



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Companies are trying to disrupt the technological and business market by introducing new and smart products and techniques in society by adopting new age-technologies like Artificial intelligence and Machine learning. Each organization is searching for well-talented and experienced people who can serve them on their demands. Today data scientists, data analysts, machine learning engineers, and computer vision engineers are more in-demand organizational roles. If you wish to apply and grab a job in the tech domain, it’s crucial to know common machine learning interview questions that recruiters ask.
The article covers some popular machine learning interview questions that will force you to think one step ahead of your knowledge, and you will like to encounter and achieve your dream job.
Table of contents
- Introduction
- Machine Learning Interview Questions
- Q1. What is the difference between Parametric and non-parametric ML algorithms?
- Q2. What is the difference between Convex and non-convex loss functions? What happens when we have a non-convex cost function?
- Q3. How do you decide when to go for deep learning for a project?
- Q4. What is the difference between False positive and False Negative? Give a scenario where a False positive is more important than a False Negative and vice-versa.
- Q5: What is naive in the Naive Bayes algorithm?
- Q6: Can you give an example of Where the Median is better to measure than the mean?
- Q7: What do you mean by unreasonable effectiveness of data in ML?
- Q8 : What is a lazy Learning algorithm? How is it different from eager learning? Why is KNN a lazy learning machine learning algorithm?
- Q9: What is semi-supervised Machine Learning?
- Q10: What is an OOB error, and how is it useful?
- Q11: In what scenario would you prefer a decision tree over a random forest?
- Q12: Why is logistic regression called regression, not logistic classification?
- Q13: What is online machine learning? How is it different from offline ML? List some of its applications.
- Q14: What do you mean by ‘No Free Lunch’ in Machine Learning?
- Q15: Imagine you are working with a laptop with 4GB RAM. How will you process the dataset of 10GB?
- Q16: What is the difference between structured and unstructured data?
- Q17: What are the main points of difference between Bagging and Boosting?
- Q18: What are the assumptions of Linear Regression?
- Q19: What are Correlation and covariance?
- Q20: Explain the Bias-vari ance trade -off.
- Conclusion
Machine Learning Interview Questions
Below listed questions will enhance your job-interview skills in Machine Learning and prepare you for future job interviews.
Q1. What is the difference between Parametric and non-parametric ML algorithms?
Answer: The machine learning algorithm is a function. Whenever you assume the function of the data, then it is a parametric machine learning algorithm. Linear regression is a good example of a parametric machine learning algorithm because while using Linear regression, you assume that the data you are using is linear, so the function will be a straight line.

Hence you can define a parametric ML algorithm whenever you assume the nature. That kind of algorithm is a parametric ML algorithm. To contradict it, when you do not make any assumption about the nature of the algorithm, it is a non-parametric ML algorithm.
- Another difference is parametric ML algorithm has a fixed number of parameters, and it does not depend on the number of rows present in your data. It means if several parameters do not grow concerning several rows in your data, it is a parametric algorithm. If parameters grow, then it is the non-parametric algorithm.
- Most people think that the non-parametric algorithm does not have any parameters then. It is wrong because they have parameters that change the behavior and number of rows in data.
- Examples – linear regression, logistic regression, Linear SVM, and Naive Bayes are parametric Machine learning algorithms. In contrast, KNN, Other SVMs, Decision trees, random forests, and boosting algorithms are non-parametric algorithms.
Q2. What is the difference between Convex and non-convex loss functions? What happens when we have a non-convex cost function?
Answer: In machine learning, a loss function measures how far the estimated value is from the true value (original – predicted). So, the loss function is a value that explains the machine learning model’s performance. A loss function is nothing but a mathematical function, and it must have a graph.
In the convex function, the graph should not lie above the drawn line on a graph, or the graph should have a single slope where no local minima are present in the non-convex function; the graph or curve passes above the line, then it is a non-convex function.
