



Introduction
The next post at the end of the year 2017 on our list of best-curated articles on – “Machine Learning”. These curated articles will be a one stop solution for people who are getting started with Machine Learning or who already have. This article contains all the best articles of 2017 which gathered the interest of the Machine Learning community.
Similar to the previous article on -“Best Deep Learning articles in 2017”, I have added the used tool and the level of difficulty for each article to facilitate you with the choice. If you wish to include any other learning resource/article here, please mention them in the comments.
Top 11 Machine Learning articles from Analytics Vidhya in 2017
Ultimate Guide to Understand & Implement Natural Language Processing (with codes in Python)
 A large amount of unstructured data present today is in the form of text, for example : Medical documents, legal agreements, tweets, blogs, newspapers, chat conversions etc. These text informations are the storehouse of new innovative products that can revolutionise the way we interact with the technology and live our lives. A few of the examples are:
A large amount of unstructured data present today is in the form of text, for example : Medical documents, legal agreements, tweets, blogs, newspapers, chat conversions etc. These text informations are the storehouse of new innovative products that can revolutionise the way we interact with the technology and live our lives. A few of the examples are:
- An automated system which can go through your medical records to suggest which kind of food you should avoid.
- An automated system which can go through a legal document to check its validity.
- A chatbot which can help you in buying groceries to booking a cab just by typing over a phone.
This is just the tip of the iceberg for what is possible if Natural Language is exploited.
This article explains the basic concepts behind Natural Language Processing such as Text Processing, Feature Extraction from text etc. along with their codes in Python.
This is a must read article for someone getting started into the field of Natural Language Processing.
Tool: Python
Level: Beginner
Introduction to Gradient Descent Algorithm (along with variants) in Machine Learning

Machine Learning has been with us since a long time ago, but it picked up pace about a decade back, part in thanks to the advancements in the hardware and in part to the Algorithms.
This article is about one such Algorithm which is extremely popular in the field of Machine Learning – Gradient Descent. This article explains in detail about how Gradient Descent works, the problems in the original Gradient Descent and the variants of Gradient Descent for overcoming the problem along with the implementation.
Level: Intermediate
A comprehensive beginners guide for Linear, Ridge and Lasso Regression

An operations manager working at a Supermarket chain in India knows about the amount of preparation the store chain needs to do before the Indian festive season (Diwali) kicks in. It is for them to estimate/predict which product will sell like hotcakes and which would not prior to the purchase. A bad decision can leave your customers to look for offers and products in the competitor stores. The challenge does not finish there – he also needs to estimate the sales of products across a range of different categories for stores in varied locations and with consumers having different consumption techniques. This article tells you everything you need to know about regression models and how they can be used to solve prediction problems like the one mentioned above.
Tools: Python
Level: Intermediate
Natural Language Processing Made Easy – using SpaCy ( in Python)

There are many libraries out in the industry which provides methods for exploiting the text data to make sense out of it. Some of the examples being like Stanford CoreNLP, NLTK etc. and Python has been the go-to choice for working with text data.
But these libraries lacking in the sense that they are bulky and with too much overhead like NLTK which downloads thousands and thousands of files for performing any NLP task.
This is where SpaCy comes in – an industrial grade superfast NLP library which can perform almost all the NLP tasks with the breeze. This article makes you aware of the syntax of SpaCy and teaches you to perform some very common NLP tasks like PoS tagging, NER etc with minimal lines of code. The article also introduces the concept of Word vectors which are currently the state-of-the-art in features extracted from the text.
Tools: Python
Level: Intermediate
How to build Ensemble Models in machine learning? (with code in R)

If you are an active participant in the Data Science Competitions or have just started participating in the competitions and have gone through the solutions of the winners, you will notice that most of them use a blend of different models to extract that last drop of performance from the models.
This blend of models is what is called – Ensemble Learning, where you combine the learnings of different models to create a better-learned model. In this article, you will learn about the different Ensembling techniques along with how you can code them up in R to ace your Data Science Competitions.
Tools: R
Level: Intermediate
Which algorithm takes the crown: Light GBM vs XGBOOST?
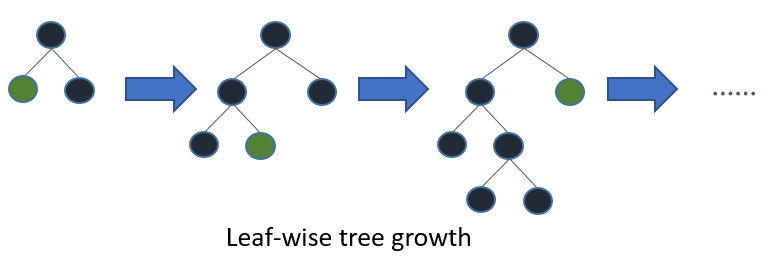
For active members of the Data Science Competitions, XGBOOST almost became the go-to algorithm for performance and winning the competitions. It has the best of both the boosting machines and regularised methods.
But it suffers from one problem: Given a huge amount of data, it takes a very long time to train. This is where LightGBM comes in.
This article explains about LightGBM and compares it with XGBOOST in terms of performance and speed. This article is a must for people looking to reduce their training time in the competition without losing on the performance of the model.
Tool: Python
Level: Expert
Tutorial to deploy Machine Learning models in Production as APIs (using Flask)

We as data scientists and machine learning engineers spend a lot of time trying to come up with the best performing model for solving a problem and most of the time we do get successful. But all these investments of time and mind will become useless if do not put the model in the real life.
For example, an algorithm that can detect cataract just by looking at a photo is useless if the end user or person with cataract cannot input the image into the model. After all, models are created to solve a problem. Running a model shouldn’t be a problem for an end customer.
This is where this article comes in. This article explains how you can deploy a machine learning model and use it to solve problems.
Tools: Python
Level: Expert
Comprehensive Tutorial to Learn Data Science with Julia from Scratch
![]()
There is a quote about Julia that says – “Walks like python. Runs like C.”
The above line tells a lot about why creating ripples in the numerical computing space, even though it was in its early stages. Julia is a work straight out of MIT, a high-level language that has a syntax as friendly as Python and performance as competitive as C. This is not all, it provides a sophisticated compiler, distributed parallel execution, numerical accuracy, and an extensive mathematical function library.
This article is about how can you utilize it in your workflow as a data scientist without going through hours of confusion which usually comes when we come across a new language.
Tool: Julia
Level: Beginner
CatBoost: A machine learning library to handle categorical (CAT) data automatically

You have seen below error while building your machine learning models using “sklearn” – at least in the initial days.
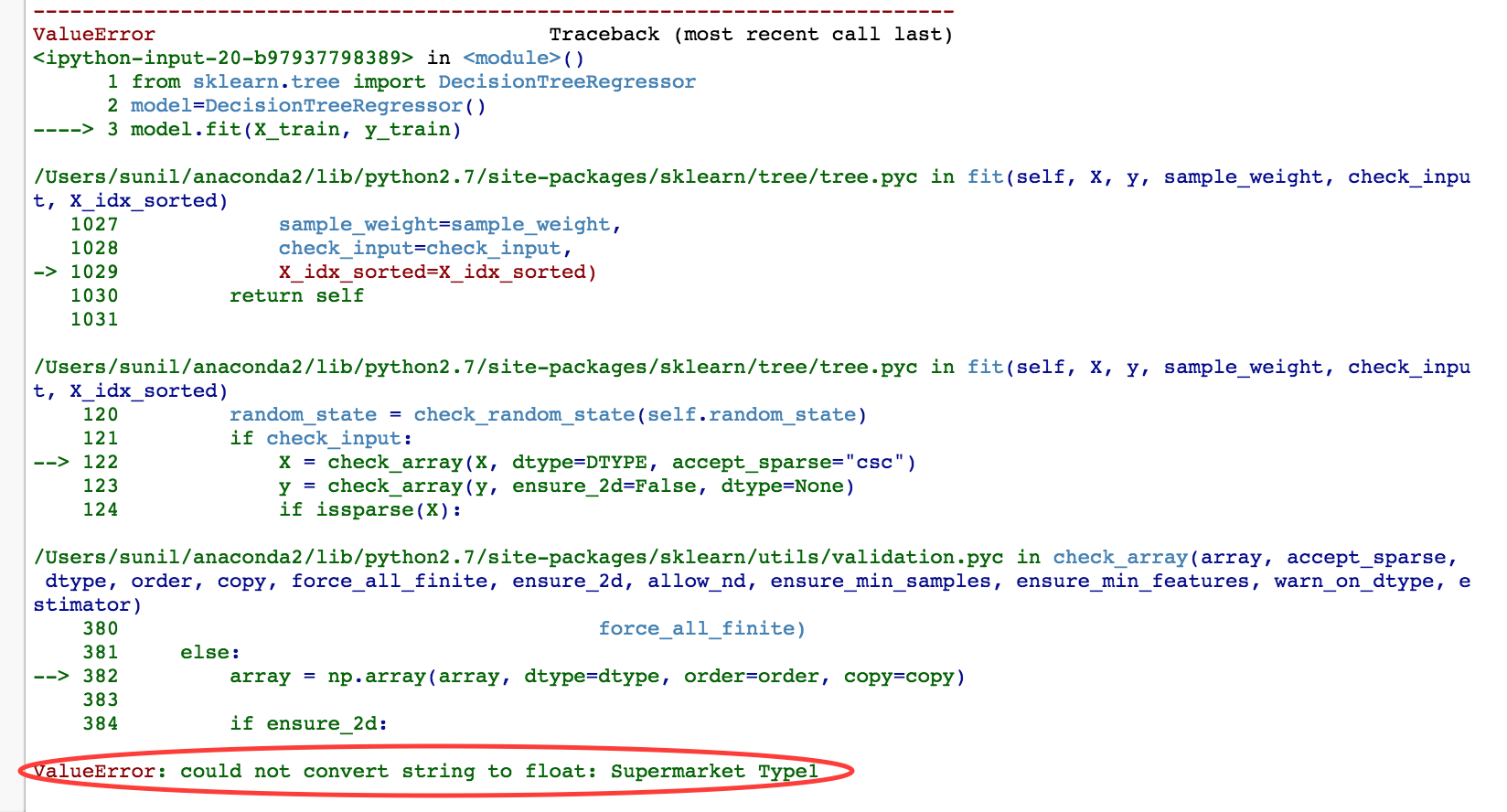
This error occurs when dealing with categorical (string) variables. In “sklearn”, you are required to convert these categories in the numerical format.
In order to do this conversion, we use several pre-processing methods like “label encoding”, “one hot encoding” and others.
This article discusses a recently open-sourced library ” CatBoost” developed and contributed by Yandex. As said by Mikhail Bilenko, Yandex’s head of machine intelligence and research, “This is the first Russian machine learning technology that’s an open source”! Pretty interesting right?
Tool – Pyhton
Level – Intermediate
Solving Multi-Label Classification problems (Case studies included)
If we consider the image below – does this image contain a house? The option will be YES or NO.
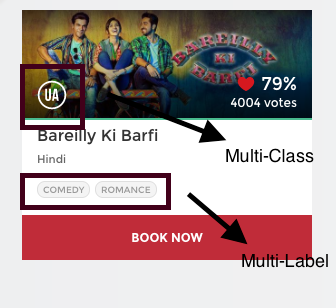
Consider another case, like what all things (or labels) are relevant to this picture?
These types of problems, where we have a set of target variables, are known as multi-label classification problems. This article explains in detail what this problem entails and how to deal with it in the form of case studies
Tool: Python
Level: Expert
Tutorial on Automated Machine Learning using MLBox

{kind=link}
As soon as the library was released on GitHub, many data scientists were extremely excited to try it out. In this article, we have talked about an automated machine learning library “MLBox”.
“MLBox is a powerful Automated Machine Learning Python library. It provides the following features:
- Fast reading and distributed data preprocessing/cleaning/formatting
- Highly robust feature selection and leak detection
- Accurate hyper-parameter optimisation in high-dimensional space
- State-of-the-art predictive models for classification and regression (Deep Learning, Stacking, LightGBM,…)
- Prediction with models interpretation“
The library automates the machine learning and feature engineering process itself. Just to give you an example, with just 8 lines of code – the creator of the library broke into top 1% of data science hackathon. This article gives you hands-on practice of the library MLBox.
Tool: Python
Level: Expert
End Notes
I hope you found the resources useful. Machine Learning is already helpful in solving many problems in different fields. I hope that we have been helpful on your journey to learn this year and we promise to do so in the coming year as well.
The Analytics Vidhya family wishes you Merry Christmas and very happy new year. May the new year bring the best of health, wealth and knowledge for you. In the meanwhile, if you have any suggestions / feedback, do share them with us. If you have any questions, feel free to drop your comments below.
Learn, engage , hack and get hired!
I am a perpetual, quick learner and keen to explore the realm of Data analytics and science. I am deeply excited about the times we live in and the rate at which data is being generated and being transformed as an asset. I am well versed with a few tools for dealing with data and also in the process of learning some other tools and knowledge required to exploit data.