



This article was published as a part of the Data Science Blogathon
Introduction
I bet all of you might have been witness to a sports, music, or similar art practice session – what we are doing there is trying to emulate and train for the real world, for the real matches or events. When applied in the machine learning world you would also have wondered where we have made a machine learning model that is expected to do well based on historical data when applied to the real-world use case – what would be needed to make the model successful in real-world scenarios? How do we make sure it works? In this article, we shall delve into aspects of ML model implementation and use in the real world.
Let’s start with the basics:
Q. What do we build ML models?
A. To apply them for relevant problem-solving in the real world.
Q. Model Test Set Accuracy 90%! What next? How do we apply the ML models in the real world?
A. Through techniques Machine Learning operations (MLOps) techniques
As the model development conditions cannot always be the same as during implementation (just like a practice session is not the real match) there needs to be additional work done requiring knowledge beyond ML model design.
Post model development and testing there are a series of particularly important steps that applied data scientists should know in detail to enable end-to-end efficacy and validate the ML investment made by the organization. You might be already familiar with the process flow of model development, mentioned next is the entire cycle including deployment steps post modeling.
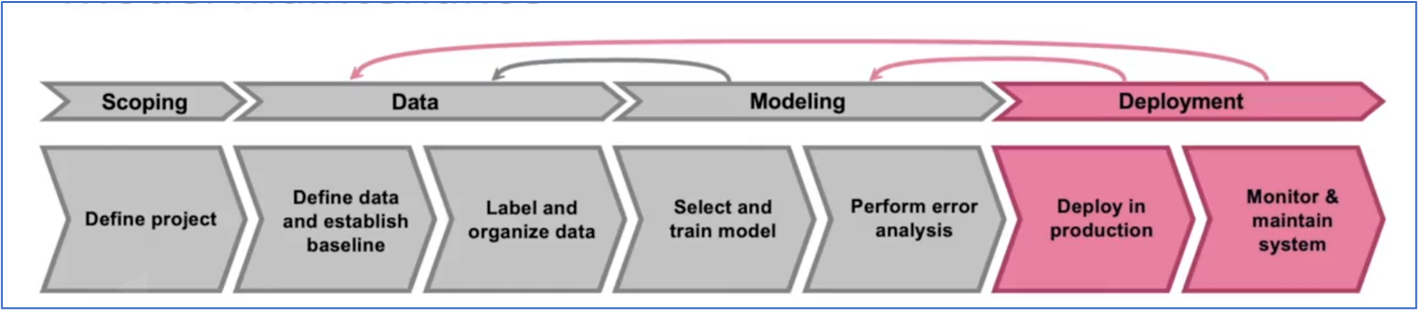
There are two parts of the model deployment step:
1. Setup the model in production (including end-user training)
2. Monitor and maintain the ML model as it generates predictions.
Now we shall delve into details…
1. Setup/deploy model in production
It involves choosing WHERE the ML code would reside and HOW predictions can be communicated to the end-use case.
Often the ML models are sub-parts of apps or software where the model code might only comprise 5-10% of the total code. Also, there might be more than one ML model deployed in the same app/software. Eg. Voice and Image search in Google. Another factor that you might find playing an important role here is batch vs. single (unit) predictions.
A. Where to deploy the ML production models?
I. Cloud deployment
II. Edge deployment (in the devices through which ML is delivered to end-users)
The below diagram explains them in more detail.