When we have a non-convex loss function, then there is a problem because it can have more than one minimum, so your optimization algorithm, for example, gradient descent, is not able to find the global minima because most of the time, it gets stuck in local minima and does not converge. Hence, you cannot find the best-optimized solution for defined parameters.
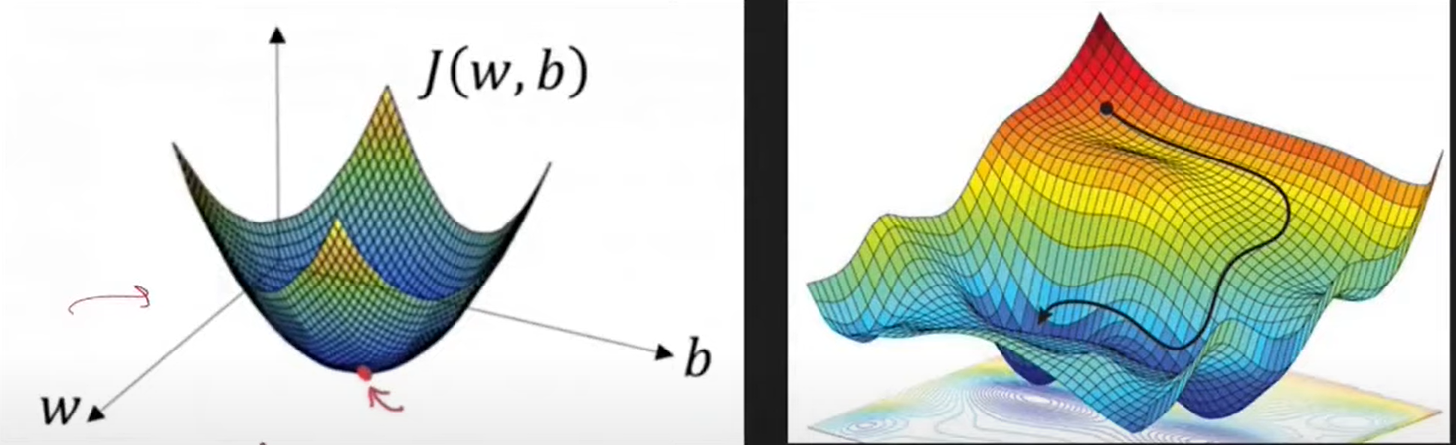
The above diagram shows that the first figure is a convex function where only one global minimum is there and no local minima. The second figure concerns the complex neural network that reflects many local minima and one global minimum.
Q3. How do you decide when to go for deep learning for a project?
Answer: This is one important question that the interviewer asks you to understand the working of Machine learning and deep learning. So to answer this project, you should keep two points in front of the interviewer the factors for which you will perfect deep learning and the factors that go against deep learning while choosing it for a project.
Favor points to choosing Deep learning
- Performance – The performance of deep learning is improving compared to ML algorithms. You will choose deep learning when accuracy or performance is preferred, like in the healthcare domain.
- Complexity – The problem with which you are dealing is more complex where you do not have any domain knowledge so you choose deep learning over complex data. For example, where you are asked to answer while observing a picture that it is a cat or dog, deep learning can implement rules, while in machine learning, we cannot build hand-crafted rules.
Against points to not choosing deep learning
- Data – If you are working on a project where you do not have any long-format data, then you will not choose deep learning because deep learning is hungry for data.
- Cost – It can be hardware cost where to train deep learning model you need GPUs which are very costly. So you need to buy them o rent them from any cloud like AWS.
- Interpretability/ Explainability – suppose you built one model, and your client asks you to explain how the model works in the background and answer the points. So this cannot happen because the interpretability of the deep learning model is zero because they are created in hidden layers, and we cannot find them.
Q4. What is the difference between False positive and False Negative? Give a scenario where a False positive is more important than a False Negative and vice-versa.
