



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Hello, data-enthusiast! In this article let’s discuss “Data Modelling” right from the traditional and classical ways and aligning to today’s digital way, especially for analytics and advanced analytics. Yes! Of course, last 40+ years we all worked for OLTP, and followed by we started focusing on OLAP.
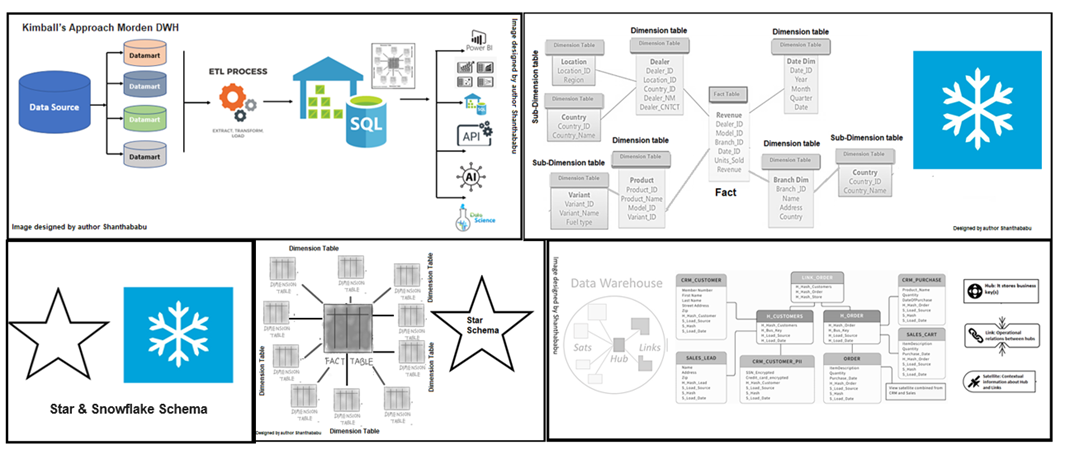
After cloud ear come into the picture the Data become very crazy level and every industry started zooming them and looking at different levels and perspectives. So, Big Data, Data Platform, Data Analytics, Data Science, and many more buzzwords are popping out of the window
“This is the technique is used to characterize the data and help us to know how it is stored in the available tables and alongside with other table and association between them”
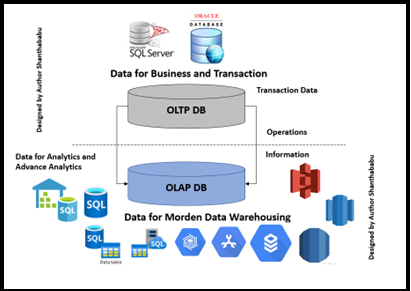
image designed by author shanthababu
Before getting into Data Modelling, let’s understand the few terminologies which is the ground for DATA architecting and modeling, which are nothing but OLTP and OLAP.
What is OLTP?
OLTP is nothing but Online Transaction Processing, and we can call this database workload used for transactional systems, which we use to play around with DDL, DML, and DCL.
OLAP is Online Analytical Processing, database workloads are used for modern data warehousing systems, in which we use to play around SELECT queries with simple or complex queries by filtering, grouping, aggregating, and portioning a large data set quickly for reporting/visualization for Data Analyst and Dataset for Data Scientists for specific reasons.
| OLTP |
OLAP | |
| Focus | Day-To-Day Operations |
Analysis and Analytics |
| DB Design |
Application-Specific | Business Driven |
| Nature Of the Data |
Current [RDBMS] |
Historical and Dimensional |
| DB Size |
In GB |
In TB |
What is Data Modelling
- Data modelling is the well-defined process of creating a data model to store the data in a database or Modren Data warehouse (DWH) system depending on the requirements and focused on OLAP on the cloud system.
- Always this is a conceptual interpretation of Data objects for the Applications or Products.
- This is specifically associated with the different data objects, and the business rules derived to achieve the goals
- It helps in the visual description of data and requires business rules, governing compliances, and government policies on the data like GDPR, PII and etc.,
- It ensures stability in naming conventions, default values, semantics, and security while ensuring the quality of the data.
Data Model
This defines the abstract model that organizes the Description, Semantics, and Consistency constraints of data.
What is really the Data Model underlines on
- What data need for DWH?
- How it should be organized in the DWH system,
DWH Data Model is like an architect’s building plan, which helps to build conceptual models and set a relationship between data-item, let’s say Dimension and Fact, and how they are linked together.
How we could implement DWH Data Modelling Techniques
- Entity-Relationship (E-R) Model
- UML (Unified-Modelling Language)
Consideration Factors for Data Modelling
While deriving the data model, there are several factors that need to be considered, these factors vary based on the different stages of the Data Lifecycle.