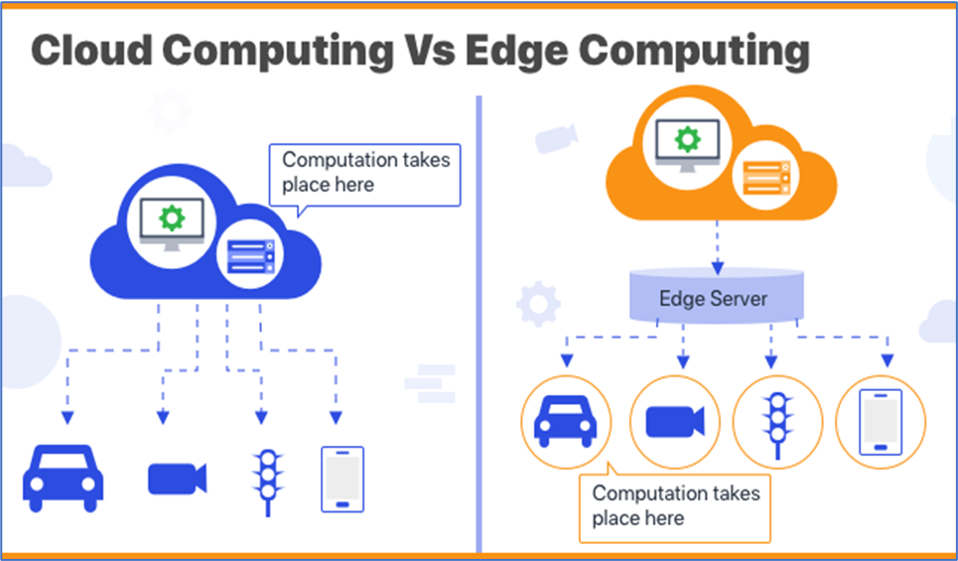
Source: https://www.akira.ai/blog/edge-computing-vs-cloud-computing/
The deployment location is decided based on the use case, Information security and the infrastructure support needed for the model, mentioned below are examples of edge and cloud deployment:
I. Cloud deployment – if you are running a website product recommendation model or trying to decide whether a loan is to be given to a customer or not then cloud deployment works as the systems need less latency and there are fewer chances of data being insecure. For models like image processing where extremely high processing is needed cloud can provide the computation power.
II. Edge deployment – A self-driving car would be a good example as well as a Covid- mask detection security cam would be another – the risks are too high to wait on the server to respond, there might be optimization needed to solve for computation needs of demanding ML applications as edge devices tend to have lower computation power.
B. How to deploy the ML models in production?
This has two parts:
I. How would humans be involved in the system, that is, degree of automation?
II. How to ensure performance in the deployment setup? Should we deploy and replace existing human/ systems at once or in phases – that is, deployment transition plans?
1.B.i. There is a spectrum of ML deployment for a completely manual system to full automation, IDC defines it per below 5 levels:
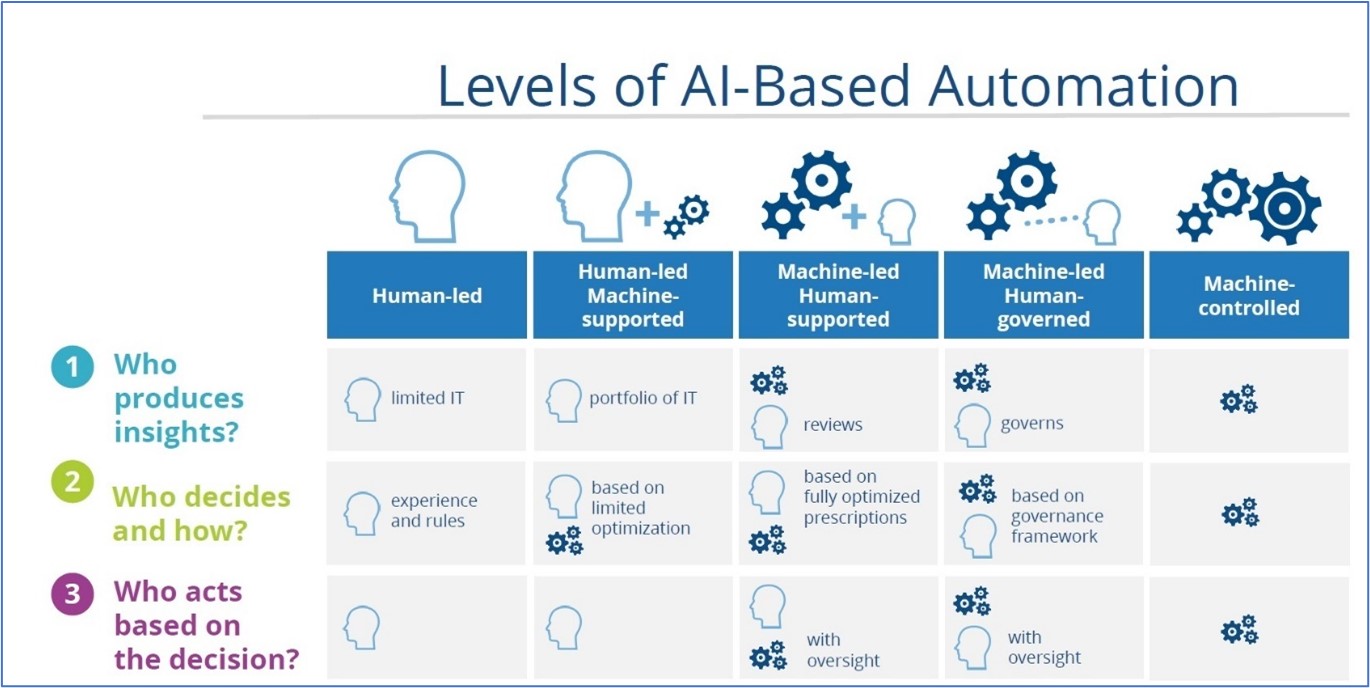
Source: https://www.pcmag.com/news/ai-a-slow-motion-explosion
Mentioned below are examples of each case, another point to note here is a softer skill- Socializing and training end-users who shall make/approve decisions based on the model is needed for some of these use cases:
– Human led this is where the system is completely controlled, and decisions are taken by human for example studying an X ray and providing the insights by a doctor sometimes there might be a shadow AI system running which does produce predictions but are only used if needed.
– Human led-machine supported – for example deciding this segmentation to be used in a marketing campaign and then using a model to find top customers in that segment to outreach in a limited budget.
– Machine led human supported: For example, our sales center contacting customers based on a recommendation and suggesting them products based on ML models.
– Machine lead human governed: Here humans review the machine output for example of fraud detection model where transactions decline is flagged as fraud can be reviewed by a human before final tagging as fraud.
– Machine controlled: This type is completely controlled by the machine without any human intervention for example product recommendation engine deployed on E commerce websites or video recommendation Indians deployed on OTT apps.
Examples of different levels of AI automation in driving a car
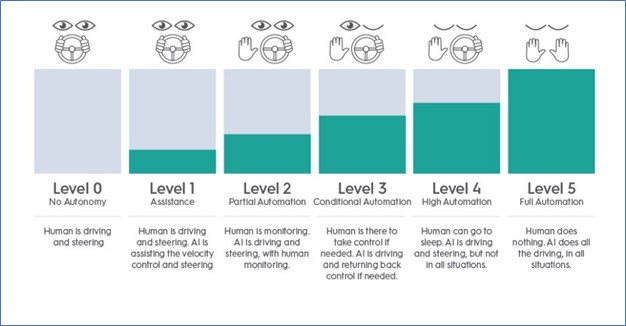
Source: https://applitools.com/blog/not-only-cars-the-six-levels-of-autonomous/
1.A.ii. Deployment Transition Planning Just like you divide the model into test and train, you can deploy ML models similarly say first on 10% of the cases. The rest 90% uses existing processes that are gradually ramped up based on performance. The other metrics to track would be used would be described in the following section. A deployment is mentioned below as an example (more here):
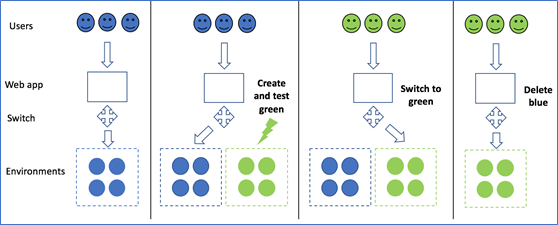
{kind=link}
2. Monitor and maintain the model deployment
This covers checking if the model is being applied in the right conditions (all model assumptions hold that were used in model design and testing) and if the software/ application/ platform running the model is working optimally.
