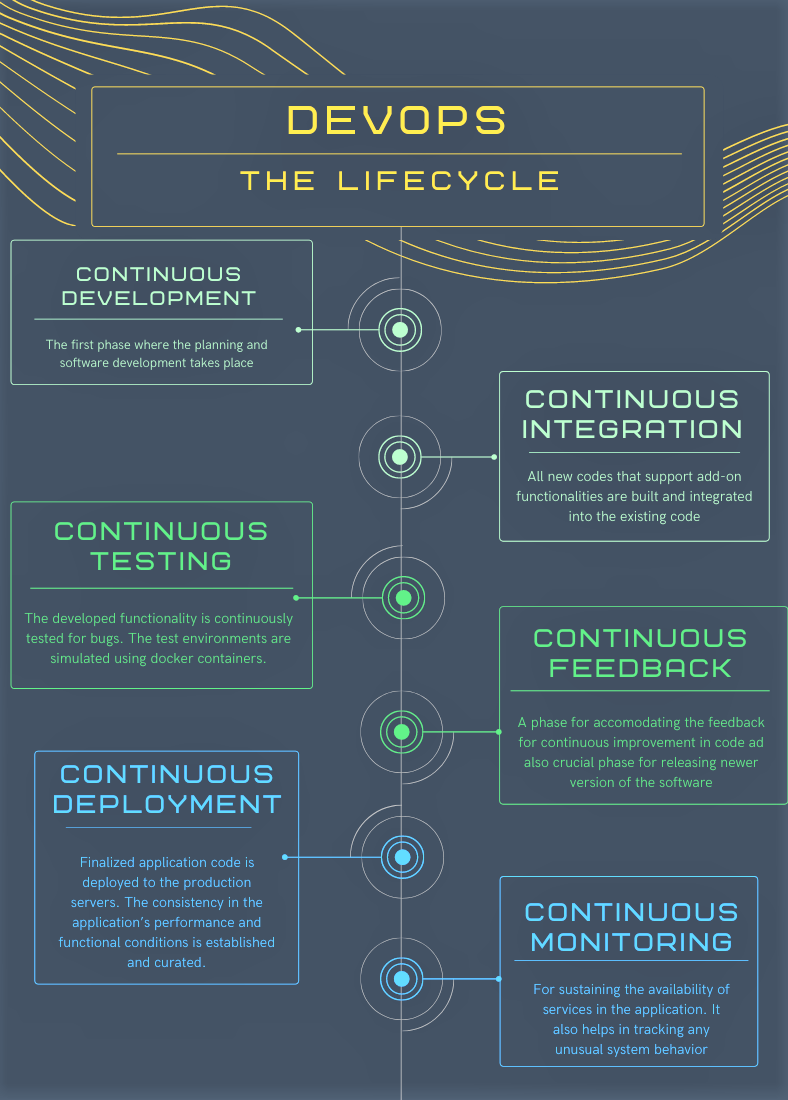
Here is how all the above components come together to create a seamless development, integration, testing and deployment.
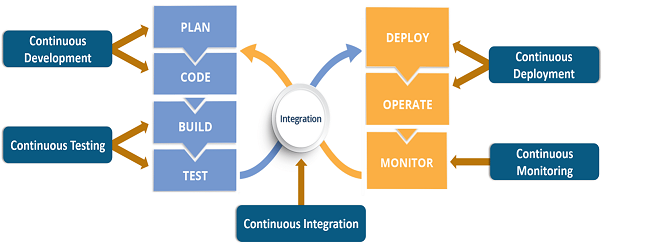
Source: Edureka
Data Science Lifecycle:
Similar to typical Software Development Lifecycle (SDLC), most data science projects do have a process that outlines the major stages of execution. The lifecycle is not linear meaning each stage may undergo multiple iterations till we reach satisfying results which are acceptable technically and by the business. The various stages of the lifecycle can be summarized below.