- Scope of the Business: There are several departments and diverse business functions around.
- ACID property of the data during transformation and storage.
- Feasibility of the data granularity levels of filtering, aggregation, slicing, and dicing
- Key features of Modern Data Warehouse
- Starts with logical modelling across multi-platforms and an extensive-architecture approach, its enhanced performance, and scalability.
- Serving data for all types and different categories of consumers
- [Data Scientist, Data Analysts, Downstream applications, API-based system, Data Sharing systems]
- Highly flexible deployment and decoupling approach for cost-effectiveness.
- Well-defined Data Governance model to support quality, visibility, availability security
- Streamlined Master Data Management and Data Catalog and Curation to support functionally and technically.
- Perfect monitoring and tracking of the Data Linage from Source into Serving layer
- Ability to facilitate Batch, Real-Time analysis, and Lambda process of high-velocity, verity, and veracity data.
- Supports Analytics and Advanced Analytics components.
- Agile Delivery approach from Data modelling and delivering aspects to satisfy, their business model.
- Excellent-Hybrid Integration with multiple cloud service providers and maximize the benefits for the customer
Why the Modern DWH be important for us?
Yes! The Modern Data Warehouse systems solve many problems in business challenges
- Data Availability
Data sources divided across organizations – Certainly, the Modern DWH system allows us to bring the data faster into our table in the form of different ranges and helps to analyze across the organizations, divisions, and behavior. It keeps getting the agility model and stimulates more and more. - Data Storage
Data Lakes – In the modern cloud the storage and computation are very flexible and extendable ways, instead of storing in hierarchical files and folders as we used in a traditional data warehouse, a data lake is an extensive repository that holds a massive amount of raw data, and you can store in its native format until required for processing layer. - Data Maintainability
As you know that we can’t maintain the historical data in a normal database like RDBMS, there were lots of challenges with respect to querying or fetching the data is a tedious process. So we have to build the DWH with Facts and Dimensions, and we could use the data for data perspective very easily and quickly. - IoT/ Streaming Data
Since we’re in the internet world the data flowing across the different applications and Internet of Things data has transformed and based on the business scenarios, needs, etc.
So far, we have discussed the concepts around the Modern DWH system, Let’s move on to data modelling components and techniques.
Data Model Evaluation
Generally, before building the model, each table would undergo the below stages, conceptual, logical, and physical, so exactly in the last stage only we would realize the model as accepted by the business.
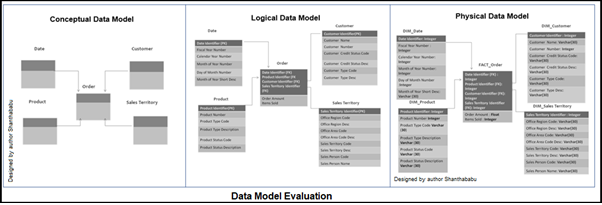
Source: image designed by author shanthababu
Multi-Dimensional Data Modelling Components
The main components are Fact and Dimension tables are the main two tables that are used when designing a data warehouse. The fact table contains the measures of columns and a special key called surrogate, that link to the dimensions tables.
Facts: To define FACTS in one word that is nothing but Measures
It can be measured attributes of the fields, it can be Quantitatively Measured, and in Numerical Quantities. Generally, it would be a number of orders received and products sold.
Dimensions: It has the attributes and basically “Category Values” or “Descriptive Definition” would be the Product Name, Description, Category, and so on.
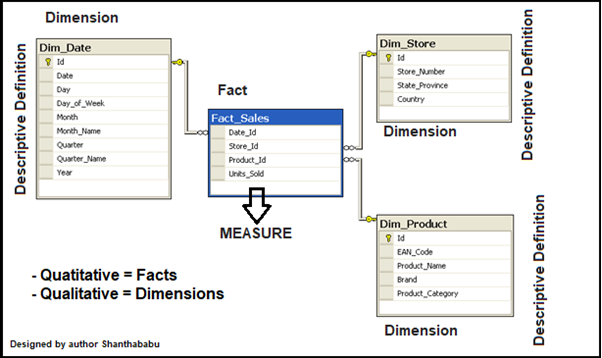
Source: image designed by author shanthababu
Modelling Techniques
For most of the scenarios, while developing the data modelling for DWH, we use to follow the Star Schema or Snowflake Schema, or Kimball’s Dimensional Data Modelling.

Source: image designed by author shanthababu
Star Schema: This is the most common technique and basic modelling type and is easy to understand. In which Fact table is connected with other all Dimension tables and considerably accepted architectural model and used to develop DWH and Data marts. Each dimension table in the star schema has a Primary-Key and which is related to a Foreign-Key. In the Fact table. joining the tables and querying a little complex and performance a bit slow.
