



{kind=link}
This article was published as a part of the Data Science Blogathon.

Source: Canva
Introduction
Most recent speech recognition models often rely on large supervised datasets, which are unavailable for many low-resource languages; this poses a challenge in creating a speech recognition model inclusive of all languages. To address this, researchers from Carnegie Mellon University have proposed a method to create speech recognition systems that don’t require any audio dataset or pronunciation lexicon for the target language. The only prerequisite is having access to raw text datasets or a set of n-gram statistics for the target language.
In this article, we will take a look at this proposed method in further detail. Let’s get started!
Highlights
-
ASR2K is a speech recognition pipeline that does not require audio for the target language. The only assumption is that access to raw text datasets or a set of n-gram statistics is available.
-
The speech pipeline in ASR2K comprises three components i.e., acoustic, pronunciation, and language models.
-
The acoustic and pronunciation models employ multilingual models without supervision, in contrast to the conventional pipeline. The language model is created using the raw text dataset or n-gram statistics.
-
This approach was used for 1909 languages using Crúbadán, a large endangered languages n-gram database. Then it was subsequently tested on 129 languages (34 languages from the Common Voice dataset + 95 languages from the CMU Wilderness dataset).
-
On testing, only 50% CER (Character Error Ratio) and 74% WER (Word Error Ratio) were achieved on the Wilderness dataset using Crúbadán statistics. These results were subsequently improved to 45% CER and 69% WER when using 10,000 raw text utterances.
Existing Methods
Modern architectures typically require thousands of hours of training data for the target language to perform well. However, there are about 8000 languages spoken worldwide, the majority of which lack audio or text datasets.
Some attempts have decreased the training set’s size by leveraging pre-trained features from self-supervised learning models. However, these models continue to rely on a small amount of paired supervised data for word recognition.
More recently, considering the success of unsupervised machine translation, some work has been applying the unsupervised approach to improve speech recognition. These models apply adversarial learning to learn a mapping between audio representations and phoneme units automatically. Despite the success of these recent approaches, all of these models depend on some audio datasets of the target language (labeled or unlabeled), which severely limits the range of target languages.
Proposed Methodology for ASR2K
The speech pipeline comprises the acoustic, pronunciation, and language models.
The acoustic model should still recognize the target languages’ phonemes even if the languages are unseen in the training set.
The pronunciation model is a G2P (grapheme-to-phoneme) model that can predict phoneme pronunciation given a sequence of graphemes.
Both acoustic and pronunciation models can be trained using supervised datasets from high-resource languages and then applied to the target language with the help of some linguistic knowledge. The acoustic and pronunciation models employ multilingual models and can be used in a zero-shot learning setting without supervision, in contrast to the standard pipeline.
A lexical graph is created by encoding the approximate pronunciation of each word using the pronunciation model. Finally, the raw texts or n-gram statistics are used to create a language model combined with the pronunciation model to create a (weighted finite-state transducer) WFST decoder.
The joint probability over speech audio (X) and speech text (Y) is defined as follows:
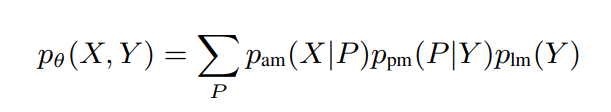
, where P is the phoneme sequence corresponding to the text (Y). Typically, the pronunciation model ppm is modeled as a deterministic function δpm. Moreover, only the language model can be estimated from the text, whereas the acoustic model and pronunciation model are approximated using zero-shot learning or transfer learning from other high-resource languages; hence pˆam, ˆδpm corresponds to the approximated acoustic model and pronunciation model. The prior factorization can be roughly represented as:

, where Pˆ = ˆδpm(Y ) is the approximated phonemes.
To analyze the pipeline more effectively with small test sets, an approach is used to decompose the observed errors into acoustic/pronunciation model errors and language model errors.
Evaluation Results
This approach was used for 1909 languages using Crúbadán, a large endangered languages n-gram database. Then it was tested on 129 languages (34 languages from the Common Voice dataset + 95 languages from the CMU Wilderness dataset).
1) Evaluating the Acoustic model using PER: The acoustic model is evaluated using the phoneme error rate (PER) metric. It offers many useful insights about acoustic models.
Table 1 illustrates the performance across 4 acoustic models. The baseline acoustic model has approximately 50% PER, and half of the errors are deletion errors. It turns out that domain and language mismatches are the primary causes of the deletion errors. The SSL-based models were used to boost the robustness, which lowered the error rate by 5%. Remarkable improvement is obtained from the deletion reduction. In addition, it was found that the XLSR model performed the best, so it was used as the primary model in the pipeline.
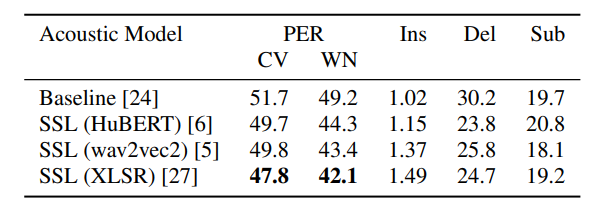
Table 1: Average results (PER) of the acoustic model in all test languages.
2) Evaluating the Language Model: Table 2 illustrates the performance of the language model. First, n-gram statistics
from the Crúbadán are tried without using any text dataset, and it turns out that Crúbadán captures some character-level information even
without any text dataset: it achieved 65% and 50% CER on two datasets. Next, the training sets 1k, 5k, and 10k text utterances are used to train the model without Crúbadán. This improves the performance remarkably, considering the training text datasets are in the same domain as the test dataset. A 10k text dataset achieved 51% and 45% CER.
Furthermore, the effect of using Crúbadán and text language models in conjunction was also evaluated. However, this approach didn’t improve the performance since there is a domain mismatch between the two models.
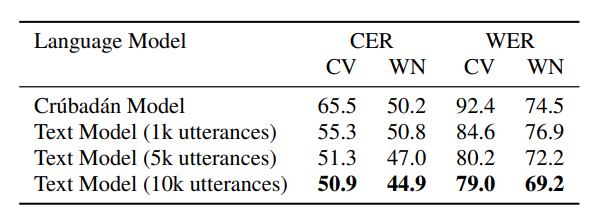
Table 2: Average Performance of the language model on all testing languages in terms of CER and WER under different resource conditions.
These results are a milestone considering it is the first attempt to build an audio-free speech recognition pipeline for approximately 2000 languages.
Conclusion
In this article, we explored an audio-free speech recognition pipeline (ASR2K) that doesn’t require any audio dataset or pronunciation lexicon for the target language. The key takeaways from this post are as follows:
- ASR2K is a speech recognition pipeline for 1909 languages that don’t require audio for the target language. The only prerequisite is having access to raw text datasets or a set of n-gram statistics.
- The speech pipeline comprises the acoustic, pronunciation, and language models.
- Only the ASR2K language model can be estimated from the text in the proposed pipeline. In contrast, the acoustic and pronunciation models are approximated using transfer learning from other high-resource languages or zero-shot learning.
- The raw texts or n-gram statistics are used to build a language model combined with the pronunciation model to build a WFST decoder.
- On testing this approach on 129 languages across two datasets, ie. Common Voice and CMU Wilderness dataset, 50% CER and 74% WER were achieved on the Wilderness dataset using Crúbadán statistics only. These results were subsequently improved to 45% CER and 69% WER when using 10,000 raw text utterances.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
Link to Research Paper: https://arxiv.org/pdf/2209.02842.pdf
Link to Code: https://github.com/xinjli/asr2k
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.