A. What to monitor in the ML model scoring / Prediction process?
I. Concept drift
II. Data drift
2.A.i. Concept Drift – if something causes or it so happens the relation from XàY (in between dependent and independent variables) changes during the deployment, it would lead to concept drift. For example, during the coronavirus time, a lot of fraud detection systems started to fail and not perform because a huge segment of the population suddenly moved to online transactions for which these systems were not designed and they started mistaking them as fraud whereas they were genuine transactions because people were shopping online due to the lockdowns.
2.A.ii. Data Drift – It happens when the range of one or more X (independent) variables shifts compared to the modeling set. For Eg, if an image processing model were trained only in bright lighting conditions, it would not function well in a dark or dimly let condition.
For further reading there a good article here (https://towardsdatascience.com/machine-learning-in-production-why-you-should-care-about-data-and-concept-drift-d96d0bc907fb).
Apart from the above the native software/app in which the ML system is deployed also needs to be monitored.
B. How to monitor and manage ML model deployments?
I. Define KPIs/ metrics to monitor for the model deployment and visualize via a periodically updated dashboard
II. Model Adjustments / Retraining
2.B.i. Setting up ML deployed model monitoring

Source: https://www.coursera.org/learn/introduction-to-machine-learning-in-production/lecture/lRRnW/monitoring
Examples

Source: https://www.coursera.org/learn/introduction-to-machine-learning-in-production/lecture/lRRnW/monitoring
2.B.ii. Model adjustment / re-training
Sometimes during the model monitoring your metrics on the dashboard can show that the trends are going against what was expected, so there is data drift or concept drift or there is a lot of latency in the system, or have the number of errors in the model have increased!