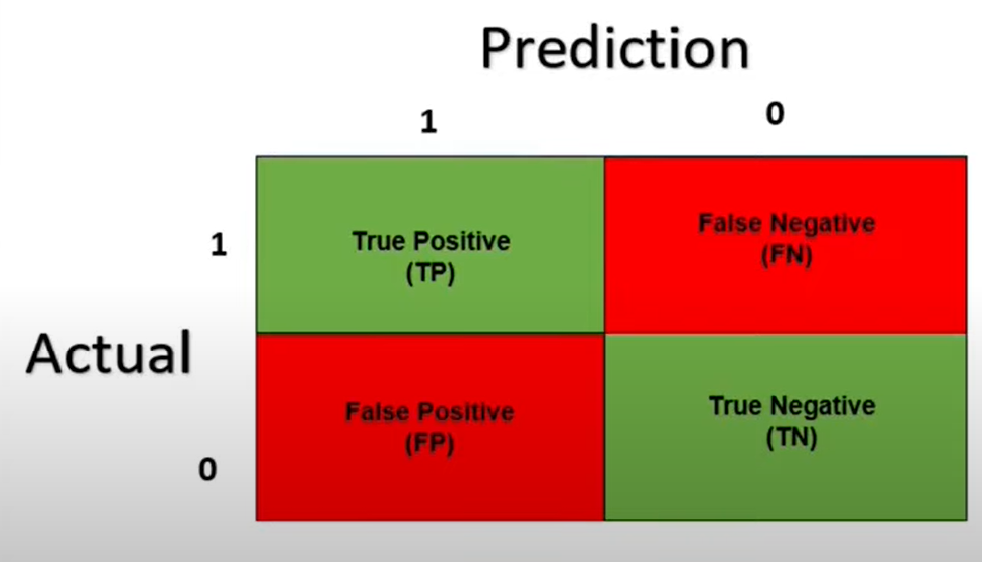
Whenever we build any machine learning model, then, during testing, there can only be 4 cases represented in the below diagram.
It is known as a false negative when the actual value is positive and the predicted value is negative. When the actual value is negative and the predicted value is positive, it is known as a False positive.
Example – Suppose you build an email classification, and there can be 2 types of mistakes that the model can make. When mail is span, and it says not-span, which is a False negative. Another is when mail is not-span, and it says span, which is a False positive. In this case, a False positive is more crucial because when the mail is not spanned, that can contain some confidential data, and it says as span, then it is dangerous.
While assuming the scenario where we build a covid detection system where the person is infected and the system results as not infected, which is a False-negative, it is more crucial to leave an infected person freely, which can harm others.
Q5: What is naive in the Naive Bayes algorithm?
Naive Bayes is a popular machine learning algorithm that works on the Bayes theorem. Naive means innocent (simple). It is a supervised machine learning algorithm where you have many independent columns and one output column. Also, naive input columns are independent, and in normal, the data have some relationship, but the naive Bayes does not assume this. For its work, there must be no relationship between input columns.
Q6: Can you give an example of Where the Median is better to measure than the mean?
You should know about mean and median if you have read basic descriptive statistics. The mean is the average of all the observations (total sum divided by a total number of observations). The Median is the center number obtained after sorting all the observations. Both measures show the central tendency of the data. So when we have outliers in data, using the mean in this condition is not recommended.
For example, we have a dataset of several students with annual packages. All the students got the package between 3 to 6 LPA, but 2-3 students have packages as 25LPA, and 38LPA, and when we are asked to give an average class package, then the mean will be a huge number which is wrong in this case. So better to use Median in such types of cases.
Q7: What do you mean by unreasonable effectiveness of data in ML?
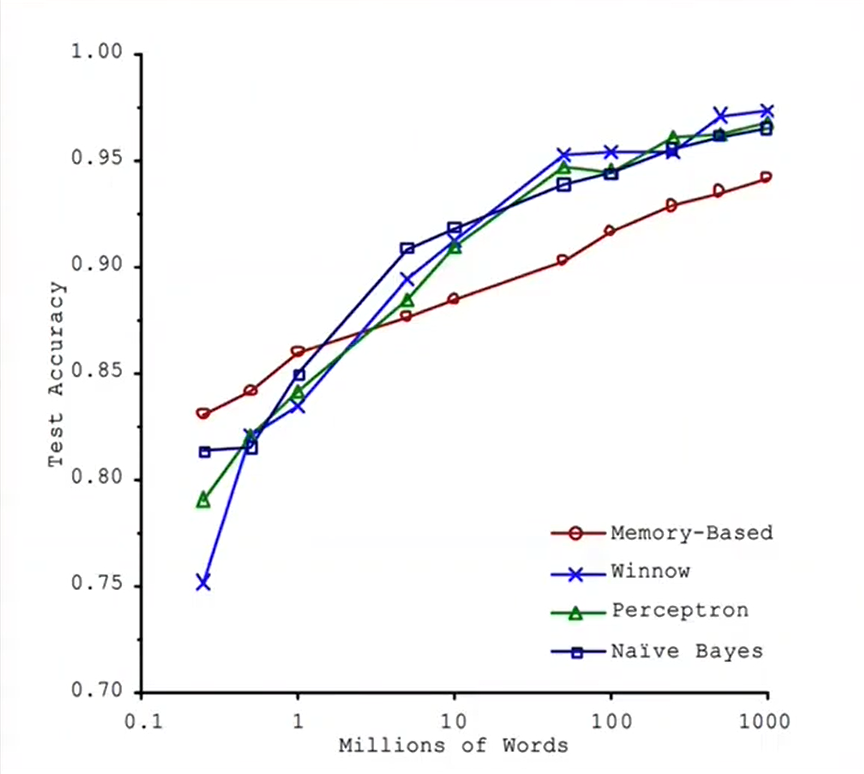
This is a rarely asked question but very important to understand. According to research and practical performance on different machine learning algorithms, It is stated that if the number of data increases, then the weal ML algorithms also perform better. It simply means that if you do not focus on the algorithmic part and invest unlimited money and time in corpus building, then any algorithm will generate good results, which is called the unreasonable effectiveness of data.
In practically also we observe any machine learning problem statement then different algorithm gives different performance below graph also reflects that but the power of data changes all the scenario.
Q8 : What is a lazy Learning algorithm? How is it different from eager learning? Why is KNN a lazy learning machine learning algorithm?
Lazy learning algorithms are the learning algorithms that do not learn in the training phase and perform the action (learning) in the prediction phase when they receive queries. Indeed the eager learning algorithms learn during the training phase or generate a function of input and output during training.
- Lazy learning stores the training data while eager learning does not.
- Training in lazy learning is speedy, while in eager learning, training is very slow.
- Predictions are slow in lazy learning algorithms, while in the case of eager learning, predictions are fast.
- An example of lazy learning is KNN, and eager learning is decision tree, SVM, and naive Bayes. Very few algorithms fall into lazy learning algorithms.
KNN comes under a lazy learning algorithm because It stores the data first, and when any new query arises, it finds the distance of the new data point to all other data points and the 3 nearest data points. Among the 3 data points, it does a majority count (voting), and the class with a majority count is the resultant prediction. In this entire process, the KNN starts working when it receives the query, and before this, it does nothing.
Q9: What is semi-supervised Machine Learning?
If you have learned about types of machine learning, then we always hear 3 types supervised, unsupervised, and reinforcement, but there is one more type known as semi-supervised machine learning. Semi-supervised simply means it is partially supervised and partially unsupervised. Achieving the output columns (labels) is costly and time-consuming because it requires human effort. At the initial level to prepare the dataset, any human needs to sit to provide the labels. So some researchers think that the limited amount of data and the remaining amount should be automatically labeled. This is the core idea behind semi-supervised learning.
For example, google photos that use semi-supervised machine learning where I want to label photos. Hence, one photo I identified and similar photos will be labeled with the same label.
Q10: What is an OOB error, and how is it useful?