The representation of this model seems like a star with the Fact table at the center and dimensions-tables connecting from all other sides of it, constructing a STAR-like model
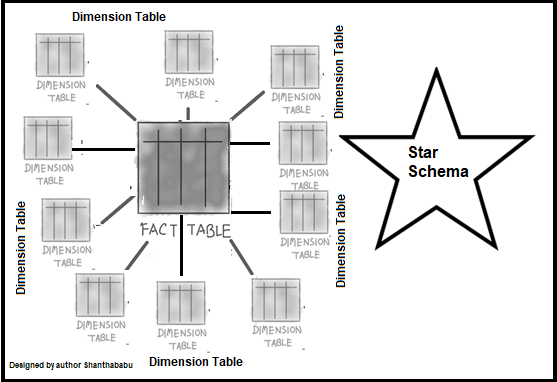
Source: image designed by author shanthababu
Snowflake Schema: This is an extension of the Star Schema with little modification and reduced load and improved performance. here the dimensions tables are normalized into multiple related tables as sub-dimension. So, it minimizes data redundancy. Apparently, it has multiple levels of joins which leads to less query complexity and ultimately improves query performance.
Tables are arranged logically and a many-to-one relationship hierarchy structure and it is resembling a SNOWFLAKE-like pattern. It has more joins between dimension tables, so performance issues might be in place, which leads to the slow query processing times for data retravel.
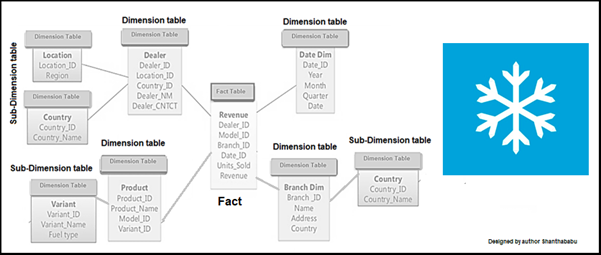
Let’s do a quick comparison of Star & Snowflake Schema
| Star Schema | Snowflake Schema |
| Simplified design and easy to understand | Complex design and a little difficult to understand |
| Top-Down model | Bottom-Up model |
| Required more space | Less Space |
| The fact table is surrounded by Dimension tables | The fact table is connected with dimension tables and dimension tables are connected with sub-dimension tables in normalized |
| Low query complexity | Complex query complexity |
| Not normalized, so there is a lesser number of relationships and foreign keys. |
Normalized, so required number of foreign keys and the well-defined relationship between tables |
| Since not normalized, a High volume of data redundancy | Since normalized, Low volume data redundancy. |
| Fast query execution time | Low query execution time due to more joins |
| One Dimensional | Multidimensional |
Everything is fine with the star schema, as we understood that this is Flexible, Extensible, and many more. But not answered business process and questions from DWH.
Kimball’s answer to below dimensional data modelling.
- The business process to a model – Keeping customer model, product model
- ATOMIC model – Depth of data level stored in the fact table in the concrete ATOMIC model so, we can’t split further for any analysis and not required too
- Building fact tables – designing the fact tables with a strong set of dimensions with all possible categories.
- Numeric facts – Identifying the most important numeric measures use to store at the fact table layer
- The part of the Data Analytics environment where structured data is broken down into low-level components and integrated with other components in preparation for exposure to data consumers
Then why do we need Kimball’s Approach? Obviously, we need them to Expedite the business value and Performance enhancement.
Expedite the business value: When you want to speed to business value, the data needs to be denormalized, so that BI teams can deliver to the business quickly and reliably and improve analytical workloads and performance.
- Bottom-up approach. the DWH is provisioned from the collection of DataMart.
- The Datamart is cooked from OLTP systems that are usually RDBMS and well-tuned with 3NF
- Here the DWH is central to the core model and de-normalized star schema.
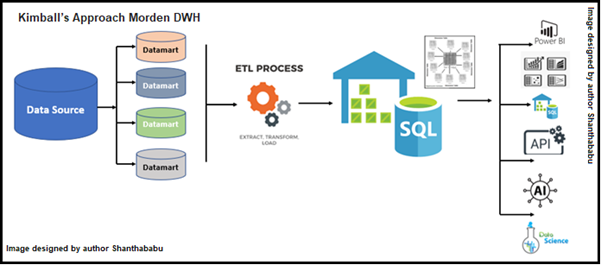
Let’s quickly go through Inmon DWH Modelling, it follows a top-down approach. In this model, OLTP systems are a data source for DWH and play as a central repository of data in 3NF. Followed by this Datamart is plugged in and in 3NF. Comparatively with Kimball’s model, this Inmon is not that great option while dealing with BI and AI and data provisioning.
| Kimball | Inmon |
| De-normalized data model. | Normalized data model. |
| Bottom-Up Approach | Top-Down Approach |
| Data Integration mainly focuses on Individual business-area(s). |
Data Integration focuses on Enterprise specific |
| Data source systems are highly stable since the Datamart stage will take care of the challenges |
Data source systems have a high rate of change Since DWH is plugged with the Data source directly. |
| Building time-lime takes less time. | Little complex and required more time. |
| Involves an iterative mode and is very cost-effective. | Building the blocks might consume a high cost. |
| Functional and Business knowledge is enough to build the model. |
Understanding of Database, Table, Columns and key relationship knowledge is required to build the model. |
| Challenge in maintenance | Comparatively easy to maintenance |
| Less DB space is enough |
Comparatively more DB space is required |
So far, we have discussed various data modelling techniques and their benefits around them.
Data Vault Model (DVM): What had discussed models earlier are predominantly focused on Classical or Modern Data Warehousing and Reporting systems. All we know now is we’re in the digital world delivering a Data Analytics Service to support enterprise-level systems like rich BI, Modern DWH, and Advanced Analytics like Data Science, Machine Learning, and extensive AI. This methodology is an agile way of designing and building modern, efficient and effective DWHs.
DVM is composed of multiple components like Model, Methodology, and Architecture, this is quite different from other DWH modelling techniques in current use. Another way around this is simply we can say that this is NOT a framework, product, and any service, instead, we can say this is Very Consistency, Scalability, highly Flexibility, easily Auditability, and specifically AGILITY. Yes! It is a modern agile way of designing DWH for various systems as mentioned earlier. Along with we can incorporate and implement the standards, policies, and best practices with the help of a well-defined process.
This model consists of three elements Hub, Link, and Satellite.
Hubs: This is one of the core building blocks in DVM. Which is to record a unique list of all the business keys for a single entity. Let’s say, for example, an It may contain a list of all Customer IDs, Employee IDs, Product IDs, and Order IDs in the business.
Links: Is fundamental component in a DVM is Links, which form the core of the raw vault along with other elements Hubs, and Satellites. Generally speaking, this is an association or link, between two business keys in the model. A typical example is Orders and the Customers in the respective table which is associated with customers and orders. And one more I can say store and employee working in store under various department so the link would be link_employee_store
Satellites: In DVM, Satellites connect to other elements in DVM (Hubs or Links). Satellite tables hold attributes related to a link or hub and update them as they change. For example, SAT_EMPLOYEE may feature attributes such as the employee’s Name, Role, Dob, Salary, or Doj. Simply say “The Point in Time Record in the table”. In simple language, we can say Satellites contain data about their parent Hub or Link and Metadata along with when the data has been loaded, from where, and effective business date details. Where the actual data resides for our business entities in the other elements discussed earlier (Hubs and Links).
In DVM architecture each Hub and Link record may have one or more child Satellite records, all the changes to that Hubs or Link.
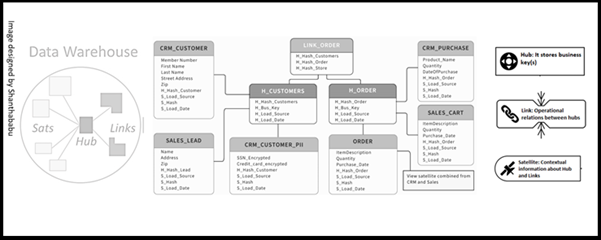
Source: image designed by author shanthababu
Pros and Cons
Pros
- This model tracks historical records
- Agile way of building the model as incrementally
- DVM use to provide the facilities of audibility
- Adaptable to changes without re-engineering
- The high degree of parallelism with respect to loads of data
- Supports the fault-tolerant ETL pipelines
Cons
- At a certain point, the models became more complex
- Implementation and understanding of Data Vault are a few challenges
- Since storing historical data capacity storage needed is high
- The model building takes time, so the value to the business is slower than another model
Conclusion
So far, we discussed data and modelling concepts in the below items in detail,
- What are OLTP and OLAP and their major difference?
- What is Data Modelling and what factors influence Data modelling?
- Discussed why the modern DWH is important for us? And various data availability, storage, maintainability, and IoT/ streaming data
- Data Model Evaluation and Data Modelling Components in depth
- Discussed various modelling techniques -Star Schema, Snowflake Schema, Kimball, Inmon, and Data Vault Model, and their components
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.