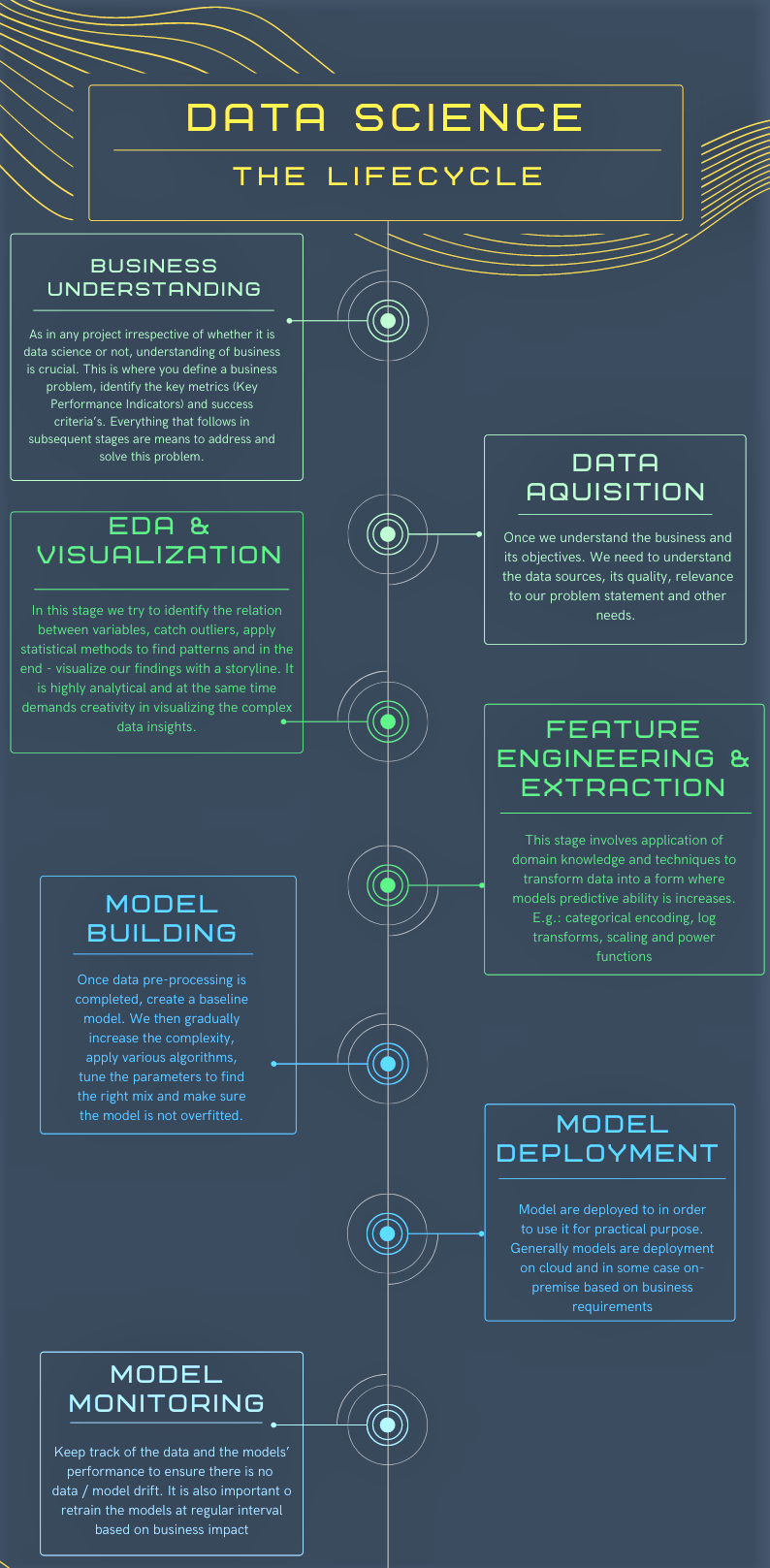
Machine Learning Operations (MLOps):
Any Prerequisites?
To understand MLOps, you will need very basic knowledge of model building in python and a GitHub account. I will be using Visual Studio Code as editor; you can use any editor of your choice as long as you are comfortable with it.
Getting Started:
We will be using Kaggle’s South Africa Heart Disease dataset. Here is the data dictionary for reference. Our objective is to predict chd i.e., coronary heart disease (yes=1 or no=0). A simple binary classification model.
- sbp: systolic blood pressure
- tobacco: cumulative tobacco (kg)
- ldl: low-density lipoprotein cholesterol
- adiposity:
- famhist: family history of heart disease (Present=1, Absent=0)
- typea: type-A behavior
- obesity
- alcohol: current alcohol consumption
- age: age at onset
- chd: coronary heart disease (yes=1 or no=0)
Let’s load the dataset and take a quick look at data and some basic stats. We will also drop ‘famhist‘ variable for now and will experiment with it at a later stage
Python Code: