



{kind=link}
This article was published as a part of the Data Science Blogathon
“MuRIL is a starting point of what we believe can be the next big evolution for Indian language understanding. We hope it will prove to be a better foundation for researchers, startups, students, and anyone else interested in building Indian language technologies” said Partha Talukdar, Research Scientist, Google Research India.
What is MuRIL?
MuRIL, short for Multilingual Representations for Indian Languages, is none other than a free and open-source Machine learning tool specifically designed for Indian languages. Google’s Indian Research Unit has launched it in the year 2020. It helps to build local technologies in vernacular languages with a common framework.
What are all the languages it supports?
MuRIL currently supports the following 17 languages:
- Assamese
- Bengali
- English
- Gujarati
- Hindi
- Kannada
- Kashmiri
- Malayalam
- Marathi
- Nepali
- Oriya
- Punjabi
- Sanskrit
- Sindhi
- Tamil
- Telugu
- Urdu
Why MuRIL?
- The major objective was to make the internet convenient for regional languages in India and to improve the performance of certain downstream NLP tasks.
- Crucially aims at handling challenges related to Indian languages that include spelling variations, transliteration, etc.
- Makes it possible to train and transfer knowledge from one language to another.
What is it based on?
Google has trained the MuRIL tool using an existing language learning model called BERT (Bidirectional Encoder Representations from Transformers). BERT is right now being used to parse all English queries on Google’s search engine. Just grab a quick insight into how the BERT model works. This will be much helpful for you to understand the coding part 🙂
BERT is an open-sourced deep learning model designed specifically for resolving a wide variety of NLP tasks. This model is pre-trained to work on large text corpus and can be fine-tuned on those datasets as well. As the name suggests, the Bidirectional Encoder Representations from Transformers model
- is based on a Transformer architecture, and
- it doesn’t need a decoder part for its language representations.
The working of BERT architecture is just that simple! The input to the model is given in the form of tokens to the encoder then converted into vectors. Before these vectors are processed into the neural network, BERT also requires some amount of metadata at this step i.e. when you provide an input sentence to the encoder, there will be 3 sets of embeddings generated.
Token embeddings: provides a CLS token at the beginning of the first sentence and a SEP token (the separator token) at the end of each sentence.
Segment embeddings: It provides a token for each word in the sentences to differentiate them as sentence A or B or C,
Position embeddings: provides each input token with a unique positional token starting from zero to depict the position of words in the input sequence.
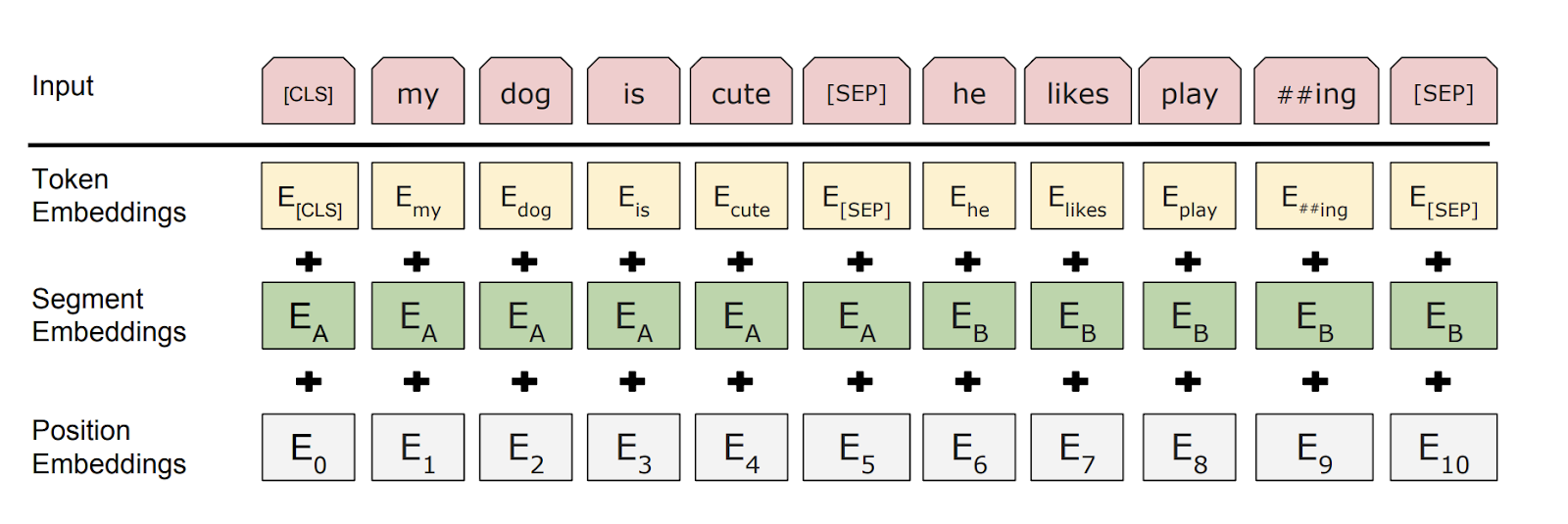
IMAGE LINK: https://drive.google.com/drive/folders/1-p5cPrA0_tXp2AyoS0XwbzYb1HB1Cst7?usp=sharing
Let us now experiment the same with Python!