OOB stands for out-of-bag evaluation. Whenever we use the bagging algorithm for training purposes, then it selects the samples using sampling with the replacement method. This method selects multiple rows in a sample, and some are left unselected in any sample, known as out-of-bag rows. We can use these rows as test data without creating external test data, known as out-of-bag evaluation.

Q11: In what scenario would you prefer a decision tree over a random forest?
The question can be asked to check your practical knowledge of machine learning. A decision tree is a simple algorithm that works on an ID3 or CART basis. And a collection of multiple decision trees is a random forest. If we talk more practically than in most datasets, the random forest performs better than the decision tree. But there are some points where a decision tree is more useful than a random forest.
- Explainability – Always, you do not need performance, but you also need to explain the work and solution. And when you solve any problem with a decision tree, you get a proper tree-like structure that explains the complete tree-building process, and you can easily discuss the model’s working with the client and manager.
- Computation power – If you have less computation power, you can go with a decision tree.
- Useful Features – This is a practical use case when you have some handy features that you want should use on priority then, a decision tree is helpful because, in a random forest, features are selected at random.
Q12: Why is logistic regression called regression, not logistic classification?
The logistic regression works closely with the linear regression model. The only difference is you use the sigmoid function in output and calculate probability, and using a threshold gives the result as 0 or 1. The regression is so called because it calculates a constant value probability. When we calculate the continuous value, it is called the regression algorithm, so the logistic algorithm is called the regression algorithm.
Q13: What is online machine learning? How is it different from offline ML? List some of its applications.
Most companies promote their products with the common tagline that says the more you use our product, the more intelligent it gets. So their intention is toward online machine learning. First, let us understand batch machine learning (offline ML). In batch machine learning, you have a data set, train an ML model on the entire data and deploy the model on the server. After that, if you want to make certain changes, you will bring down the model, make the changes, and deploy it again. This is offline or batch machine learning.
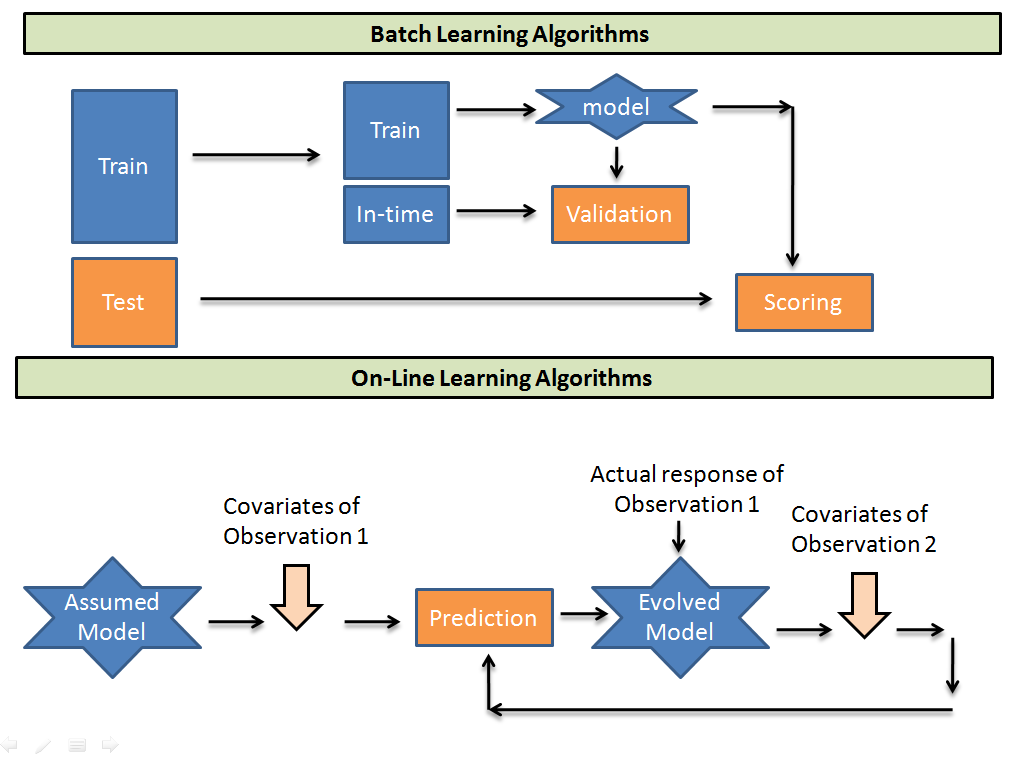
Online machine learning is the type of learning where model training happens on the server. It is also known as incremental learning. It means that as it gets new data, it performs two tasks: first, it predicts the outcome, and second, it gets trained on new data. Using this, the model performance slowly gets improves with time. The best example of online machine learning is a recommendation system. Youtube is a great example of how the feed changes if you watch any video and return to the home page
Q14: What do you mean by ‘No Free Lunch’ in Machine Learning?
It is one interesting question, and this is one theorem in Machine learning. In 1996, well-known computer scientist David Polpert published a paper containing the No Free Lunch Theorem. According to this theorem, if you do not make any assumptions about ML models, then you cannot tell which type of data which ML model should I pick.
Q15: Imagine you are working with a laptop with 4GB RAM. How will you process the dataset of 10GB?
This is an important question when you prepare for ML interviews because it checks your practical knowledge about handling a massive amount of data. So there are 3 methods that you can use in this kind of scenario.
- Sub-sampling – It means reducing the size of data. In this method, you take a sample of the required size that the machine can support and work on it. But this is not a good solution because using this; you cannot create a good model due to loss of information.
- Cloud-computing – We can rent an online server like AWS, Azure, GCP, etc. This server allows you to upload massive data, but the cost is the problem with this method. The computing services through cloud computing platforms are costly.
- Out of core ML – The word originated from core memory (RAM or external memory). It is a way to train your model on data that cannot fit on your RAM. It is a way to apply machine learning to the data that cannot fit on your RAM. It is performed in three steps defined below.
- Stream Data – You bring the data from the source to RAM in small chunks. As you bring the first chunk, process it and delete it, bring the second chunk, process, and delete. This process goes on till you process complete data.
- Extract Features – We extract features to train the ML model.
- Model training – The concept of incremental learning is used where you train an ML model on one chunk and, after that, on the second chunk, and so on. This feature is only supported by ML algorithms that support partial fit features or parameters. The algorithms like SGD regressor, Naive Bayes, Mini-Batch KNN, etc.
Q16: What is the difference between structured and unstructured data?
The data you receive in machine learning is of two types structured and unstructured.
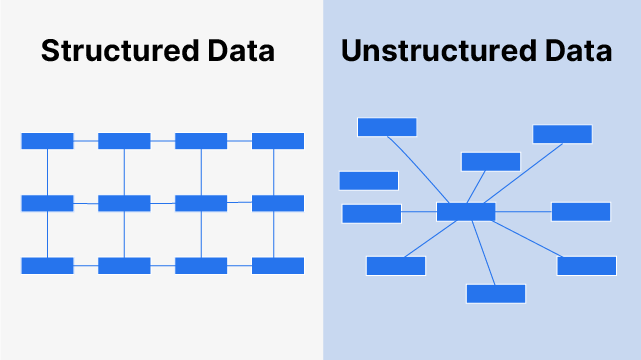
Structured – Data in the tabular form is known as structured data. If we say tabular, the data collects many rows and columns. Data in excel sheet format are structured data. In structured data, you will always find text inside the columns. Searching in structured data is simple. Traditional ML algorithms are easily applicable to structured data. Structured data is mainly used in the Analytics domain.
Unstructured Data – Unorganized data contains different types of files like images, audio, video, GIFs, text files, etc. Search becomes difficult in unstructured data. Here mainly deep learning techniques are used. Unstructured data is used in NLP, text-mining, and computer vision.
Q17: What are the main points of difference between Bagging and Boosting?
Mostly High, performing models in machine learning are obtained from Bagging or boosting. In most of the interviews, the question is raised to the candidate to list the main point of difference between both the techniques. Ensemble learning came into the market because we want a model with low bias and variance. Still, each ML single model produces a combination of low bias and high variance. We will discuss 3 main points of difference to answer the question correctly and accurately.
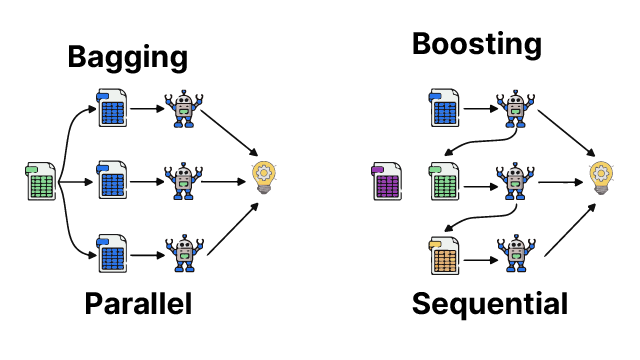
- Type of model used – In bagging, the model which we use is a combination of low bias and high variance, like a fully grown decision tree. While in boosting, the combination used is high bias and low variance like a shallow grown decision tree. So if you have that ML model which is good on training data but not good when there are changes in data, we will go for Bagging. We have an algorithm that is not good for training data but does not affect data change. Then we go for Boosting.
- Sequential Vs. Parallel – Bagging stands for bootstrap aggregation, meaning we have multiple models from the same ML algorithm, and we take a sample from the data. Each model gets one sample where the model’s training happens at a time in a similar way. While in boosting, the model learns in a sequential way which means the first model train, then the second receives an error of the first and works on sequential learning.
- Weightage of Base Learner – In bagging, the weightage of all models are same. While in boosting, each model has its weight, or different model has different weights
Q18: What are the assumptions of Linear Regression?
This is a very important and basic machine learning question. The interviewer will always start asking you questions from linear regression and make an approximate judgment of your practical knowledge. Below are the 5 main assumptions of linear regression.
- Linear Relationship between input and output – Linear relationship means if one increases, the other should also increase or vice-versa. Linear regression assumes that the input and output are linear dependents on each other.
- No Multicollinearity – Multicollinearity means that all the input columns you have in data should not be highly related. For example, if we have X1, X2, and X3 as input columns in data and if by changing X1 there are changes observed in X2, then it is the scenario of multicollinearity. For example, if by changing X1, we get output keeping that X2 and X3 are constant, but when X1 is correlated to X2, then on changing X1, X2 will also change, so we will not get proper output. That’s why multicollinearity is a problem.
- Normality of Residual – When we predict new data points and calculate error or residual (actual – predicted), then on plotting, it should be normally distributed across the mean. To know this, you can directly plot the KDE or QQ plot. First, you have to calculate the residual for every test point, and using the seaborn library; you can plot a distribution plot. The second way is to directly Plot a QQ plot where all points should be closer to the line.
