



{kind=link}
This article was published as a part of the Data Science Blogathon.

Machine learning is used to solve the problem in which the rules to get the desired output are too hard (almost impossible) to mapped manually by a human. So, instead of giving the rules to a computer, we feed the desired output and let the computer learn (guess) the pattern to figure out the rules by itself.
In this article, we will create a simple machine learning implementation in Python using the TensorFlow library.
The real-world problems are more complex than this and require advanced-level algorithms to derive better and crisp insights from data. Check out our Certified AI & ML BlackBelt Accelerate program.
The model we will build expected to be able to find this formula:
y = 2x + 4
We will not write that formula into the program. Instead, we will give several input samples (x), and outputs from the given input.
Creating the model architecture
This is the model architecture we want to build. It’s a very simple model.
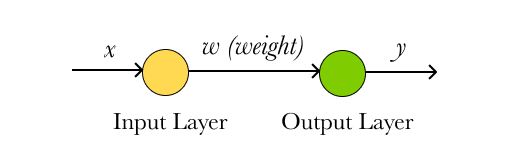
and this is how it looks in the code:
import tensorflow as tf model = tf.keras.Sequential() model.add(tf.keras.layers.Dense(units=1, input_shape=[1])) model.compile(optimizer='sgd', loss='mean_squared_error')
The input_shape argument defines the number of input neurons and the units argument defines the number of output neurons. The loss argument is to define the loss function. The loss function is a function to measure how bad our current output compared to the target output. We also define the optimizer for our model. The optimizer is the algorithm that helps us find the best weight. Here we are using Stochastic gradient descent (SGD). The best weight is the weight that gives us a minimum loss.
We can print our model to the console to check the parameters of the model compiled using this line of code.
model.summary()
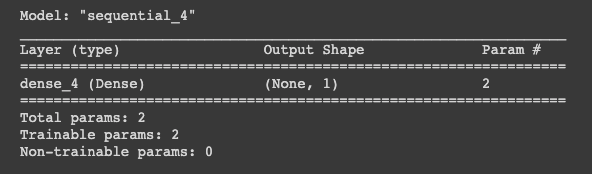
There are two trainable parameters listed. Because we only have one neuron in the input layer and one neuron in the output layer, therefore, we only have one weight to be trained. Another parameter is a bias neuron.
Provide the dataset
The input data will be stored on the x variable and the output data on the y variable. Here we only have ten data for each. In machine learning, the output of training data is called a label.
import numpy as np x = np.array([0, 4, 8, 6, 3, 2, 9, 5, 7, 1]) y = np.array([4, 12, 20, 16, 10, 8, 22, 14, 18, 6])
Train the model
Now we are ready to train our model. The epoch is 1000, which means that the algorithm will train on the data 1000 times. Thousand seems too big for epochs, but don’t worry, because our model is simple, it only takes a second to finish.
model.fit(x, y, epochs=1000, verbose=0)
Predict the unseen data
The main goal of our model is to be able to predict the unseen data. This is what distinguishes machine learning from other computer programs. It has the ability to adapt to unseen input data.
prediction = model.predict([12])
print(prediction)
The output is:
[[28.010925]]
The model never sees input 12 in the training phase, and the model also never told that the formula to calculate the output is y = 2x + 4. However, the machine learning model successfully predicts the output from the given input.
The problem used in this article can also be solved without machine learning. It is even easier without machine learning. However, the main goal of this article is for us to successfully build a simple machine learning model and to understand how it actually works.
What’s next
- Train the model with a different dataset
- Build a more complex model
- Play with an MNIST dataset
Short Author Bio:
My name is Muhammad Arnaldo, a machine learning enthusiast. Currently a master’s student of computer science.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
My name is Muhammad Arnaldo, a machine learning and data science enthusiast. Currently a master’s student of computer science in Indonesia.