Install these necessary libraries before importing them 😉
pip install bert-for-tf2 pip install tensorflow-text
Import libraries
import tensorflow as tf import tensorflow_datasets as tfds import tensorflow_hub as hub import tensorflow_text as text from bert import bert_tokenization import numpy as np from scipy.spatial import distance
The get_model function created here helps us download the MuRIL model from the Tensorflow Hub platform. This function accepts two inputs: the URL of the MuRIL model and the maximum
sequence length or the maximum number of tokens that can be imported at a time.
TensorFlow Hub is a repository of trained machine learning models ready for fine-tuning and deployable anywhere.
#function definition
def get_model(model_url, max_seq_length):
inputs = dict(
input_word_ids=tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32),
input_mask=tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32),
input_type_ids=tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32),
)
muril_layer = hub.KerasLayer(model_url, trainable=True)
outputs = muril_layer(inputs)
assert 'sequence_output' in outputs
assert 'pooled_output' in outputs
assert 'encoder_outputs' in outputs
assert 'default' in outputs
return tf.keras.Model(inputs=inputs,outputs=outputs["pooled_output"]), muril_layer
#function call
max_seq_length = 128
muril_model, muril_layer = get_model(
model_url="https://tfhub.dev/google/MuRIL/1", max_seq_length=max_seq_length)
A vocabulary file in the form of Numpy array and a full tokenizer for BERT are created here.
#converts input into BERT-acceptable format (preprocessing) vocab_file = muril_layer.resolved_object.vocab_file.asset_path.numpy() do_lower_case = muril_layer.resolved_object.do_lower_case.numpy() tokenizer = bert_tokenization.FullTokenizer(vocab_file, do_lower_case)
The next step is to create the metadata for the input sequence.
#the 3 types of embeddings in BERT
def create_input(input_strings, tokenizer, max_seq_length):
input_ids_all, input_mask_all, input_type_ids_all = [], [], []
for input_string in input_strings:
input_tokens = ["[CLS]"] + tokenizer.tokenize(input_string) + ["[SEP]"]
input_ids = tokenizer.convert_tokens_to_ids(input_tokens)
sequence_length = min(len(input_ids), max_seq_length)
if len(input_ids) >= max_seq_length:
input_ids = input_ids[:max_seq_length]
else:
input_ids = input_ids + [0] * (max_seq_length - len(input_ids))
input_mask = [1] * sequence_length + [0] * (max_seq_length - sequence_length)
input_ids_all.append(input_ids)
input_mask_all.append(input_mask)
input_type_ids_all.append([0] * max_seq_length)
return np.array(input_ids_all), np.array(input_mask_all), np.array(input_type_ids_all)
The encode function created here is obviously the final part of this experiment. It accepts the input string, creates the metadata, and is then passed into the MuRIL model.
def encode(input_text):
input_ids, input_mask, input_type_ids = create_input(input_text,tokenizer,max_seq_length)
inputs = dict(
input_word_ids=input_ids,
input_mask=input_mask,
input_type_ids=input_type_ids,
)
return muril_model(inputs)
Here, there is a list called sentences is being created for storing three Hindi words, where,
“दोस्त” (dost) means “Friend”
“मित्र” (mitr) means “Friend”
“शत्रु” (shatru) means “Enemy”
sentences = ["दोस्त", "मित्र", "शत्रु"]
This list is now passed into the encode function to get the final BERT representations of the words.
embeddings = encode(sentences)
Knowing the meaning of the three words specified in the list, let us check the distance between each of the words i.e. the first two words, “dost” and “mitr”, more or less means the same, meaning that the distance between these words in a high dimensional plane is as less as possible.
#calculating distance between 2 similar words
dst_1 = distance.euclidean(np.array(embeddings[0]), np.array(embeddings[1]))
print("Distance between {} & {} is {}".format(sentences[0],sentences[1],dst_1))
Output:
Distance between दोस्त & मित्र is 0.009007965214550495
Whereas the distance between the second and third words, “mitr” and “shatru”, seems comparatively higher.
#calculating distance between 2 dissimilar words
dst_2 = distance.euclidean(np.array(embeddings[1]), np.array(embeddings[2]))
print("Distance between {} & {} is {}".format(sentences[1],sentences[2],dst_2))
Output:
Distance between मित्र & शत्रु is 0.011569398455321789
Let’s check it out here and yay we are right! 😀
dst_2 > dst_1
Output:
True
End Notes
Look how amazingly MuRIL works in understanding the individual keywords! The BERT model is just doing wonders in understanding the context of the language being specified, this is much essential here as we already discussed that this model works on large volumes of data. And the best part is it doesn’t only work for the English language but also 16 other Indian languages.
Have a look at these interesting resources too! Happy Learning Y’all ;))
Resources
- https://neptune.ai/blog/bert-and-the-transformer-architecture-reshaping-the-ai-landscape
- https://jonathan-hui.medium.com/nlp-bert-transformer-7f0ac397f524
- https://arxiv.org/abs/1810.04805
- https://export.arxiv.org/pdf/2103.10730.pdf#view=fitH&toolbar=1
About Me
I am Lakshmi Panneer, a product of the 90’s. I hold a Master’s degree in Information Technology. Engineer by Profession. Blogger by Passion. I live in Chennai, TN. Over the years, I had been reading a lot of random stuff and write articles about it. Drop me a line anytime, whether it’s about feedback/suggestions, I’d really love hearing from you!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.