It makes sense to go and address the problem that is causing the metrics to shift from the expected behavior while deployment for example if you see that the errors in predicting a certain class for the model have increased significantly you can go and collect additional data or retrain your model with the new data collected during deployment.
The model retraining step itself can be automated based on a threshold of the metric that we are monitoring.
Closing Thoughts:
In summary, after doing the hard work of creating an animal model that performs robustly on the test data there needs to be focus put on its application and deployment in the right way so that the model is useful for the purpose it was designed and can add value. So what we saw here is there are two steps in the model employment the setup of the model in the application or software where it’s to be deployed and then continuously monitoring it so that the performance is as expected the below diagram summarizes the articles takeaway:
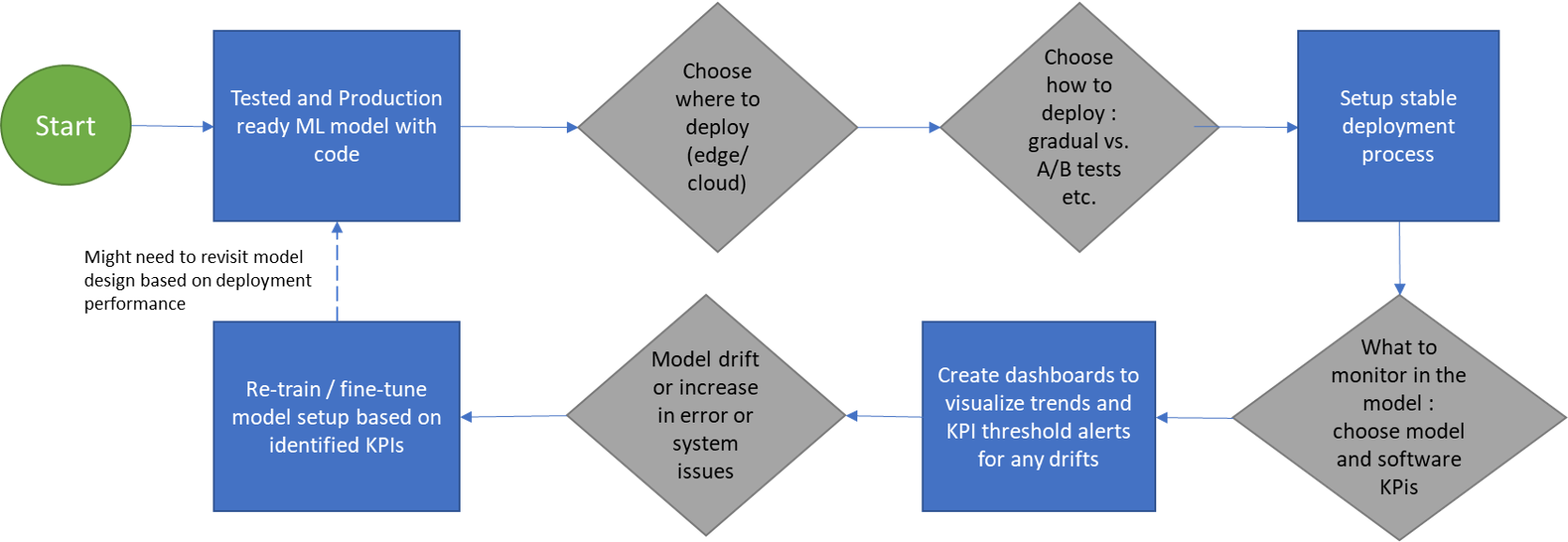
Source: Created by the Author
MLOps is an Iterative process – the first-time deployment is only halfway done, there is a lot of learning and just like ML model development the deployment is also an iterative process and might take continuous improvement to keep robustly helping in the problem solving for the use case it was applied to. Based on performance metrics it has to be refined and retuned.
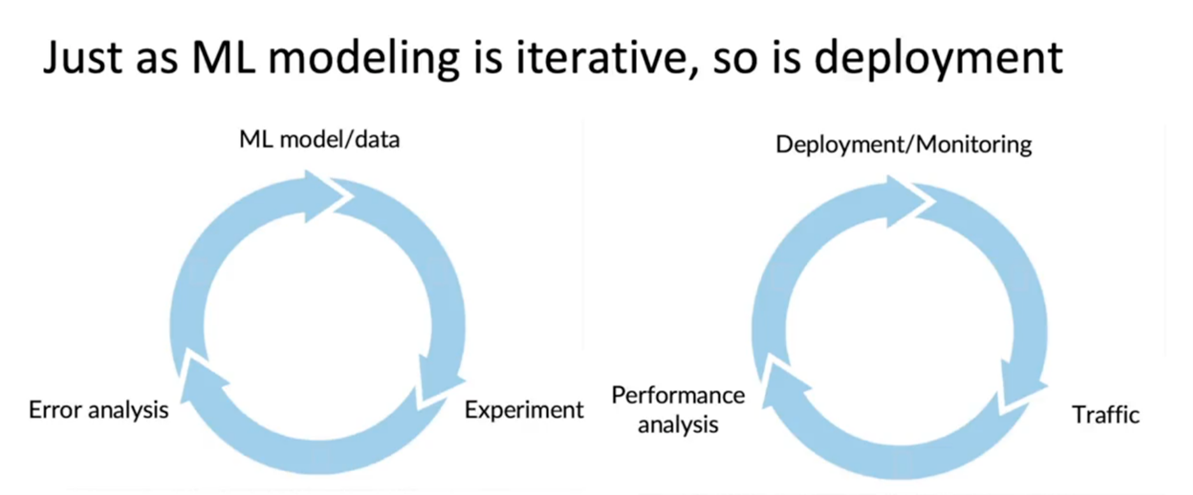
Source: https://www.coursera.org/learn/introduction-to-machine-learning-in-production/lecture/DugTF/deployment-patterns
Further reads (Code example for the deployment of DL model) – https://github.com/https-deeplearning-ai/MLEP-public/blob/main/course1/week1-ungraded-lab/README.md
References:
https://www.coursera.org/learn/introduction-to-machine-learning-in-production/home/welcome
https://www.akira.ai/blog/edge-computing-vs-cloud-computing/
https://www.pcmag.com/news/ai-a-slow-motion-explosion
https://applitools.com/blog/not-only-cars-the-six-levels-of-autonomous/
https://christophergs.com/machine%20learning/2020/03/14/how-to-monitor-machine-learning-models/