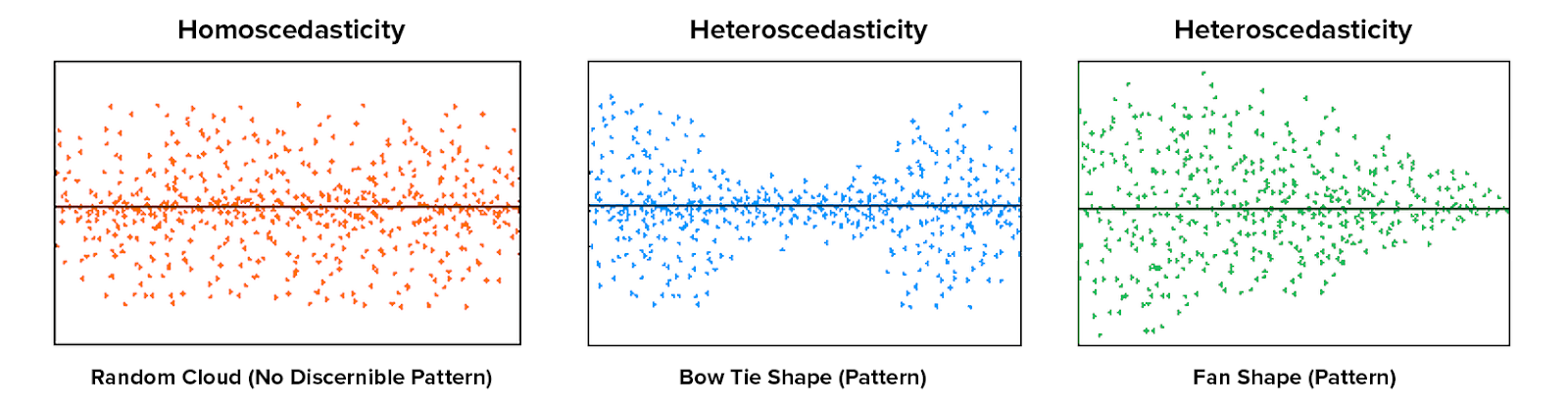
- Homoscedasticity – Home means same, and scedasticity means to spread or scatter. So this means having the same scatter. According to this assumption, when you plot residual, then the spread should be equal. If it is not equal, then it is known as Heteroscedasticity. To calculate this, you keep prediction on X-axis and residual on Y-axis. The scatter plot should be uniform.
- No Autocorrelation of Errors – If you plot all residual errors, then there should not be a particular pattern.
Q19: What are Correlation and covariance?
Correlation describes the relationship between two strongly positive or negative correlated variables. It is used to figure out the quantitative relationship between two variables. Examples like income and expenditure, demand and supply, etc.
Covariance is a simple way to calculate the correlation between two variables. The problem with covariance is that they are hard to compare without normalization.
Q20: Explain the Bias-variance trade-off.
Bias and variance are both a type of errors that ML algorithms reflect. Bias occurs due to the simplistic assumption of the machine learning algorithm. When the model does not perform well on training data, then the model is reflected as high bias or the condition of underfitting occurs.
Variance is an error that occurs due to the complexity of the algorithm. When the algorithm cannot predict approximate results on new data or tries to overfit the model, we have a high variance combination.
We need to trade between bias and variance to reduce the error optimally.
Conclusion
Machine learning is a vast field, and everything is connected. In this article, we have covered some practical-based questions that check your practical and research knowledge about algorithms. When diving into machine learning interview questions, it’s crucial to understand how each algorithm works. While using each algorithm, you observe its behavior and analyze the outcomes. These questions aim to assess your hands-on experience and problem-solving skills in the realm of machine learning. Let us conclude the article with key takeaways that will help you prepare better for ML jobs.
- The recruiter or organization does not expect you should know each algorithm. They want the basic knowledge of algorithms and expertise in some of them in a category where you hold practical experience.
- Always prepare those materials in a better way which you have used in a project, and the algorithm with which you have been working for the past few months.
- Do not try to mesmerize the working of an algorithm but rather understand it because many ML practitioners try to mesmerize it during interview preparation. The recruiter will try to understand working both mathematical and practical working. So only implementation is not enough. You can mesmerize some of the required formulas.
- When you prepare the algorithm, do not miss out on finding the pros and cons of the algorithm, like what is efficient use and in what scenarios this will work or not work because this type of question will only help to clear interviews in one go.
Thank You Note
- I hope it was easy to cope with each step and understandable. If you have any queries, please post them in the comment section below or connect with me.
- Connect with me on Linkedin.
- Check out my other articles on Analytics Vidhya and crazy-techie
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a final year undergraduate who loves to learn and write about technology. I am a passionate learner, and a data science enthusiast. I am learning and working in data science field from past 2 years, and aspire to grow as Big data architect.